Інструмент командного рядка Linux uniq аналізує текстові файли, виявляючи рядки, що повторюються або є унікальними. Цей посібник розкриє вам усі можливості та тонкощі цієї потужної утиліти, показуючи, як ефективно використовувати її у своїй роботі.
Аналіз рядків тексту за допомогою команди uniq в Linux
Команда uniq – це ефективний, гнучкий та точний інструмент. Проте, як і більшість команд Linux, вона має свої особливості, які потрібно знати для ефективного використання. Без розуміння цих нюансів, ви можете зіткнутися з несподіваними результатами. Ми будемо акцентувати увагу на цих особливостях протягом нашого огляду.
uniq чудово підходить для виконання конкретних задач. Вона особливо корисна при роботі з конвеєрами команд, де вона відіграє важливу роль. Одним з її найчастіших партнерів є команда sort, оскільки uniq вимагає відсортованих вхідних даних для правильної роботи.
Отже, давайте розпочнемо!
Запуск команди uniq без параметрів
У нас є текстовий файл, що містить текст пісні Роберта Джонсона під назвою “Я вірю, що я змахну свою мітлу”. Подивимось, як uniq працює з цим файлом.
Щоб передати вивід команди в less, введіть наступне:
uniq dust-my-broom.txt | less

Результат – весь текст пісні, включаючи рядки, що повторюються.
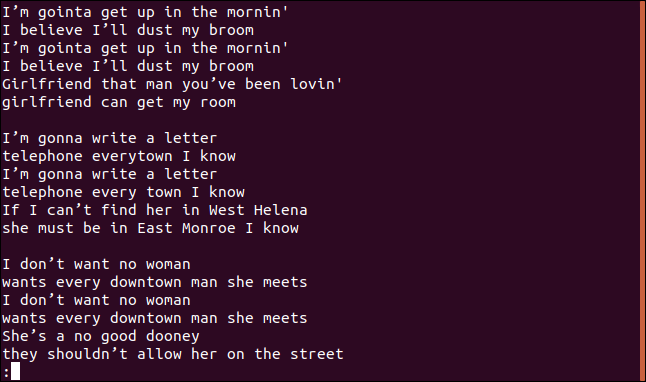
На перший погляд, це не відображення унікальних або повторюваних рядків.
Саме тут виявляється перша особливість uniq. Без вказання параметрів, вона працює так, ніби ви використовуєте опцію -u (унікальні рядки), тобто показує лише унікальні рядки з файлу. Причина, чому ви бачите повторювані рядки, полягає в тому, що uniq розпізнає дублікати тільки якщо вони є сусідніми. Ось тут і потрібне сортування.
Сортуючи файл, ми групуємо повторювані рядки, що дозволяє uniq ідентифікувати їх як дублікати. Використаємо sort для сортування, передамо результат uniq, а потім виведемо все це через less.
Для цього введіть:
sort dust-my-broom.txt | uniq | less

Тепер у less відображено відсортований список рядків.
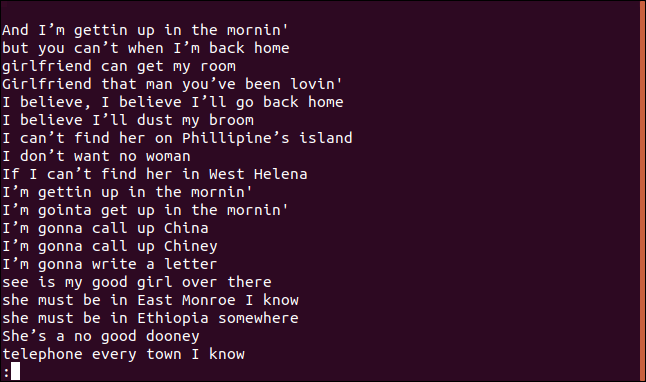
Рядок “Я вірю, що я змахну свою мітлу” дійсно неодноразово зустрічається в пісні. Насправді, він повторюється двічі в перших чотирьох рядках.
Чому ж він з’явився у списку унікальних рядків? Тому що перше входження рядка у файлі є унікальним, а всі наступні входження вважаються дублікатами. Іншими словами, uniq показує перше входження кожного унікального рядка.
Давайте ще раз використаємо sort і перенаправимо вивід в новий файл, щоб не сортувати файл при кожному запуску команди.
Введіть команду:
sort dust-my-broom.txt > sorted.txt

