
Дізнайтеся все, що вам потрібно знати про дослідницький аналіз даних, важливий процес, який використовується для виявлення тенденцій і закономірностей і узагальнення наборів даних за допомогою статистичних підсумків і графічних зображень.
Як і будь-який інший проект, науковий проект даних — це тривалий процес, який вимагає часу, гарної організації та ретельного виконання кількох етапів. Дослідницький аналіз даних (EDA) є одним із найважливіших кроків у цьому процесі.
Тому в цій статті ми коротко розглянемо, що таке пошуковий аналіз даних і як його можна виконати за допомогою R!
Що таке пошуковий аналіз даних?
Дослідницький аналіз даних перевіряє та вивчає характеристики набору даних перед тим, як його надіслати в програму, незалежно від того, чи це виключно бізнес, статистика чи машинне навчання.
Цей короткий опис характеру інформації та її основних особливостей зазвичай робиться візуальними методами, такими як графічні зображення та таблиці. Практика проводиться заздалегідь саме для того, щоб оцінити потенціал цих даних, які в майбутньому отримають більш складну обробку.
Тому EDA дозволяє:
- Сформулювати гіпотези використання цієї інформації;
- Досліджуйте приховані деталі в структурі даних;
- Визначте відсутні значення, викиди або ненормальну поведінку;
- Виявляти тенденції та відповідні змінні в цілому;
- Відкинути нерелевантні змінні або змінні, корельовані з іншими;
- Визначте формальне моделювання, яке буде використано.
Яка різниця між описовим і дослідницьким аналізом даних?
Існує два типи аналізу даних: описовий аналіз і пошуковий аналіз даних, які йдуть рука об руку, незважаючи на різні цілі.
У той час як перший фокусується на описі поведінки змінних, наприклад, середнього значення, медіани, моди тощо.
Дослідницький аналіз спрямований на виявлення зв’язків між змінними, отримання попередньої інформації та спрямування моделювання на найпоширеніші парадигми машинного навчання: класифікація, регресія та кластеризація.
Загалом обидва можуть мати справу з графічним представленням; однак лише дослідницький аналіз прагне привнести практичні ідеї, тобто ідеї, які спонукають до дій особи, яка приймає рішення.
Нарешті, у той час як дослідницький аналіз даних спрямований на вирішення проблем і надання рішень, які керуватимуть етапами моделювання, описовий аналіз, як випливає з його назви, спрямований лише на створення детального опису даного набору даних.
Описовий аналізДослідницький аналіз даних Аналізує поведінку Аналізує поведінку та взаємозв’язки Надає резюме Веде до специфікації та дій Організовує дані в таблицях і графікахУпорядковує дані в таблицях і графікахНе має значної пояснювальної сили Має значну пояснювальну силу
Деякі приклади практичного використання EDA
#1. Цифровий маркетинг
Цифровий маркетинг перетворився з творчого процесу на процес, керований даними. Маркетингові організації використовують пошуковий аналіз даних, щоб визначити результати кампаній або зусиль, а також керувати споживачами інвестиціями та рішеннями щодо цільового призначення.
Демографічні дослідження, сегментація споживачів та інші методи дозволяють маркетологам використовувати великі обсяги споживчих покупок, опитувань і панельних даних для розуміння та передачі маркетингової стратегії.
Веб-аналітика дозволяє маркетологам збирати інформацію про взаємодію на веб-сайті на рівні сеансу. Google Analytics є прикладом безкоштовного та популярного інструменту аналітики, який маркетологи використовують для цієї мети.
До дослідницьких методів, які часто використовуються в маркетингу, входять моделювання комплексу маркетингу, аналіз ціноутворення та просування, оптимізація продажів і дослідницький аналіз клієнтів, наприклад, сегментація.
#2. Розвідковий аналіз портфоліо
Поширеним застосуванням пошукового аналізу даних є пошуковий аналіз портфеля. Банк або кредитна агенція має колекцію рахунків різної вартості та ризику.
Облікові записи можуть відрізнятися залежно від соціального статусу власника (багатий, середній клас, бідний тощо), географічного розташування, власного капіталу та багатьох інших факторів. Позикодавець повинен збалансувати прибутковість позики з ризиком непогашення для кожної позики. Тоді виникає питання, як оцінити портфель у цілому.
Позика з найменшим ризиком може бути для дуже заможних людей, але є дуже обмежена кількість заможних людей. З іншого боку, багато бідних людей можуть позичати, але з більшим ризиком.
Рішення для дослідницького аналізу даних може поєднувати аналіз часових рядів із багатьма іншими проблемами, щоб вирішити, коли позичати гроші цим різним сегментам позичальників або ставку кредитування. Відсотки нараховуються учасникам сегмента портфеля для покриття збитків серед учасників цього сегмента.
