Видобування даних з PDF-файлів за допомогою Python: Текст, посилання та зображення
Python, як багатофункціональна мова програмування, часто вимагає від розробників взаємодії з різними типами файлів, щоб отримати необхідну для обробки інформацію. Серед них PDF (Portable Document Format) є одним з найпоширеніших форматів, з яким доводиться працювати.
PDF-файли можуть включати текст, ілюстрації та гіперпосилання. У процесі обробки даних у Python може виникнути потреба в отриманні цих даних з PDF-документів. На відміну від, наприклад, кортежів, списків чи словників, видобування даних з PDF може здаватися складним.
На щастя, існує ряд бібліотек, що спрощують цю задачу. Давайте подивимося, як витягувати текст, посилання та зображення з PDF-файлів. Для цього вам знадобиться завантажити приклад PDF-файлу та зберегти його в тій же папці, де знаходиться ваш файл Python.
Видобування тексту з PDF-файлів
Для отримання тексту з PDF-документів за допомогою Python ми скористаємося бібліотекою PyPDF2. Це безкоштовна бібліотека з відкритим кодом, призначена для об’єднання, обрізання та перетворення PDF-сторінок. PyPDF2 також дозволяє додавати власні дані, параметри перегляду та паролі до PDF-файлів, а що найважливіше, видобувати з них текст.
Щоб використовувати PyPDF2, спочатку необхідно її встановити за допомогою pip, пакетного менеджера для Python.
Інструкція з встановлення pip:
- Перевірте, чи встановлено pip, виконавши в терміналі команду:
pip --version. Якщо версія не відображається, pip не встановлено. - Для встановлення pip перейдіть за посиланням get-pip.py та завантажте скрипт.
- Збережіть файл (за замовчуванням “get-pip.py”).
- Відкрийте термінал, перейдіть в каталог з завантаженим файлом та виконайте команду:
sudo python3 get-pip.py. Це встановить pip. - Щоб перевірити успішність встановлення, виконайте
pip --version. Якщо все гаразд, ви побачите номер версії.

Встановлення та використання PyPDF2:
- Встановіть PyPDF2, виконавши в терміналі:
pip install PyPDF2. - Створіть Python-файл та імпортуйте клас PdfReader:
from PyPDF2 import PdfReader. - Клас PdfReader дозволяє відкривати PDF-файли, читати їх вміст і видобувати текст.
- Для початку роботи з PDF-файлом, створіть екземпляр класу PdfReader, передавши йому назву PDF-файлу:
reader = PdfReader('games.pdf'). - Перевірте кількість сторінок у файлі:
print(len(reader.pages)). - Отримайте доступ до першої сторінки (індексація починається з 0):
page1 = reader.pages[0]. - Витягніть текст з першої сторінки:
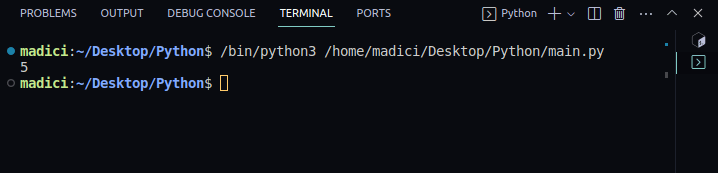
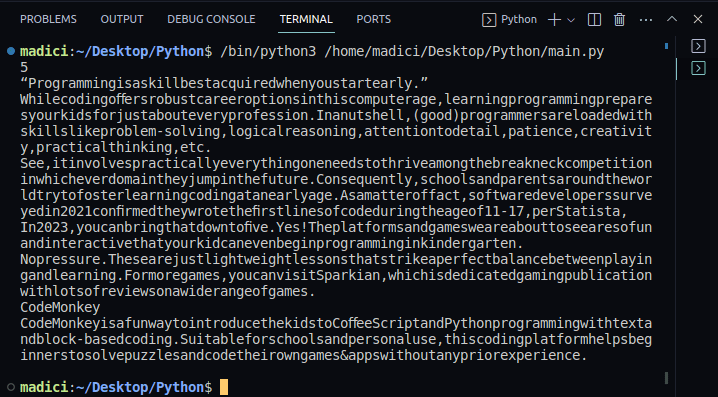
textPage1 = page1.extract_text(). - Надрукуйте витягнутий текст:
print(textPage1).
