У минулому, коли локальні Unix-сервери з великими файловими системами були звичною практикою, організації розробляли розгалужені системи управління каталогами та підходи до адміністрування прав доступу до різних папок для різноманітних користувачів.
Зазвичай, платформа компанії обслуговує різні категорії користувачів з абсолютно різними потребами, обмеженнями щодо конфіденційності чи типами контенту. У випадку глобальних корпорацій це навіть може включати поділ контенту за географічним розташуванням, тобто між користувачами з різних країн.
Інші типові приклади:
- Розподіл даних між середовищами розробки, тестування та продакшну.
- Комерційний контент, недоступний для широкого загалу.
- Специфічний для країни юридичний контент, який не можна переглядати або отримувати доступ з інших регіонів.
- Матеріали, пов’язані з проєктами, де «керівні дані» мають надаватися лише обмеженій групі осіб.
Перелік таких випадків є потенційно безмежним. Суть у тому, що завжди є потреба розподілити права доступу до файлів та даних між різними користувачами, які мають доступ до платформи.
У випадку локальних рішень, це було досить звичним завданням. Системний адміністратор встановлював правила, використовуючи відповідний інструмент, створював групи користувачів і встановлював зв’язки між цими групами та конкретними каталогами або точками монтування, до яких вони мали доступ. Також визначався рівень доступу – лише читання чи читання та запис.
Сьогодні, у контексті хмарних платформ, таких як AWS, очевидно, що користувачі матимуть подібні вимоги до обмеження доступу до даних. Проте, спосіб вирішення цієї задачі має бути іншим. Файли більше не зберігаються на Unix-серверах, а в хмарі (і потенційно доступні не лише для всієї організації, а й для всього світу). Замість папок використовуються S3-бакети.

Нижче представлено альтернативний підхід до вирішення цієї проблеми, заснований на реальному досвіді створення подібних рішень.
Простий, але в значній мірі ручний підхід
Один із варіантів вирішення цього питання без автоматизації є відносно легким і простим:
- Створити окремий бакет для кожної групи користувачів.
- Налаштувати права доступу до бакета таким чином, щоб тільки ця група мала до нього доступ.
Це цілком прийнятне рішення, якщо потрібен швидкий та простий варіант. Проте, існують певні обмеження, про які слід пам’ятати.
За замовчуванням, один AWS-акаунт дозволяє створити лише 100 S3-бакетів. Цю межу можна збільшити до 1000, подавши запит до AWS. Якщо обмеження не є проблемою у вашому випадку, то кожен із користувачів вашого домену може працювати в окремому S3-бакеті, і на цьому можна зупинитися.
Проблеми можуть виникнути, якщо існують групи людей з міжфункціональними обов’язками або користувачі, яким потрібен доступ до контенту з декількох доменів одночасно. Наприклад:
- Аналітики даних, які аналізують контент для кількох різних областей, регіонів тощо.
- Команда тестування, яка обслуговує різні групи розробників.
- Створення звітів користувачів, які потребують аналізу інформаційних панелей на основі даних з різних країн одного регіону.
Як ви можете собі уявити, цей список може бути досить довгим, оскільки потреби організацій створюють різноманітні варіанти використання.
Зі зростанням цього списку, ускладнюється й оркестрація прав доступу для забезпечення різних рівнів доступу до S3-бакетів. Потрібні додаткові інструменти, можливо навіть окремий адміністратор, який буде займатися підтримкою списків прав доступу і оновлювати їх у міру потреби. (а зміни будуть досить часто, особливо у великих організаціях).
Отже, як можна досягти того ж більш організовано та автоматизовано?
Якщо підхід “бакет для кожного домену” не працює, будь-яке інше рішення буде вимагати спільних бакетів для декількох груп користувачів. У таких випадках необхідно розробити логіку призначення прав доступу, яка буде легко динамічно змінюватися або оновлюватися.
