Reddit пропонує JSON-канали для кожного сабреддіту. Розглянемо, як створити скрипт Bash, котрий завантажує і аналізує перелік публікацій з будь-якого цікавого вам сабреддіту. Це лише один з прикладів використання JSON-каналів Reddit.
Встановлення Curl та JQ
Для отримання JSON-каналу з Reddit ми будемо використовувати curl, а jq — для аналізу JSON-даних та вилучення потрібних полів. Встановіть ці два інструменти за допомогою apt-get в Ubuntu та інших дистрибутивах Linux на базі Debian. Якщо у вас інший дистрибутив Linux, скористайтеся інструментом керування пакетами вашої системи.
sudo apt-get install curl jq
Отримання JSON-даних з Reddit
Подивимось, як виглядає канал даних. За допомогою curl отримаємо останні повідомлення з сабреддіту “Помірно Цікаво”:
curl -s -A "приклад скрейпера reddit" https://www.reddit.com/r/MildlyInteresting.json
Зверніть увагу на параметри перед URL-адресою: -s змушує curl працювати в тихому режимі, тому ми бачимо лише дані з серверів Reddit. Параметр -A “приклад скрейпера reddit” встановлює спеціальний рядок агента користувача, який дозволяє Reddit ідентифікувати програму, що звертається до їхніх даних. API Reddit застосовує обмеження швидкості на основі рядка агента користувача. Встановлення спеціального значення дозволить Reddit відокремити наш ліміт швидкості від інших користувачів, що зменшить ймовірність отримання помилки HTTP 429 “Перевищено ліміт запитів”.
Результат має заповнити вікно терміналу і виглядати приблизно так:
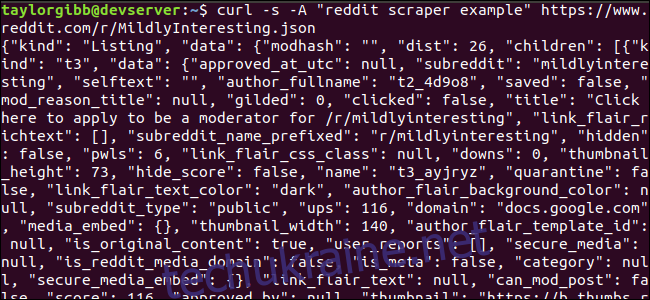
У вихідних даних є багато полів, але нам потрібні лише назва, постійне посилання та URL. Повний перелік типів та їх полів можна знайти в документації API Reddit: https://github.com/reddit-archive/reddit/wiki/JSON
Вилучення даних з JSON-виводу
Нам потрібно витягти назву, постійне посилання та URL з вихідних даних і зберегти їх у файл, розділений табуляцією. Можна скористатися інструментами обробки тексту, такими як sed і grep, але є спеціальний інструмент для роботи зі структурою JSON – jq. Для початку, давайте використаємо його для форматування виводу та розфарбування результату. Застосуємо той самий виклик, що й раніше, але цього разу передамо результат через jq для аналізу та друку JSON-даних.
curl -s -A "приклад скрейпера reddit" https://www.reddit.com/r/MildlyInteresting.json | jq .
Зверніть увагу на крапку після команди. Цей вираз просто аналізує вхідні дані і друкує їх як є. Результат виглядає відформатованим та кольоровим:
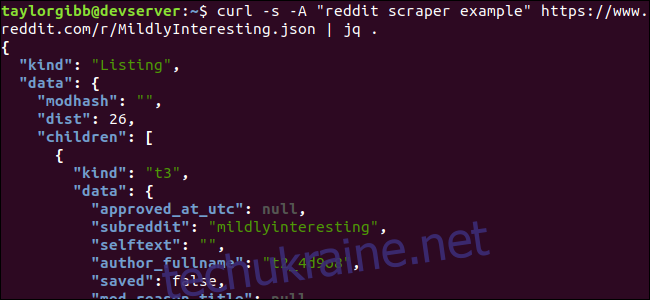
Розглянемо структуру JSON-даних, що надходять з Reddit. Кореневим результатом є об’єкт з двома властивостями: “тип” та “дані”. Остання властивість містить поле “діти”, де знаходиться масив публікацій у сабреддіті.
