
Матриця плутанини – це інструмент для оцінки продуктивності типу класифікації алгоритмів керованого машинного навчання.
Що таке матриця плутанини?
Ми, люди, по-різному сприймаємо речі – навіть правду і брехню. Те, що мені може здатися лінією довжиною 10 см, вам може здатися лінією 9 см. Але фактичне значення може бути 9, 10 або щось інше. Те, що ми припускаємо, є прогнозованим значенням!
Як мислить людський мозок
Подібно до того, як наш мозок застосовує нашу власну логіку, щоб передбачити щось, машини застосовують різні алгоритми (які називаються алгоритмами машинного навчання), щоб отримати прогнозоване значення для запитання. Знову ж таки, ці значення можуть бути однаковими або відрізнятися від фактичного значення.
У світі конкуренції ми хотіли б знати, чи правильне наше передбачення, чи ні, щоб зрозуміти нашу ефективність. Таким же чином ми можемо визначити продуктивність алгоритму машинного навчання за кількістю прогнозів, які він зробив правильно.
Отже, що таке алгоритм машинного навчання?
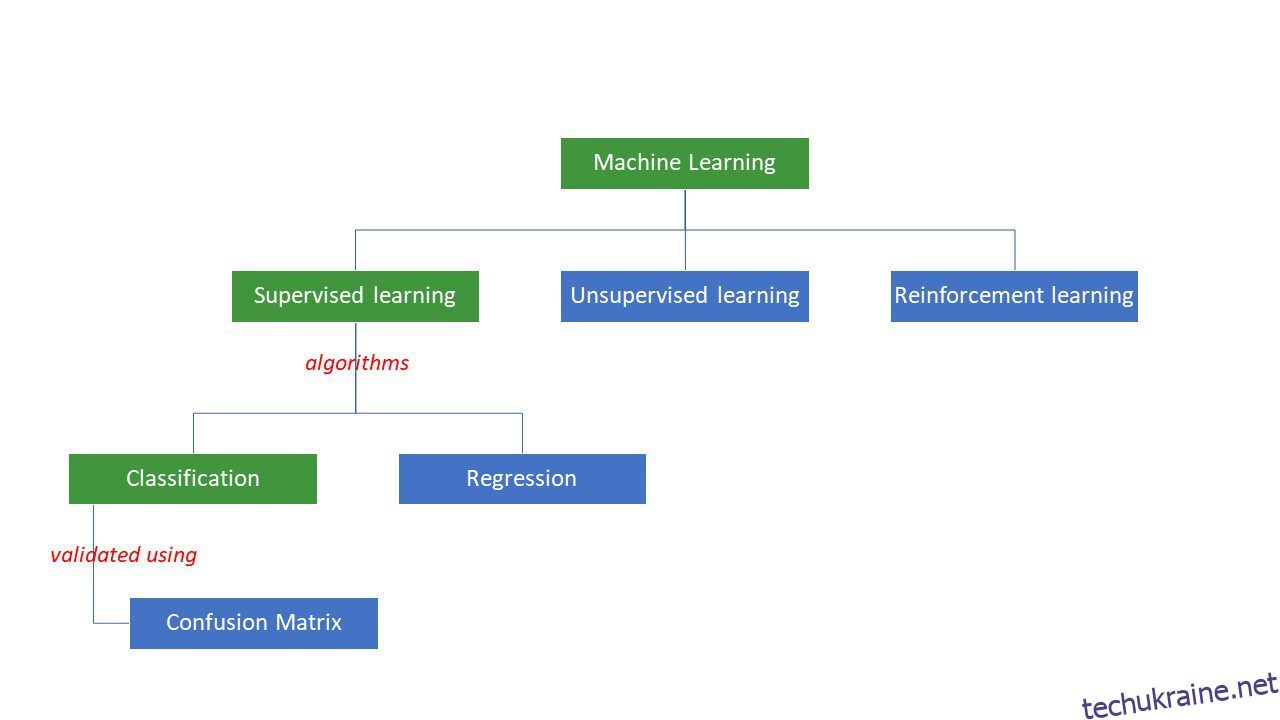
Машини намагаються знайти певні відповіді на проблему, застосовуючи певну логіку або набір інструкцій, які називаються алгоритмами машинного навчання. Алгоритми машинного навчання бувають трьох типів – керовані, неконтрольовані та з підкріпленням.
 Типи алгоритмів машинного навчання
Типи алгоритмів машинного навчання
Найпростіші типи алгоритмів контролюються, коли ми вже знаємо відповідь, і ми навчаємо машини отримувати цю відповідь, навчаючи алгоритм за допомогою великої кількості даних – так само, як дитина розрізняє людей різних вікових груп за дивлячись на їхні риси знову і знову.