Вивід:
5
Повний код для видобування тексту:
# імпорт класу PdfReader з PyPDF2
from PyPDF2 import PdfReader
# створення екземпляра класу PdfReader
reader = PdfReader('games.pdf')
# отримання кількості сторінок у PDF-файлі
print(len(reader.pages))
# доступ до першої сторінки PDF
page1 = reader.pages[0]
# вилучення тексту з першої сторінки PDF-файлу
textPage1 = page1.extract_text()
# друк вилученого тексту
print(textPage1)
Вивід:
Видобування посилань з PDF-файлів
Для отримання посилань з PDF ми використаємо бібліотеку PyMuPDF. Вона призначена для вилучення, аналізу, перетворення та обробки даних, що зберігаються в документах PDF. PyMuPDF вимагає Python 3.8 або новішої версії.
- Встановіть PyMuPDF, виконавши в терміналі:
pip install PyMuPDF. - Імпортуйте бібліотеку в файл:
import fitz. - Відкрийте PDF-файл:
doc = fitz.open("games.pdf"). - Виведіть кількість сторінок:
print(doc.page_count). - Завантажте сторінку, з якої хочете отримати посилання (знову ж таки, нумерація починається з 0):
page = doc.load_page(0). - Витягніть посилання зі сторінки:
links = page.get_links(). - Подивіться на об’єкт links:
print(links). - Отримайте всі посилання з об’єкта links:
Вивід:
5
Вивід:
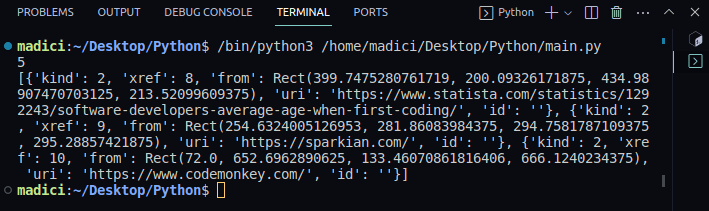
Зверніть увагу, що посилання зберігаються як список словників, де ключ ‘uri’ містить саме посилання.
import fitz
# відкриття PDF-файлу
doc = fitz.open("games.pdf")
# виведення кількості сторінок
print(doc.page_count)
# завантаження першої сторінки
page = doc.load_page(0)
# видобування посилань зі сторінки
links = page.get_links()
# виведення списку об'єктів links
#print(links)
# виведення фактичних посилань, які зберігаються під ключем "uri"
for obj in links:
print(obj["uri"])
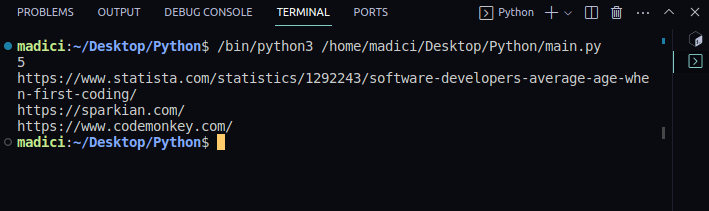
Вивід:
5
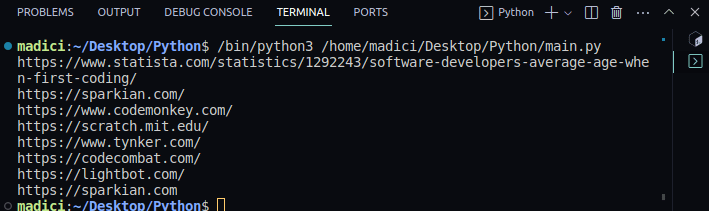
https://www.statista.com/statistics/1292243/software-developers-average-age-when-first-coding/
https://sparkian.com/
https://www.codemonkey.com/
Для зручності ми можемо об’єднати код у функції:
import fitz
# функція вилучення посилань з PDF-документу
def extract_link(path_to_pdf):
links = []
doc = fitz.open(path_to_pdf)
for page_num in range(doc.page_count):
page = doc.load_page(page_num)
page_links = page.get_links()
links.extend(page_links)
return links
# функція для виводу посилань, отриманих з PDF-документу
def print_all_links(links):
for link in links:
print(link["uri"])
# виклик функції для вилучення всіх посилань
all_links = extract_link("games.pdf")
# виклик функції для виведення всіх посилань
print_all_links(all_links)
Вивід:
https://www.statista.com/statistics/1292243/software-developers-average-age-when-first-coding/
https://sparkian.com/
https://www.codemonkey.com/
https://scratch.mit.edu/
https://www.tynker.com/
https://codecombat.com/
https://lightbot.com/
https://sparkian.com
Видобування зображень з PDF-файлів
Для видобування зображень з PDF ми знову скористаємось бібліотекою PyMuPDF, а також бібліотеками io та PIL.