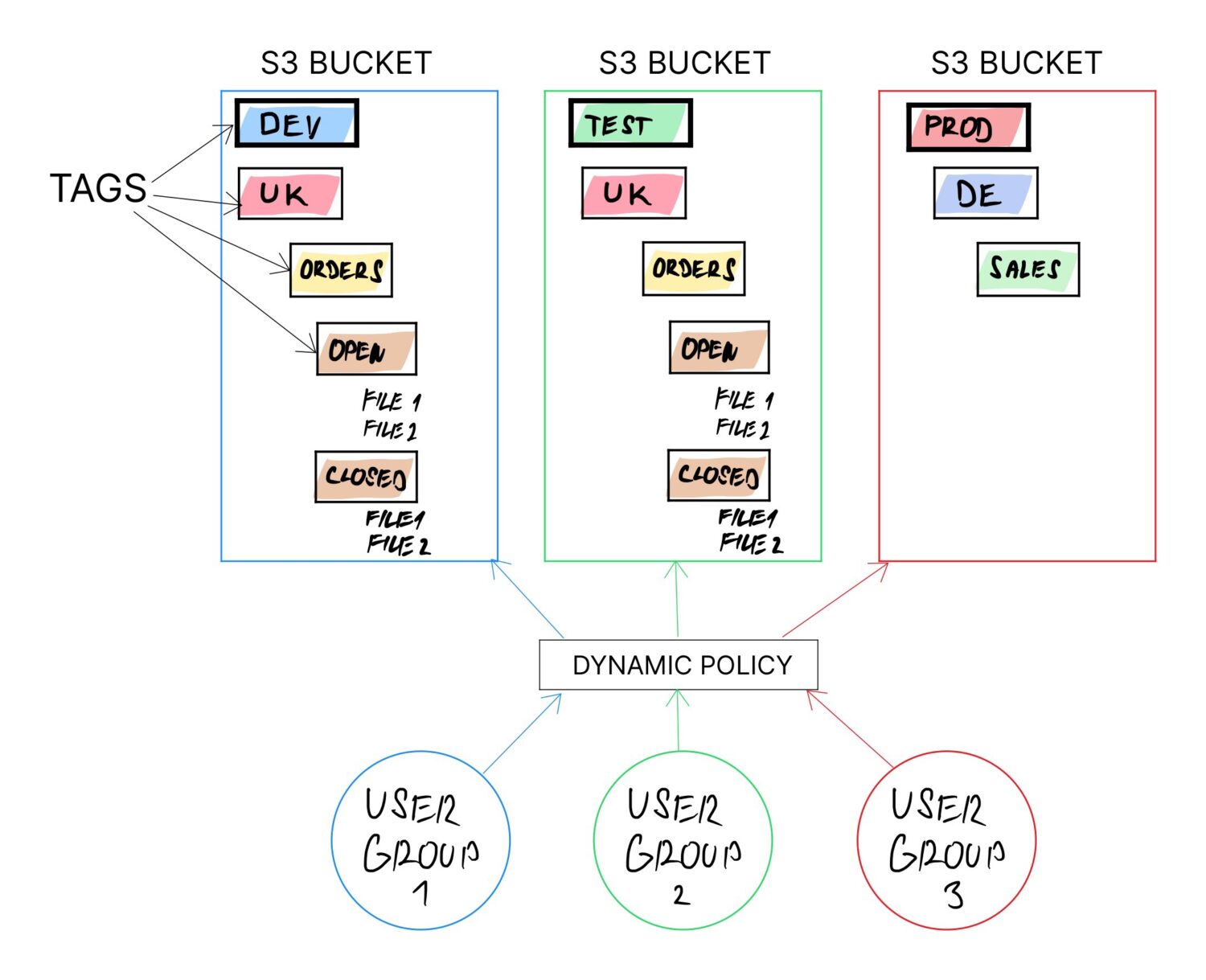
Один зі способів досягти цього – використовувати теги для S3-бакетів. Теги в будь-якому випадку рекомендується використовувати (хоча б для спрощення категоризації рахунків). Крім того, тег можна в будь-який момент змінити.
Якщо вся логіка побудована на основі тегів, а решта конфігурації залежить від значень тегів, то динамічність гарантована, оскільки можна змінити призначення бакета, просто оновивши значення тегів.