Контрольовані алгоритми ML бувають двох типів – класифікаційні та регресійні.
Алгоритми класифікації класифікують або сортують дані на основі певного набору критеріїв. Наприклад, якщо ви хочете, щоб ваш алгоритм групував клієнтів на основі їхніх харчових уподобань – тих, хто любить піцу, і тих, хто не любить піцу, ви повинні використовувати такий алгоритм класифікації, як дерево рішень, випадковий ліс, наївний Байєс або SVM (Підтримка Векторна машина).
Який із цих алгоритмів виконає найкращу роботу? Чому варто вибрати один алгоритм замість іншого?
Введіть матрицю плутанини….
Матриця плутанини — це матриця або таблиця, яка надає інформацію про те, наскільки точний алгоритм класифікації класифікує набір даних. Ну, назва не для того, щоб збивати з пантелику людей, але занадто багато неправильних прогнозів, ймовірно, означають, що алгоритм переплутав😉!
Отже, матриця плутанини – це метод оцінки продуктивності алгоритму класифікації.
як?
Припустімо, ви застосували різні алгоритми до нашої раніше згаданої бінарної задачі: класифікуйте (розділіть) людей залежно від того, люблять вони піцу чи ні. Щоб оцінити алгоритм, який має значення, найближчі до правильної відповіді, ви б використали матрицю плутанини. Для задачі бінарної класифікації (подобається/не подобається, істина/неправда, 1/0) матриця плутанини дає чотири значення сітки, а саме:
- Справжній позитивний (TP)
- Істинно негативний (TN)
- Хибнопозитивний (FP)
- Помилково негативний (FN)
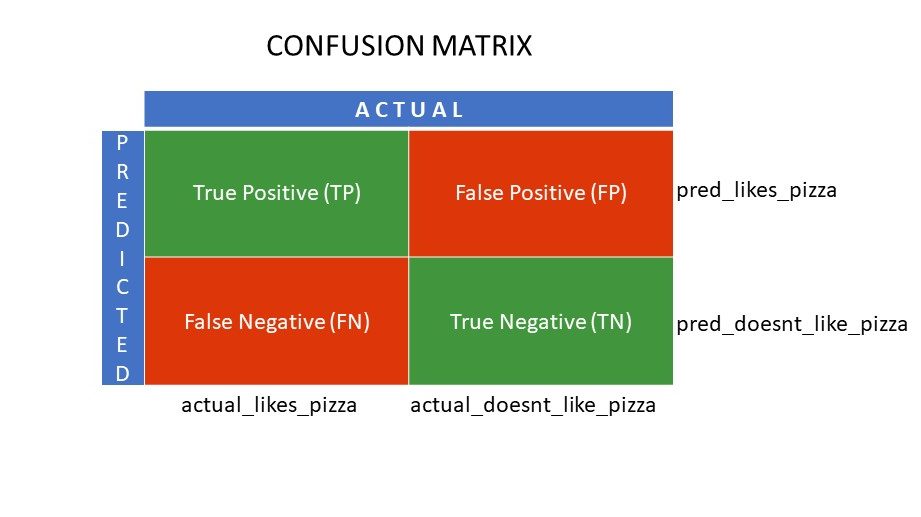
Що таке чотири сітки в матриці плутанини?
Чотири значення, визначені за допомогою матриці плутанини, утворюють сітки матриці.
 Матричні сітки плутанини
Матричні сітки плутанини
Істинне позитивне (TP) і справжнє негативне значення (TN) – це значення, правильно передбачені алгоритмом класифікації,
- TP представляє тих, хто любить піцу, і модель класифікувала їх правильно,
- TN представляє тих, хто не любить піцу, і модель класифікувала їх правильно,
Помилково-позитивний (FP) і Помилково-негативний (FN) – це значення, які неправильно передбачені класифікатором,
- FP представляє тих, хто не любить піцу (негативно), але класифікатор передбачив, що вони люблять піцу (хибно позитивно). FP також називають помилкою I типу.
- FN представляє тих, хто любить піцу (позитивно), але класифікатор передбачив, що вони не люблять (помилково негативно). FN також називають помилкою типу II.
Щоб краще зрозуміти концепцію, розглянемо реальний сценарій.
Припустімо, у вас є набір даних із 400 осіб, які пройшли тест на Covid. Тепер ви отримали результати різних алгоритмів, які визначали кількість Covid-позитивних і Covid-негативних людей.
Ось дві матриці плутанини для порівняння:
Дивлячись на обидва, у вас може виникнути спокуса сказати, що 1-й алгоритм точніший. Але, щоб отримати конкретний результат, нам потрібні певні показники, які можуть виміряти точність, точність і багато інших значень, які підтверджують, який алгоритм кращий.