#3. Дослідницький аналіз ризиків
Прогностичні моделі в банківській справі розробляються, щоб забезпечити впевненість щодо показників ризику для окремих клієнтів. Кредитні оцінки призначені для прогнозування правопорушної поведінки особи та широко використовуються для оцінки кредитоспроможності кожного заявника.
Крім того, аналіз ризиків проводиться в науковому світі та страховій галузі. Він також широко використовується у фінансових установах, таких як компанії-шлюзи онлайн-платежів, щоб аналізувати, чи є транзакція справжньою чи шахрайською.
Для цього вони використовують історію транзакцій клієнта. Він частіше використовується для покупок кредитною карткою; коли відбувається раптовий сплеск обсягу транзакцій клієнта, клієнт отримує виклик підтвердження, якщо він ініціював транзакцію. Це також допомагає зменшити втрати через такі обставини.
Дослідницький аналіз даних за допомогою R
Перше, що вам потрібно виконати EDA за допомогою R, це завантажити базу R та R Studio (IDE), а потім встановити та завантажити такі пакети:
#Installing Packages
install.packages("dplyr")
install.packages("ggplot2")
install.packages("magrittr")
install.packages("tsibble")
install.packages("forecast")
install.packages("skimr")
#Loading Packages
library(dplyr)
library(ggplot2)
library(magrittr)
library(tsibble)
library(forecast)
library(skimr)
У цьому підручнику ми будемо використовувати набір економічних даних, вбудований у R, який надає щорічні дані про економічні показники економіки США, і для спрощення змінимо його назву на econ:
econ <- ggplot2::economics
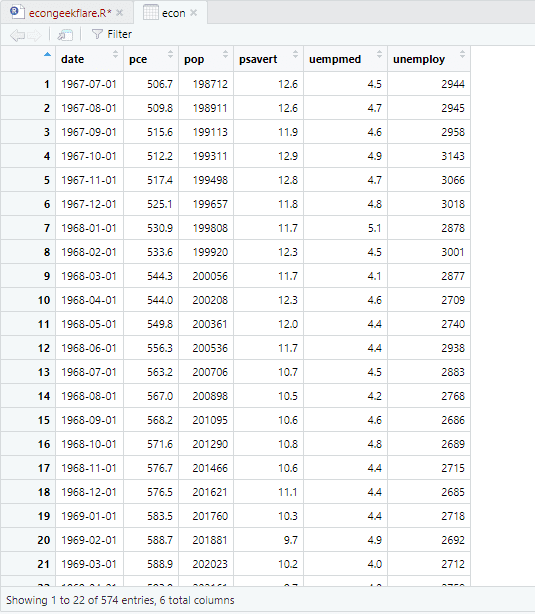
Для виконання описового аналізу ми будемо використовувати пакет skimr, який обчислює цю статистику простим і добре представленим способом:
#Descriptive Analysis skimr::skim(econ)

Ви також можете використовувати функцію підсумку для описового аналізу:
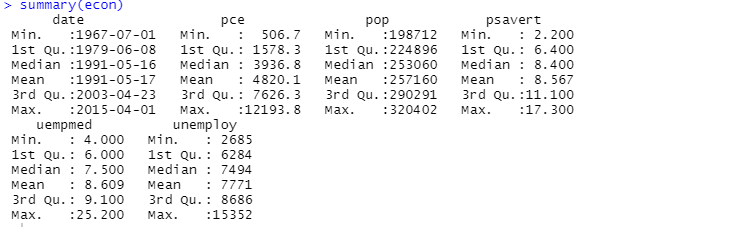
Тут описовий аналіз показує 547 рядків і 6 стовпців у наборі даних. Мінімальне значення припадає на 1967-07-01, а максимальне – на 2015-04-01. Подібним чином він також показує середнє значення та стандартне відхилення.
Тепер ви маєте базове уявлення про те, що знаходиться всередині набору даних econ. Давайте побудуємо гістограму змінної uempmed, щоб краще побачити дані:
#Histogram of Unemployment econ %>% ggplot2::ggplot() + ggplot2::aes(x = uempmed) + ggplot2::geom_histogram() + labs(x = "Unemployment", title = "Monthly Unemployment Rate in US between 1967 to 2015")
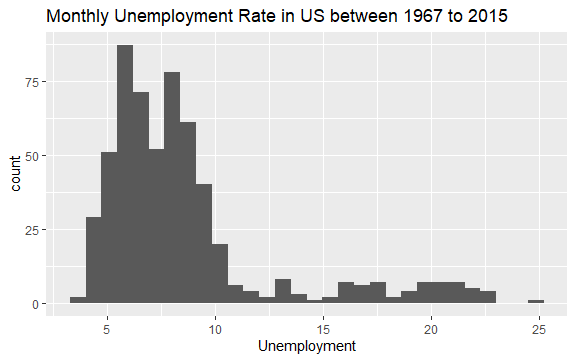
Розподіл гістограми показує, що вона має подовжений хвіст справа; тобто, можливо, існує декілька спостережень цієї змінної з більш «екстремальними» значеннями. Виникає питання: в який період мали місце ці значення, і який тренд змінної?