Тепер у нас є попередньо відсортований файл для подальшої роботи.
Підрахунок дублікатів
За допомогою параметра -c (лічильник) ви можете вивести кількість разів, коли кожен рядок з’являється у файлі.
Введіть:
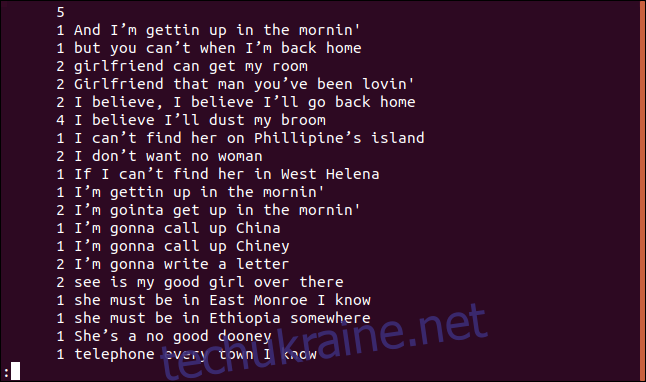
uniq -c sorted.txt | less

Кожен рядок починається з числа, що показує кількість його повторень у файлі. Зверніть увагу, що перший рядок є порожнім. Це означає, що у файлі є п’ять порожніх рядків.
Щоб відсортувати вихідні дані за кількістю повторень, можна передати вивід uniq команді sort з параметрами -r (зворотній порядок) та -n (числове сортування), а потім вивести результат через less.
Введіть:
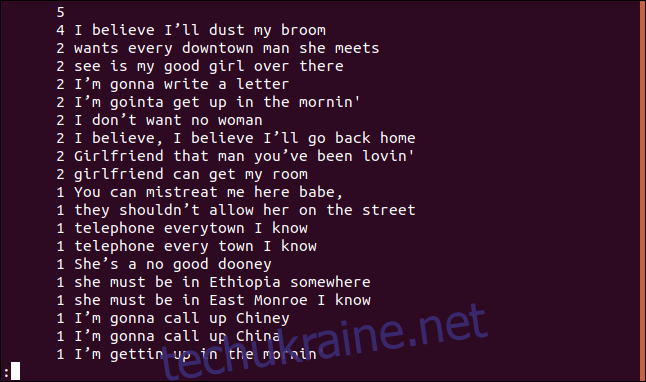
uniq -c sorted.txt | sort -rn | less

Тепер список відсортовано в порядку спадання за частотою появи кожного рядка.
Виведення лише рядків, що повторюються
Якщо вам потрібні лише рядки, які зустрічаються у файлі більше одного разу, використовуйте параметр -d (повторення). Незалежно від кількості дублікатів рядка, він буде виведений лише один раз.
Щоб скористатись цією опцією, введіть:
uniq -d sorted.txt

Ви отримаєте список рядків, які дублюються. Порожній рядок на початку означає, що у файлі є повторювані порожні рядки.
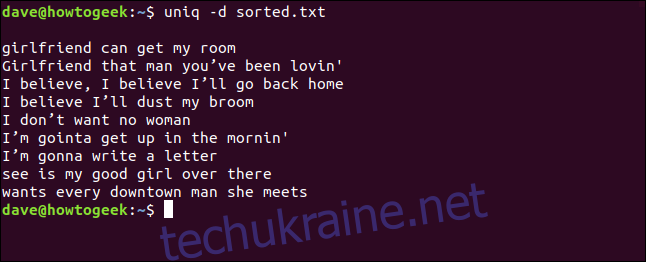
Можна об’єднати параметри -d (повторення) і -c (підрахунок) та відсортувати результат. Це дасть нам відсортований список рядків, що з’являються хоча б двічі.
Введіть команду:
uniq -d -c sorted.txt | sort -rn
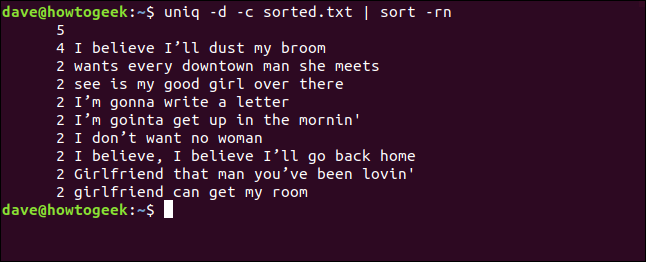
Виведення всіх рядків, що повторюються
Якщо потрібно вивести кожен рядок, що повторюється, та кожне його входження у файлі, використовуйте параметр -D (всі повторювані рядки).
Введіть:
uniq -D sorted.txt | less

