Google JAX, або Just After Execution, являє собою фреймворк, розроблений фахівцями Google для оптимізації обчислювальних процесів у машинному навчанні.
По суті, це бібліотека Python, яка суттєво прискорює виконання наукових розрахунків, перетворень функцій, процесів глибокого навчання, роботи з нейронними мережами та багатьох інших завдань.
Про Google JAX
NumPy є базовим обчислювальним пакетом у Python, що включає в себе широкий спектр функцій, таких як агрегації, векторні операції, засоби лінійної алгебри, маніпуляції з багатовимірними масивами і матрицями, а також багато іншого.
Виникає питання: чи можна ще більше прискорити обчислення, які виконуються за допомогою NumPy, особливо коли йдеться про обробку великих обсягів даних?
Чи існує інструмент, здатний ефективно працювати на різних типах процесорів, таких як GPU або TPU, не вимагаючи жодних змін у коді?
А що, якщо система могла б автоматично та ефективніше здійснювати перетворення складних функцій?
Google JAX – це саме та бібліотека, яка вирішує ці завдання та пропонує набагато більше можливостей. Вона створена для досягнення максимальної продуктивності та ефективного виконання завдань у галузі машинного навчання (ML) та глибокого навчання. Google JAX надає унікальні функції перетворення, які виділяють її серед інших ML-бібліотек і допомагають у передових наукових обчисленнях для глибокого навчання та нейронних мереж, а саме:
- Автоматична диференціація
- Автоматична векторизація
- Автоматичне розпаралелювання
- Компіляція в режимі реального часу (JIT)
Унікальні можливості Google JAX
Всі перетворення використовують XLA (прискорену лінійну алгебру) для підвищення продуктивності та оптимізації використання пам’яті. XLA є компілятором, розробленим спеціально для лінійної алгебри, і він прискорює моделі TensorFlow. Застосування XLA до коду Python не вимагає значних змін у структурі коду!
Розгляньмо детально кожну з цих можливостей.
Особливості Google JAX
Google JAX має низку важливих функцій для складних перетворень, які підвищують продуктивність та ефективність виконання завдань глибокого навчання. Серед них – автоматичне диференціювання для обчислення градієнта функції та знаходження похідних будь-якого порядку, а також автоматичне розпаралелювання та JIT для паралельного виконання кількох завдань. Ці перетворення є ключовими для таких сфер застосування, як робототехніка, ігри та наукові дослідження.
Компонована функція перетворення – це чиста функція, що перетворює набір даних у іншу форму. Такі функції називаються компонованими, оскільки вони є самодостатніми (тобто не залежать від інших частин програми) і не мають стану (тобто, для одного й того ж вхідного значення вони завжди повертають однакове вихідне значення).
Y(x) = T: (f(x))
У наведеному вище рівнянні f(x) є вихідною функцією, до якої застосовується перетворення. Y(x) – це результат функції після застосування перетворення.
Наприклад, якщо у вас є функція під назвою “total_bill_amt” і ви хочете отримати результат як перетворення цієї функції, ви можете просто застосувати потрібне перетворення, наприклад, градієнт (grad):
grad_total_bill = grad(total_bill_amt)
Перетворюючи числові функції за допомогою таких інструментів, як grad(), ми можемо легко знаходити їхні похідні вищого порядку, які широко застосовуються в алгоритмах оптимізації глибокого навчання, зокрема градієнтного спуску, що робить алгоритми швидшими та ефективнішими. Аналогічно, використовуючи jit(), ми можемо компілювати програми на Python безпосередньо перед виконанням.
#1. Автоматична диференціація
Python використовує функцію autograd для автоматичного розрізнення коду NumPy та нативного коду Python. JAX використовує модифіковану версію autograd (тобто grad) і поєднує її з XLA (Accelerated Linear Algebra) для автоматичного диференціювання та обчислення похідних будь-якого порядку для GPU (модулів графічної обробки) та TPU (модулів обробки тензорів).