Найпряміший спосіб визначити тенденцію змінної – це лінійний графік. Нижче ми створюємо лінійний графік і додаємо лінію згладжування:
#Line Graph of Unemployment econ %>% ggplot2::autoplot(uempmed) + ggplot2::geom_smooth()
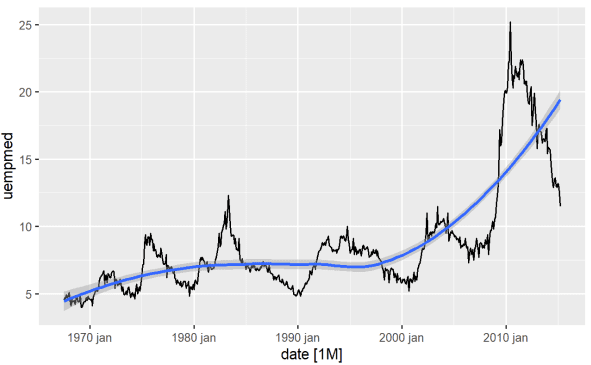
Використовуючи цей графік, ми можемо визначити, що в останній період, в останніх спостереженнях з 2010 року, існує тенденція до зростання безробіття, що перевищує історію, що спостерігалася в попередні десятиліття.
Іншим важливим моментом, особливо в контексті економетричного моделювання, є стаціонарність ряду; тобто середнє значення та дисперсія постійні з часом?
Якщо ці припущення щодо змінної не відповідають дійсності, ми говоримо, що ряд має одиничний корінь (нестаціонарний), тому шоки, яких зазнає змінна, створюють постійний ефект.
Здається, це було у випадку змінної, про яку йде мова, тривалості безробіття. Ми бачили, що коливання змінної істотно змінилися, що має серйозні наслідки, пов’язані з економічними теоріями, які мають справу з циклами. Але, відходячи від теорії, як ми практично перевіримо, чи змінна є стаціонарною?
Пакет прогнозів має чудову функцію, що дозволяє застосовувати тести, такі як ADF, KPSS та інші, які вже повертають кількість різниць, необхідну для того, щоб ряд був стаціонарним:
#Using ADF test for checking stationarity forecast::ndiffs( x = econ$uempmed, test = "adf")

Тут p-значення більше 0,05 показує, що дані є нестаціонарними.
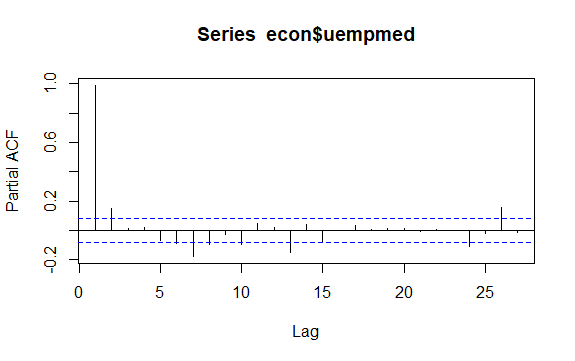
Іншим важливим питанням у часових рядах є ідентифікація можливих кореляцій (лінійної залежності) між значеннями ряду з відставанням. Ідентифікувати його допомагають корелограми ACF і PACF.
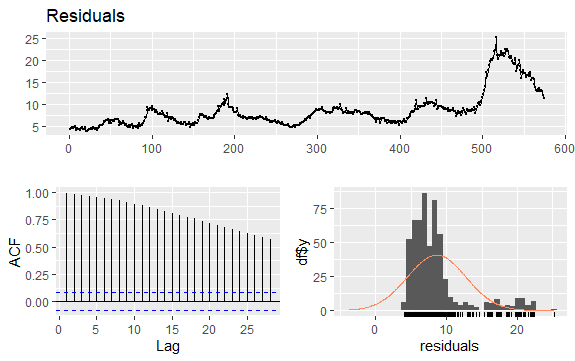
Оскільки ряд не має сезонності, але має певну тенденцію, початкові автокореляції мають тенденцію бути великими та позитивними, оскільки спостереження, близькі за часом, також близькі за значенням.
Таким чином, автокореляційна функція (ACF) тенденційного часового ряду має тенденцію мати позитивні значення, які повільно зменшуються зі збільшенням лагів.
#Residuals of Unemployment checkresiduals(econ$uempmed) pacf(econ$uempmed)
Висновок
Коли ми отримуємо в руки більш-менш чисті, тобто вже очищені дані, у нас відразу виникає спокуса зануритися в етап побудови моделі, щоб отримати перші результати. Ви маєте протистояти цій спокусі та розпочати дослідницький аналіз даних, який є простим, але допомагає нам отримати потужне розуміння даних.
Ви також можете дослідити деякі найкращі ресурси, щоб дізнатися статистику для Data Science.