Метрики з використанням матриці плутанини та їх значення
Основні показники, які допомагають нам вирішити, чи правильний прогноз зробив класифікатор, це:
#1. Відкликання/Чутливість
Пригадування, або чутливість, або істинно позитивний показник (TPR), або ймовірність виявлення — це відношення правильних позитивних прогнозів (TP) до загальної кількості позитивних (тобто, TP і FN).
R = TP/(TP + FN)
Відкликання – це міра правильних позитивних результатів, отриманих із кількості правильних позитивних результатів, які могли бути отримані. Більше значення Recall означає менше помилкових негативів, що добре для алгоритму. Використовуйте Recall, коли важливо знати помилкові негативи. Наприклад, якщо у людини є кілька закупорок серця, і модель показує, що з ним усе гаразд, це може призвести до летального результату.
#2. Точність
Точність – це міра правильних позитивних результатів серед усіх прогнозованих позитивних результатів, включаючи істинні та хибні позитивні результати.
Pr = TP/(TP + FP)
Точність дуже важлива, коли помилкові спрацьовування занадто важливі, щоб їх ігнорувати. Наприклад, якщо у людини немає цукрового діабету, але модель це показує, і лікар призначає певні ліки. Це може призвести до серйозних побічних ефектів.
#3. Специфіка
Специфічність або True Negative Rate (TNR) – це правильні негативні результати, отримані з усіх результатів, які могли бути негативними.
S = TN/(TN + FP)
Це показник того, наскільки добре ваш класифікатор визначає від’ємні значення.
#4. Точність
Точність – це кількість правильних прогнозів із загальної кількості прогнозів. Отже, якщо ви правильно знайшли 20 позитивних і 10 негативних значень із вибірки з 50, точність вашої моделі буде 30/50.
Точність A = (TP + TN)/(TP + TN + FP + FN)
#5. Поширеність
Поширеність – це міра кількості позитивних результатів, отриманих серед усіх результатів.
P = (TP + FN)/(TP + TN + FP + FN)
#6. Оцінка F
Іноді важко порівняти два класифікатори (моделі), використовуючи лише Precision і Recall, які є лише арифметичними середніми значеннями комбінації чотирьох сіток. У таких випадках ми можемо використовувати оцінку F або оцінку F1, яка є середнім гармонійним значенням, яке є більш точним, оскільки воно не надто змінюється для надзвичайно високих значень. Вищий показник F (макс. 1) означає кращу модель.
Оцінка F = 2*Точність*Пригадування/ (Пам’ятовування + Точність)
Коли важливо подбати як про помилкові позитивні, так і про помилкові негативні результати, оцінка F1 є хорошим показником. Наприклад, тих, хто не ковід-позитивний (але алгоритм показав це), не потрібно без потреби ізолювати. Так само тих, хто позитивний на Covid (але алгоритм сказав, що ні), потрібно ізолювати.
#7. ROC криві
Такі параметри, як Accuracy і Precision, є хорошими показниками, якщо дані збалансовані. Для незбалансованого набору даних висока точність не обов’язково означає ефективність класифікатора. Наприклад, 90 зі 100 учнів групи знають іспанську мову. Тепер, навіть якщо ваш алгоритм каже, що всі 100 знають іспанську, його точність буде 90%, що може дати неправильне уявлення про модель. У випадках незбалансованих наборів даних такі показники, як ROC, є більш ефективними визначниками.
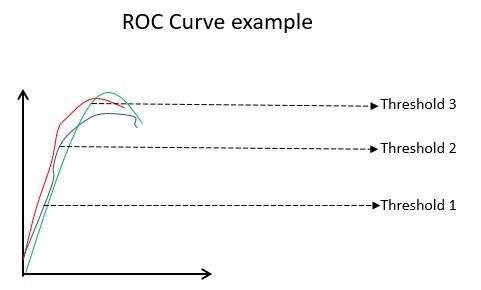 Приклад кривої ROC
Приклад кривої ROC
Крива ROC (робоча характеристика приймача) візуально відображає ефективність моделі двійкової класифікації за різних порогів класифікації. Це графік TPR (частота істинних позитивних результатів) проти FPR (частота хибних позитивних результатів), яка розраховується як (1-специфічність) при різних порогових значеннях. Значення, найближче до 45 градусів (верхній лівий кут) на графіку, є найточнішим пороговим значенням. Якщо поріг занадто високий, у нас не буде багато помилкових спрацьовувань, але ми отримаємо більше помилкових негативів і навпаки.