Коротка інформація про TPU, GPU і CPU: ЦП, або центральний процесор, керує всіма операціями на комп’ютері. Графічний процесор – це додатковий процесор, що збільшує обчислювальну потужність і виконує ресурсоємні операції. TPU – це потужний пристрій, розроблений спеціально для складних і важких обчислень, таких як ШІ та алгоритми глибокого навчання.
Як і функція autograd, що може диференціювати через цикли, рекурсії, розгалуження тощо, JAX використовує функцію grad() для обчислення градієнтів у зворотному режимі (зворотне поширення). Крім того, ми можемо диференціювати функцію до будь-якого порядку за допомогою grad:
grad(grad(grad(sin θ))) (1,0)
Автоматичне диференціювання вищого порядку
Як згадувалося раніше, grad дуже корисний для знаходження часткових похідних функції. Ми можемо використовувати часткову похідну для обчислення градієнтного спуску функції втрат відносно параметрів нейронної мережі у процесі глибокого навчання, щоб мінімізувати втрати.
Обчислення часткової похідної
Припустимо, що функція має кілька змінних: x, y і z. Знаходження похідної однієї змінної, зберігаючи інші змінні постійними, називається частковою похідною. Наприклад, є функція:
f(x,y,z) = x + 2y + z2
Приклад для ілюстрації часткової похідної
Часткова похідна від x буде ∂f/∂x, що показує, як змінюється функція в залежності від змінної x, коли інші змінні залишаються сталими. Якщо обчислювати це вручну, потрібно написати програму для диференціювання, застосувати її для кожної змінної, а потім обчислити градієнтний спуск. Це стало б складним і трудомістким процесом для багатьох змінних.
Автоматичне диференціювання розбиває функцію на набір елементарних операцій, таких як +, -, *, /, або sin, cos, tan, exp тощо, а потім застосовує правило ланцюга для обчислення похідної. Це можна робити як у прямому, так і в зворотному режимі.
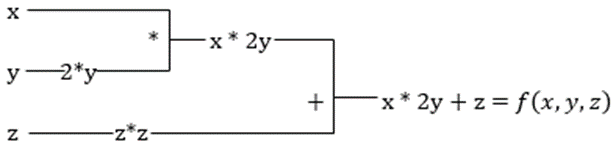
І це ще не все! Усі ці обчислення виконуються дуже швидко (уявіть собі мільйони подібних обчислень і час, який вони можуть зайняти!). XLA гарантує високу швидкість і продуктивність.
#2. Прискорена лінійна алгебра
Розглянемо попереднє рівняння. Без XLA обчислення потребуватимуть трьох (або більше) ядер, де кожне ядро виконуватиме невелике завдання. Наприклад:
Ядро k1 –> x * 2y (множення)
k2 –> x * 2y + z (додавання)
k3 –> Згортка
Якщо те саме завдання виконується за допомогою XLA, єдине ядро виконує всі проміжні операції, об’єднуючи їх. Проміжні результати елементарних операцій передаються у вигляді потоку, а не зберігаються в пам’яті, що заощаджує пам’ять і підвищує швидкість.
#3. Компіляція в режимі реального часу
JAX внутрішньо використовує компілятор XLA для підвищення швидкості виконання. XLA може збільшити швидкість CPU, GPU і TPU. Все це стає можливим завдяки виконанню коду JIT. Щоб скористатися цією функцією, необхідно використовувати jit через імпорт:
from jax import jit def my_function(x): …………some lines of code my_function_jit = jit(my_function)
Інший спосіб – використовувати декоратор jit над визначенням функції:
@jit def my_function(x): …………some lines of code
Цей код є значно швидшим, оскільки перетворення повертає скомпільовану версію коду, а не виконує його через інтерпретатор Python. Це особливо корисно для векторних вхідних даних, таких як масиви та матриці.