Які теги використовувати, щоб це працювало?
Це залежить від конкретного застосування. Наприклад:
- Може виникнути необхідність розподілити бакети за типом середовища. У такому випадку, один із тегів буде щось на зразок “ENV” зі значеннями “DEV”, “TEST”, “PROD” тощо.
- Можливо, потрібно розділити команди за країною. Тоді іншим тегом буде “COUNTRY” зі значенням відповідної країни.
- Або ви можете розподілити користувачів за функціональними відділами, наприклад, бізнес-аналітики, користувачі сховищ даних, спеціалісти з обробки даних тощо. У такому випадку створюється тег “USER_TYPE” з відповідним значенням.
- Інший варіант – явно визначити структуру папок для певних груп користувачів, які вони повинні використовувати. Це можна зробити за допомогою тегів, де вказати робочі каталоги, наприклад: “дані/імпорт”, “дані/оброблені”, “дані/помилки” тощо.
Ідеально, якщо теги визначено так, щоб їх можна було логічно об’єднати та створити структуру папок у бакеті.
Наприклад, ви можете поєднати теги з наведених вище прикладів, щоб створити спеціальну структуру папок для різних типів користувачів із різних країн із визначеними папками імпорту:
- /<ENV>/<USER_TYPE>/<COUNTRY>/<UPLOAD>
Змінивши значення <ENV>, ви можете перепризначити тег (чи відноситься він до тестового середовища, розробки, продакшену тощо).
Це дозволить використовувати один і той же бакет для багатьох різних користувачів. Бакети явно не підтримують папки, але вони підтримують “мітки”. Зрештою, ці мітки працюють як вкладені папки, оскільки користувачам потрібно пройти через ряд міток, щоб отримати доступ до своїх даних (подібно до того, як вони робили б з вкладеними папками).
Визначивши теги у відповідній формі, наступним кроком є створення політик для S3-бакетів, які будуть використовувати ці теги.
Якщо політики використовують імена тегів, ви створюєте так звані “динамічні політики”. Це означає, що ваша політика буде поводитися по-різному для бакетів з різними значеннями тегів, на які політика посилається у формі заповнювачів.
Цей крок вимагає спеціального кодування динамічних політик, але його можна спростити за допомогою інструмента редактора політик Amazon AWS.
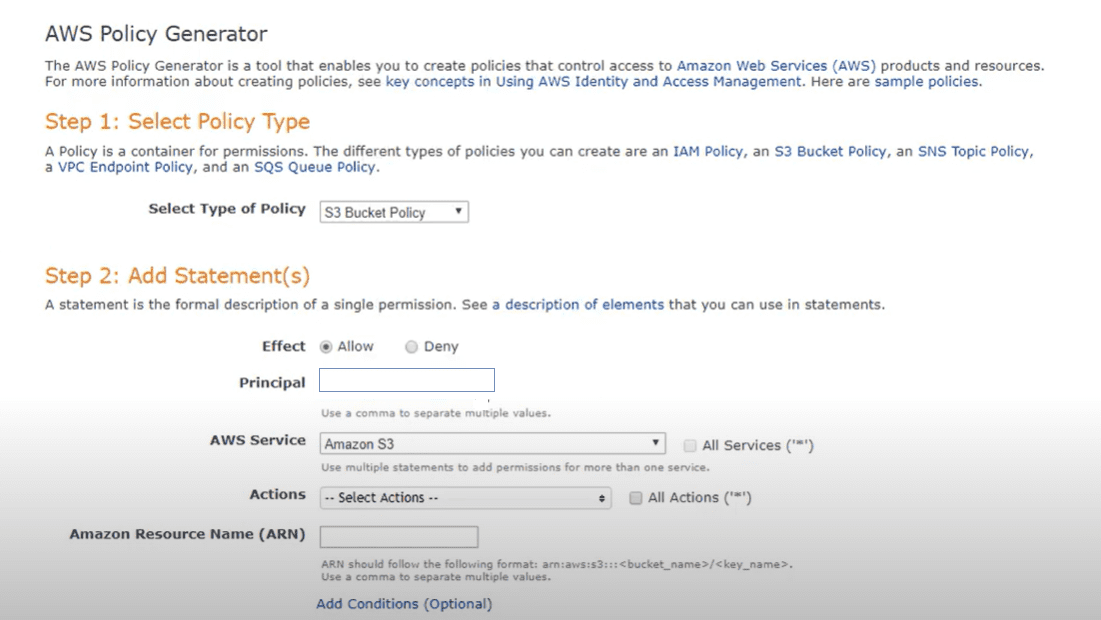
У самій політиці потрібно закодувати конкретні права доступу, що повинні застосовуватися до бакета, і рівень доступу (читання, запис). Логіка зчитує теги у бакетах і створює структуру папок (створюючи мітки на основі тегів). На основі значень тегів будуть створені вкладені папки, і будуть призначені необхідні права доступу.