- Імпортуйте необхідні бібліотеки:
import fitz from io import BytesIO from PIL import Image - Відкрийте PDF-файл:
doc = fitz.open("games.pdf"). - Завантажте сторінку:
page = doc.load_page(0). - Отримайте перехресні посилання (xref) на зображення:
image_xref = page.get_images(); print(image_xref). - Отримайте значення xref:
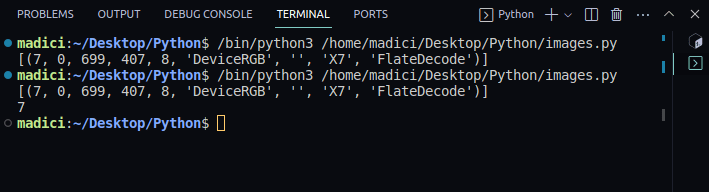
xref_value = image_xref[0][0]; print(xref_value). - Витягніть зображення:
img_dictionary = doc.extract_image(xref_value). - Отримайте розширення файлу зображення:
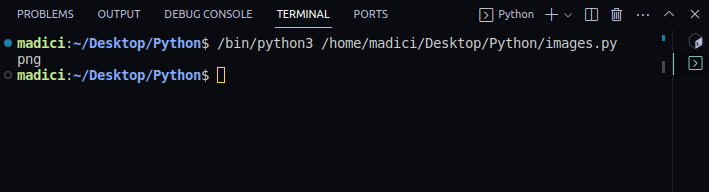
img_extension = img_dictionary["ext"]; print(img_extension). - Отримайте бінарні файли зображення:
img_binary = img_dictionary["image"]. - Створіть об’єкт BytesIO та ініціалізуйте його бінарними даними зображення:
image_io = BytesIO(img_binary). - Відкрийте зображення за допомогою PIL:
image = Image.open(image_io). - Вкажіть шлях збереження зображення:
output_path = "image_1.png". - Збережіть зображення та закрийте об’єкт BytesIO:
image.save(output_path); image_io.close().
Вивід:
[(7, 0, 699, 407, 8, 'DeviceRGB', '', 'X7', 'FlateDecode')]
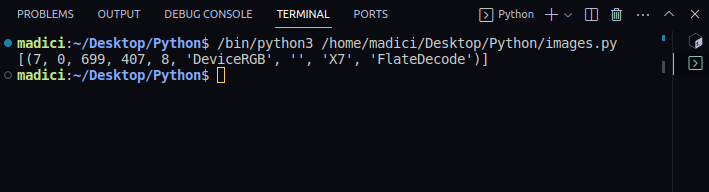
Функція get_images() повертає список кортежів, де перший елемент кортежу – це перехресне посилання на зображення.
Вивід:
[(7, 0, 699, 407, 8, 'DeviceRGB', '', 'X7', 'FlateDecode')] 7
Ця функція повертає словник з бінарними даними зображення та його метаданими.
Вивід:
png
Повний код:
import fitz
from io import BytesIO
from PIL import Image
doc = fitz.open("games.pdf")
page = doc.load_page(0)
# отримуємо перехресне посилання на зображення
image_xref = page.get_images()
# отримуємо значення xref
xref_value = image_xref[0][0]
# видобуваємо зображення
img_dictionary = doc.extract_image(xref_value)
# отримуємо розширення файлу
img_extension = img_dictionary["ext"]
# отримуємо бінарні файли зображення
img_binary = img_dictionary["image"]
# створюємо об'єкт BytesIO для роботи з байтами зображення
image_io = BytesIO(img_binary)
# відкриваємо зображення за допомогою PIL
image = Image.open(image_io)
# вказуємо шлях, куди треба зберегти зображення
output_path = "image_1.png"
# зберігаємо зображення
image.save(output_path)
# закриваємо об'єкт BytesIO
image_io.close()
Після запуску коду в тій же папці, де і файл Python, ви побачите витягнуте зображення під назвою “image_1.png”.
Висновок
Для поглиблення навичок з видобування посилань, зображень і тексту з PDF-файлів, спробуйте реорганізувати код, щоб зробити його більш універсальним, як показано у прикладі з посиланнями. Завдяки цьому вам потрібно буде лише передати PDF-файл, і ваша програма Python витягне всі посилання, зображення або текст з усього файлу. Щасливого кодування!
Ви також можете ознайомитися з деякими найкращими PDF API для будь-яких бізнес-потреб.