Те саме стосується всіх існуючих функцій Python. Наприклад, функцій з пакету NumPy. В такому випадку, потрібно імпортувати jax.numpy як jnp, а не NumPy:
import jax import jax.numpy as jnp x = jnp.array([[1,2,3,4], [5,6,7,8]])
Після цього основний об’єкт масиву JAX під назвою DeviceArray замінює стандартний масив NumPy. DeviceArray є ледачим – значення зберігаються в прискорювачі, доки не знадобляться. Це також означає, що програма JAX не чекає результатів, щоб повернутися до викликаючої програми (Python), а надсилає їх асинхронно.
#4. Автоматична векторизація (vmap)
У типових задачах машинного навчання ми маємо набори даних з мільйоном або більше точок даних. Найчастіше нам потрібно виконати певні обчислення або маніпуляції з кожною з цих точок даних, що вимагає значного часу та пам’яті! Наприклад, якщо потрібно знайти квадрат кожної з точок даних у наборі, перше, що спадає на думку, це створити цикл і обчислювати квадрат за квадратом – проте це не ефективно!
Якщо створити ці точки у вигляді векторів, можна виконати обчислення квадратів одночасно, застосувавши векторні або матричні маніпуляції з точками даних за допомогою NumPy. А якщо програма може зробити це автоматично, чи можна просити щось більше? Саме це робить JAX! Він може автоматично векторизувати всі точки даних, щоб виконувати над ними будь-які операції, що робить алгоритми швидшими та ефективнішими.
JAX використовує функцію vmap для автоматичної векторизації. Розглянемо наступний масив:
x = jnp.array([1,2,3,4,5,6,7,8,9,10]) y = jnp.square(x)
Виконуючи вищенаведене, метод square буде застосовано для кожної точки в масиві. Але якщо зробити наступне:
vmap(jnp.square(x))
Метод square виконуватиметься лише один раз, оскільки точки даних тепер автоматично векторизовані за допомогою методу vmap перед виконанням функції, а цикл переноситься на елементарний рівень роботи, що призводить до множення матриць, а не скалярного множення, що забезпечує кращу продуктивність.
#5. Програмування SPMD (pmap)
SPMD, або Single Program Multiple Data, програмування має велике значення у контексті глибокого навчання: часто потрібно застосовувати одні й ті ж функції до різних наборів даних, що розташовані на кількох GPU або TPU. JAX має функцію pmap, яка дозволяє паралельно програмувати на кількох графічних процесорах або будь-якому прискорювачі. Як і JIT, програми, що використовують pmap, компілюються XLA та виконуються одночасно на всіх системах. Це автоматичне розпаралелювання працює як для прямих, так і для зворотних обчислень.