Кожен елемент масиву є об’єктом, який також має два поля: “тип” і “дані”. Потрібні нам властивості розміщені всередині об’єкту “дані”. jq очікує вираз, який застосовується до вхідних даних та повертає потрібний результат. Цей вираз описує ієрархію та належність до масиву, а також спосіб перетворення даних. Знову запустимо всю команду з правильним виразом:
curl -s -A "приклад скрейпера reddit" https://www.reddit.com/r/MildlyInteresting.json | jq '.data.children | .[] | .data.title, .data.url, .data.permalink'
Вивід показує назву, URL-адресу та постійне посилання, кожне в окремому рядку:
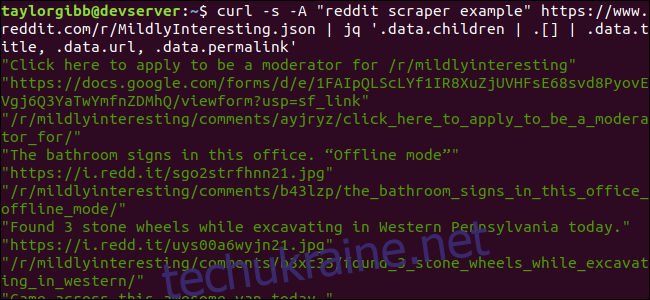
Розберемо команду jq, що ми викликали:
jq '.data.children | .[] | .data.title, .data.url, .data.permalink'
В цій команді три вирази, розділені символами вертикальної лінії. Результати кожного виразу передаються наступному для подальшої обробки. Перший вираз відфільтровує все, окрім масиву списків Reddit. Вивід цього виразу передається у другий вираз і примусово перетворюється на масив. Третій вираз працює з кожним елементом масиву і витягує три необхідні властивості. Детальнішу інформацію про jq та його синтаксис можна знайти в офіційному посібнику jq.
Об’єднання в скрипт
Об’єднаємо виклик API та постобробку JSON у скрипт, котрий створить файл з необхідними повідомленнями. Додамо підтримку для отримання публікацій з будь-якого сабреддіту, а не лише з /r/MildlyInteresting.
Відкрийте текстовий редактор та скопіюйте цей фрагмент у файл під назвою scrape-reddit.sh:
#!/bin/bash
if [ -z "$1" ]
then
echo "Вкажіть сабреддіт"
exit 1
fi
SUBREDDIT=$1
NOW=$(date +"%m_%d_%y-%H_%M")
OUTPUT_FILE="${SUBREDDIT}_${NOW}.txt"
curl -s -A "bash-scrape-topics" https://www.reddit.com/r/${SUBREDDIT}.json |
jq '.data.children | .[] | .data.title, .data.url, .data.permalink' |
while read -r TITLE; do
read -r URL
read -r PERMALINK
echo -e "${TITLE}\t${URL}\t${PERMALINK}" | tr --delete "\"" >> ${OUTPUT_FILE}
done
Цей скрипт спочатку перевіряє, чи ввів користувач ім’я сабреддіту. Якщо ні, то він завершується з повідомленням про помилку і ненульовим кодом повернення.
Потім скрипт зберігає перший аргумент як ім’я сабреддіту та створює ім’я файлу з датою, куди будуть збережені результати.
Дія починається з виклику curl з спеціальним заголовком та URL сабреддіту. Вивід передається до jq, де він аналізується і зводиться до трьох полів: заголовок, URL та постійне посилання. Ці рядки читаються по черзі та зберігаються у змінній за допомогою команди read, все це всередині циклу while, що триватиме, доки не буде більше рядків для читання. Останній рядок внутрішнього блоку while повторює три поля, розділені символом табуляції, та передає його через команду tr для видалення подвійних лапок. Потім результат додається до файлу.
Перш ніж запустити цей скрипт, переконайтеся, що у нього є права на виконання. Застосуйте ці права до файлу за допомогою команди chmod:
chmod u+x scrape-reddit.sh
Нарешті, запустіть скрипт з іменем сабреддіту:
./scrape-reddit.sh MildlyInteresting
Створений вихідний файл буде знаходитись в тому самому каталозі, і його вміст виглядатиме так:
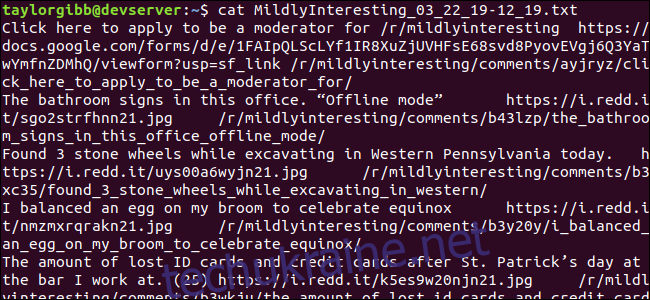
Кожен рядок містить три поля, розділені символом табуляції.
Подальші дії
Reddit – це величезне джерело цікавого контенту та медіа, і доступ до нього можна легко отримати за допомогою JSON API. Тепер, коли ви вмієте отримувати ці дані та обробляти результати, ви можете:
- Отримувати останні заголовки з /r/WorldNews і надсилати їх на робочий стіл за допомогою notify-send
- Інтегрувати кращі жарти з /r/DadJokes у систему Message-Of-The-Day
- Зробити найкраще зображення дня з /r/aww фоном робочого столу
Все це можливо за допомогою наданих даних та інструментів, які є у вашій системі. Щасливого програмування!