Результатом буде список, де кожен повторюваний рядок виводиться стільки разів, скільки він зустрічається у файлі.
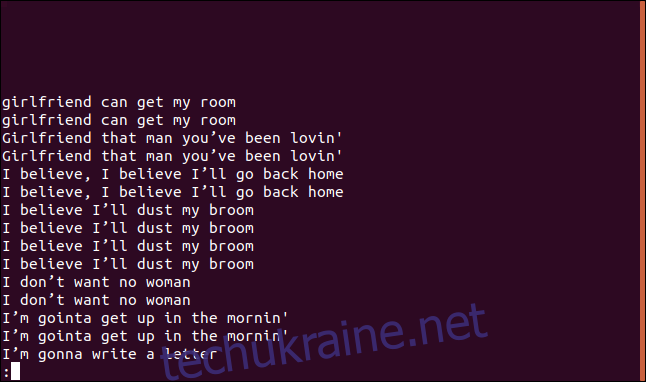
За допомогою параметра --group можна вивести кожен дублікат рядка з порожнім рядком перед (prepend), після (append) або і перед, і після (both) кожної групи.
Використаємо append, для цього введіть:
uniq --group=append sorted.txt | less

Групи розділені порожніми рядками для зручнішого читання.
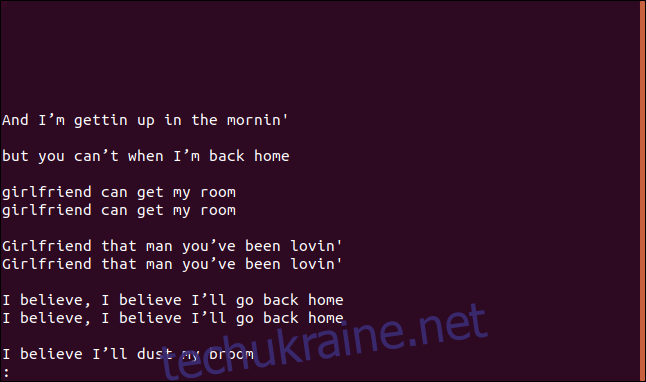
Перевірка певної кількості символів
За замовчуванням uniq перевіряє весь рядок. Щоб обмежити перевірку певною кількістю символів, використовуйте параметр -w (кількість символів для перевірки).
Повторимо останню команду, але обмежимо порівняння першими трьома символами. Для цього введіть:
uniq -w 3 --group=append sorted.txt | less