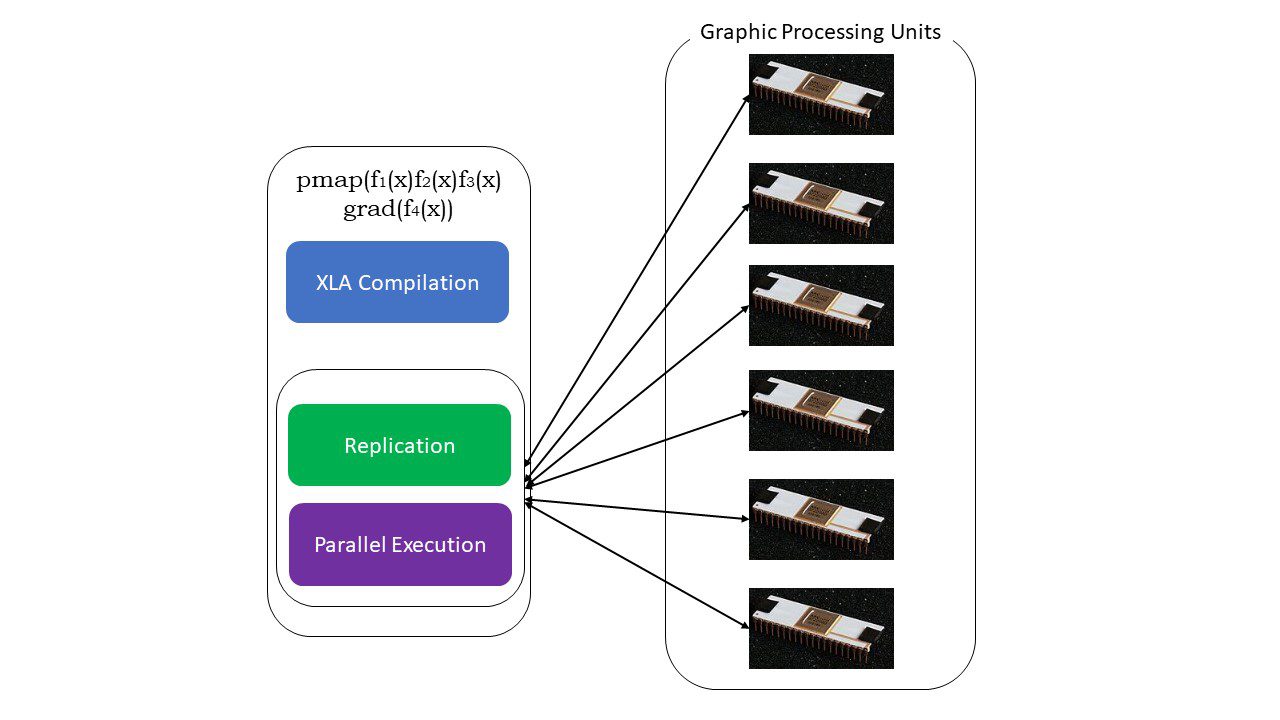
Принцип роботи pmap
Можна також застосувати кілька перетворень за один раз у будь-якому порядку до будь-якої функції, наприклад:
pmap(vmap(jit(grad (f(x)))))
Комбіновані перетворення
Обмеження Google JAX
Розробники Google JAX зосередилися на прискоренні алгоритмів глибокого навчання, реалізувавши всі ці корисні перетворення. Функції та пакети наукових обчислень подібні до NumPy, тому не доведеться турбуватися про складний процес навчання. Однак, JAX має певні обмеження:
- Google JAX все ще знаходиться на ранній стадії розробки, і хоча основною метою є оптимізація продуктивності, він не завжди показує значні переваги для обчислень на ЦП. NumPy може працювати краще, а використання JAX може збільшити накладні витрати.
- JAX ще знаходиться на стадії дослідження або ранніх етапах розробки і потребує більш детального налаштування, щоб відповідати стандартам інфраструктури таких фреймворків, як TensorFlow, які є більш усталеними та мають більше готових моделей, проєктів з відкритим кодом і навчальних матеріалів.
- Наразі JAX не підтримує операційну систему Windows – для його роботи потрібна віртуальна машина.
- JAX працює лише з чистими функціями – тими, які не мають побічних ефектів. Для функцій з побічними ефектами JAX може не підійти.
Як встановити JAX у вашому середовищі Python
Якщо у вас налаштовано Python і ви хочете запустити JAX на локальній машині (ЦП), скористайтеся наступними командами:
pip install --upgrade pip pip install --upgrade "jax[cpu]"
Якщо ви хочете запустити Google JAX на GPU або TPU, дотримуйтеся інструкцій на GitHub JAX. Щоб налаштувати Python, відвідайте офіційні завантаження python.
Висновок
Google JAX чудово підходить для створення ефективних алгоритмів глибокого навчання, робототехніки та досліджень. Незважаючи на обмеження, він широко застосовується з іншими фреймворками, такими як Haiku, Flax та іншими. Ви зможете оцінити можливості JAX під час запуску програм, і побачити різницю в часі виконання коду з JAX і без нього. Для початку можна ознайомитися з офіційною документацією Google JAX.