Перевага динамічної політики в тому, що можна створити лише одну динамічну політику і призначити її багатьом бакетам. Ця політика діятиме по-різному для бакетів з різними значеннями тегів, але завжди відповідатиме вашим очікуванням щодо бакетів із такими значеннями тегів.
Це дійсно ефективний спосіб організовано і централізовано керувати розподілом прав доступу для великої кількості бакетів, де очікується, що кожен бакет відповідатиме певним шаблонним структурам, узгодженим заздалегідь і використовуватиметься користувачами.
Автоматизуйте залучення нових користувачів
Після визначення динамічних політик і призначення їх існуючим бакетам, користувачі можуть почати використовувати бакети без ризику, що користувачі з різних груп не матимуть доступу до контенту, який зберігається в одному бакеті, але розташований у структурі папок, до яких вони не мають доступу.
Для груп користувачів із ширшим доступом буде легко отримати доступ до даних, оскільки всі вони зберігатимуться в одному бакеті.
Останній крок – максимально спростити інтеграцію нових користувачів, бакетів і навіть нових тегів. Це призвело до ще одного спеціального кодування, яке не повинно бути надто складним, якщо процес інтеграції має чіткі правила, які можна інкапсулювати за допомогою простої логіки алгоритму. (Принаймні ви можете довести, що ваш процес має логіку і не виконується хаотично).
Це може бути так само просто, як створення виконуваного скрипту за допомогою AWS CLI з параметрами, необхідними для успішного підключення нового об’єкту до платформи. Або навіть серія скриптів CLI, які виконуються у визначеному порядку:
- create_new_bucket(<ENV>,<ENV_VALUE>,<COUNTRY>,<COUNTRY_VALUE>, ..)
- create_new_tag(<bucket_id>,<tag_name>,<tag_value>)
- update_existing_tag(<bucket_id>,<tag_name>,<tag_value>)
- create_user_group(<тип_користувача>,<країна>,<env>)
- тощо
Ви зрозуміли суть. 😃
Порада професіонала 👨💻
Якщо хочете, є одна професійна порада, яку можна легко застосувати.
Динамічні політики можна використовувати не тільки для призначення прав доступу до папок, але і для автоматичного призначення прав обслуговування для бакетів і груп користувачів!
Все, що потрібно, це розширити список тегів у бакетах, а потім додати права доступу до динамічної політики для використання певних сервісів для конкретних груп користувачів.
Наприклад, може існувати група користувачів, яким також потрібен доступ до конкретного сервера кластера бази даних. Цього можна досягти за допомогою динамічних політик, які використовують пакетні завдання, особливо якщо доступ до сервісів керується на основі ролей. Просто додайте до коду динамічної політики частину, що обробляє теги щодо специфікації кластера бази даних і призначає права доступу безпосередньо кластеру БД і групі користувачів.
Таким чином, інтеграція нової групи користувачів буде виконана тільки за допомогою однієї динамічної політики. Крім того, оскільки вона динамічна, її можна повторно використовувати для реєстрації багатьох різних груп користувачів (очікується, що вони будуть дотримуватися того самого шаблону, але не обов’язково тих самих сервісів).
Також можна переглянути ці команди AWS S3 для керування бакетами та даними.