Результат і групи будуть відрізнятися від попереднього.
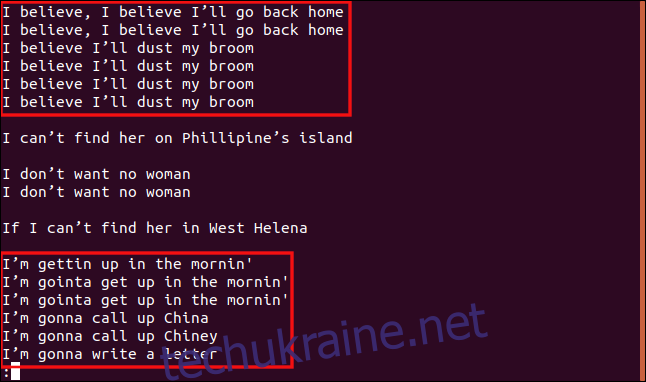
Усі рядки, що починаються з “I b”, згруповані разом, оскільки ця їхня частина ідентична і розглядається як повторення.
Аналогічно, всі рядки, що починаються з “Я”, вважаються повторюваними, навіть якщо решта тексту різниться.
Ігнорування певної кількості символів
Іноді корисно пропускати певну кількість символів на початку кожного рядка. Наприклад, коли рядки у файлі пронумеровані. Або, скажімо, потрібно, щоб uniq почав перевірку рядка з шостого символу, ігноруючи перші п’ять символів.
Нижче показано наш відсортований файл із пронумерованими рядками.
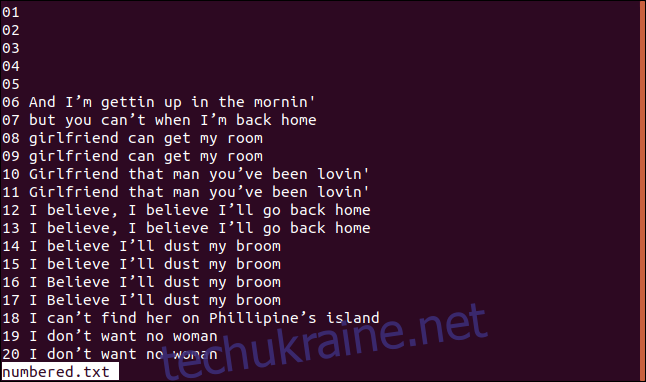
Щоб uniq почав перевірку з третього символу, використаємо параметр -s (пропустити символи), ввівши:
uniq -s 3 -d -c numbered.txt
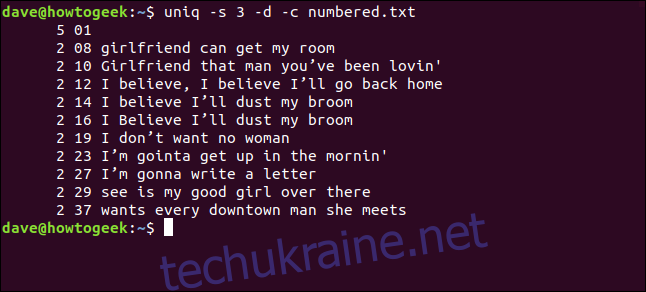
Рядки визначені як повторювані, і їхні входження підраховано правильно. Зверніть увагу, що номери рядків відображають номери першого входження кожного дубліката.
Також можна пропускати поля (набір символів і пробілів) замість символів. Використаємо параметр -f (поля), щоб вказати uniq, які поля ігнорувати.
Щоб uniq ігнорував перше поле, введіть:
uniq -f 1 -d -c numbered.txt
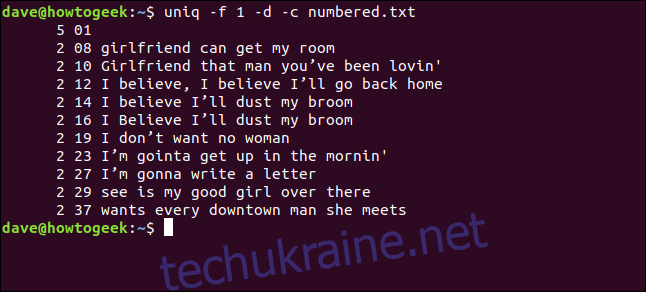
Ми отримали ті самі результати, що й коли сказали uniq пропускати три символи на початку кожного рядка.
Ігнорування регістру
За замовчуванням uniq розрізняє регістр. Рядки, що відрізняються лише регістром букв, вважаються різними.
Наприклад, розглянемо результат наступної команди:
uniq -d -c sorted.txt | sort -rn
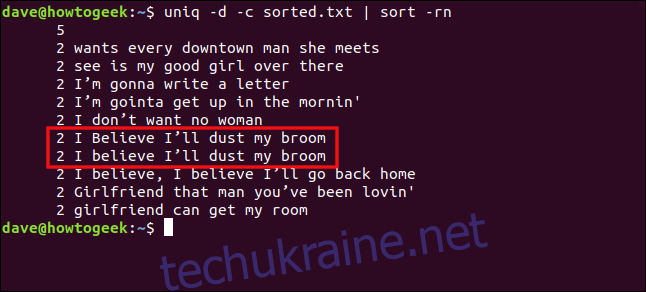
Рядки “Я вірю, що я змахну свою мітлу” та “Я вірю, що притрушу свою мітлу” не розглядаються як повторювані через різницю в регістрі букви “В” у слові “вірю”.
Проте, якщо ми використаємо параметр -i (ігнорувати регістр), ці рядки будуть вважатися повторюваними. Введіть:
uniq -d -c -i sorted.txt | sort -rn
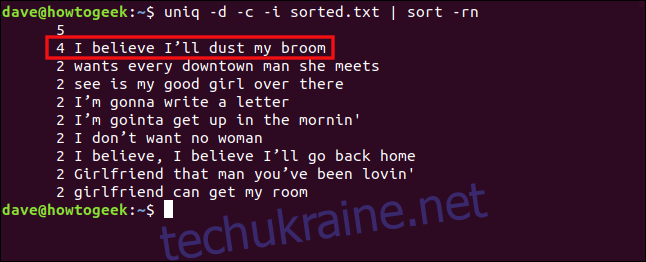
Тепер рядки розглядаються як повторювані і згруповані.
Linux пропонує безліч спеціальних утиліт. uniq, як і багато з них, не є інструментом щоденного використання.
Саме тому досвід роботи з Linux полягає у вмінні запам’ятовувати, який інструмент вирішить поточну проблему та де його можна знайти. Якщо ви будете практикуватися, то досягнете успіху.
Або ж ви завжди можете звернутися до нашого сайту, де, можливо, є стаття на цю тему.