Як правило, коли будується крива ROC для різних моделей, кращою моделлю вважається та, яка має найбільшу площу під кривою (AUC).
Давайте обчислимо всі значення метрики для наших матриць плутанини Класифікатора I та Класифікатора II:
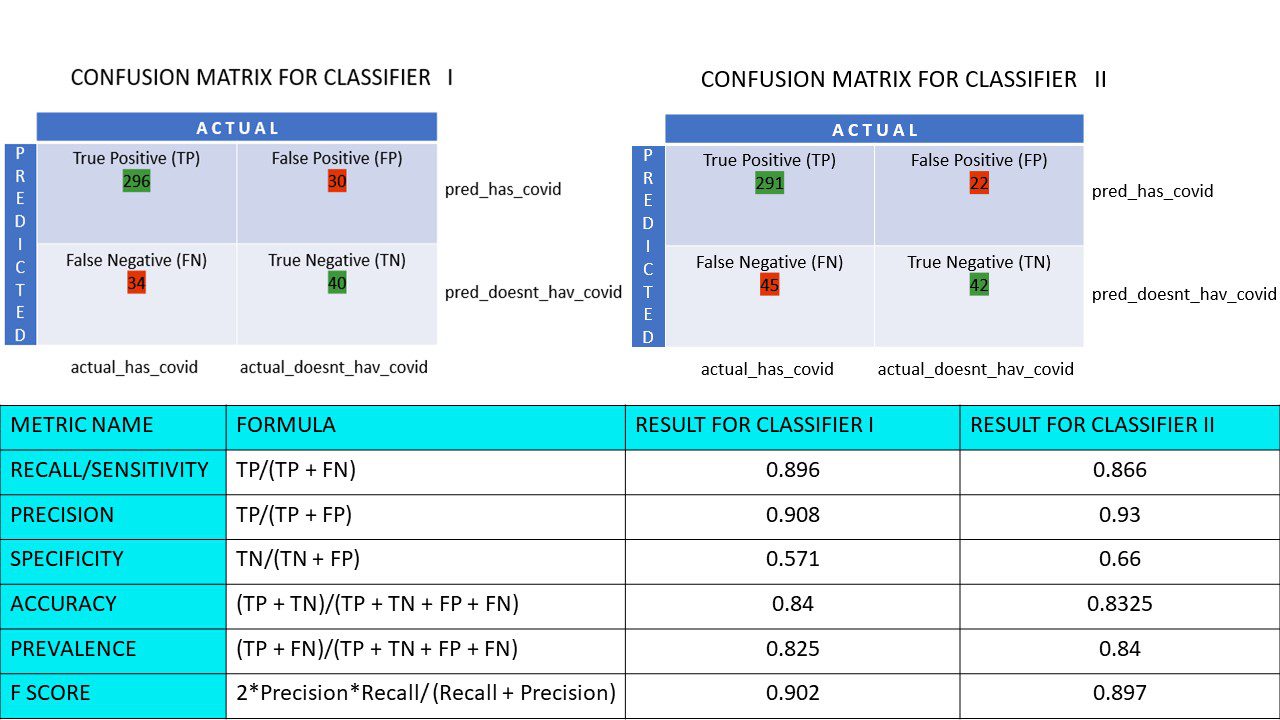 Порівняння показників для класифікаторів 1 і 2 дослідження піци
Порівняння показників для класифікаторів 1 і 2 дослідження піци
Ми бачимо, що точність більша в класифікаторі II, тоді як точність трохи вища в класифікаторі I. Виходячи з наявної проблеми, особи, які приймають рішення, можуть вибрати класифікатори I або II.
N x N матриця плутанини
Поки що ми бачили матрицю плутанини для бінарних класифікаторів. Що, якби було більше категорій, ніж просто так/ні чи подобається/не подобається. Наприклад, якби ваш алгоритм сортував зображення червоного, зеленого та синього кольорів. Такий тип класифікації називається багатокласовою класифікацією. Кількість вихідних змінних також визначає розмір матриці. Отже, у цьому випадку матриця плутанини буде 3×3.
 Матриця плутанини для багатокласового класифікатора
Матриця плутанини для багатокласового класифікатора
Резюме
Матриця плутанини є чудовою системою оцінки, оскільки вона дає детальну інформацію про продуктивність алгоритму класифікації. Він добре працює як для бінарних, так і для багатокласових класифікаторів, де потрібно подбати про більше ніж 2 параметри. Легко візуалізувати матрицю плутанини, і ми можемо згенерувати всі інші показники ефективності, як-от оцінка F, точність, ROC і точність, використовуючи матрицю плутанини.
Ви також можете подивитися, як вибрати алгоритми ML для задач регресії.