Матриця неточностей: Ключовий інструмент оцінки моделей машинного навчання
Матриця неточностей – це важливий інструмент для вимірювання ефективності алгоритмів класифікації в керованому машинному навчанні.
Що являє собою матриця неточностей?
Сприйняття дійсності у кожного з нас може бути різним. Навіть у питаннях правди і неправди наші погляди можуть відрізнятися. Наприклад, довжина лінії в 10 см для однієї людини може здаватися 9 см для іншої. Фактична довжина може бути 9, 10 або будь-якою іншою. Те, що ми вважаємо, є нашим прогнозованим значенням!
Як працює людський мозок
Так само, як наш розум використовує власну логіку для передбачення, алгоритми машинного навчання застосовують різноманітні методи, щоб отримати прогнозовані результати. Звісно, ці результати можуть збігатися або відрізнятися від реальних значень.
У конкурентному світі, нам важливо знати, наскільки точні наші прогнози. Таким чином, ми можемо оцінити ефективність алгоритму машинного навчання, підрахувавши кількість правильних передбачень.
Що таке алгоритм машинного навчання?
Машини шукають відповіді на проблеми, використовуючи логіку або набір інструкцій, які ми називаємо алгоритмами машинного навчання. Існує три основні типи таких алгоритмів: керовані, некеровані та з підкріпленням.
Найпростіші алгоритми є керованими. У таких випадках ми вже знаємо правильну відповідь і навчаємо машину, використовуючи велику кількість даних. Це як дитина, яка розрізняє людей різного віку, спостерігаючи за їхніми рисами.
Керовані алгоритми ML поділяються на два типи: класифікаційні та регресійні.
Алгоритми класифікації сортують дані на основі певних критеріїв. Наприклад, якщо потрібно розділити клієнтів на тих, хто любить піцу, і тих, хто її не любить, слід використовувати алгоритм класифікації, такий як дерево рішень, випадковий ліс, наївний Байєс або SVM (машина опорних векторів).
Який з цих алгоритмів буде найефективнішим? Чому ми повинні обирати один алгоритм замість іншого?
Саме тут на допомогу приходить матриця неточностей!
Матриця неточностей – це таблиця, яка показує, наскільки точно алгоритм класифікації розпізнає набір даних. Назва може здатися заплутаною, але велика кількість неправильних прогнозів дійсно означає, що алгоритм помилився.
Отже, матриця неточностей – це інструмент для оцінки ефективності алгоритму класифікації.
Як це працює?
Припустимо, ви застосували різні алгоритми до задачі бінарної класифікації: розділити людей на тих, хто любить піцу, і тих, хто її не любить. Для оцінки алгоритму, який дає результати, максимально наближені до правильних, використовується матриця неточностей. Для задачі бінарної класифікації (подобається/не подобається, істина/неправда, 1/0) матриця неточностей містить чотири значення:
- Істинно позитивний (TP)
- Істинно негативний (TN)
- Хибно позитивний (FP)
- Хибно негативний (FN)
Що означають чотири значення в матриці неточностей?
Чотири значення, отримані за допомогою матриці неточностей, утворюють її сітку.
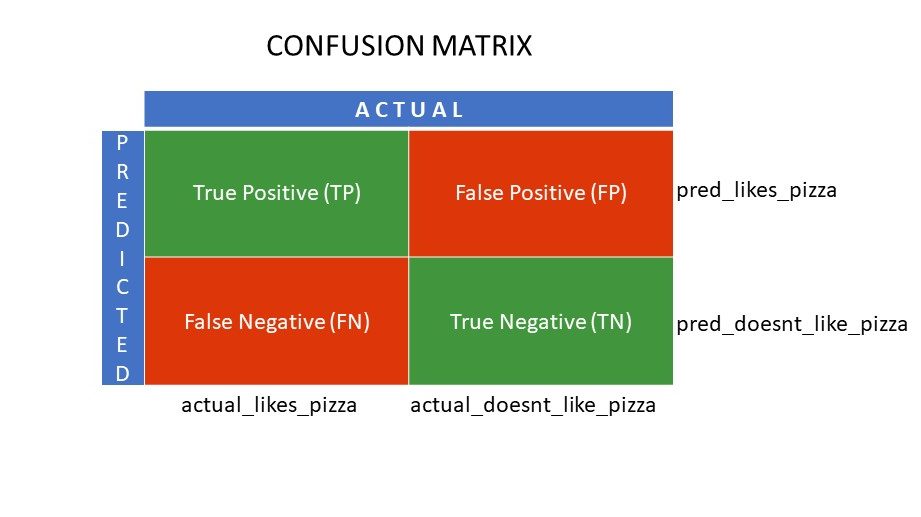
Істинно позитивні (TP) і істинно негативні (TN) значення – це правильні передбачення алгоритму:
- TP – це люди, які люблять піцу, і алгоритм правильно це визначив.
- TN – це люди, які не люблять піцу, і алгоритм також правильно це визначив.
Хибно позитивні (FP) і хибно негативні (FN) – це неправильні прогнози:
- FP – це люди, які не люблять піцу (негативні), але класифікатор визначив, що вони її люблять (хибно позитивні). FP також називають помилкою I типу.
- FN – це люди, які люблять піцу (позитивні), але класифікатор визначив, що вони її не люблять (хибно негативні). FN також називають помилкою II типу.
Розглянемо приклад для кращого розуміння.
Уявіть, що у вас є дані про 400 людей, які пройшли тест на Covid. Ви отримали результати різних алгоритмів, які визначали кількість Covid-позитивних і Covid-негативних людей.
Нижче наведено дві матриці неточностей для порівняння:
На перший погляд може здатися, що перший алгоритм точніший. Але для конкретного висновку нам потрібні показники, які вимірюють точність та інші значення.
Метрики, що використовуються з матрицею неточностей, та їх важливість
Основні показники, що допомагають нам визначити точність прогнозу класифікатора:
#1. Повнота/Чутливість
Повнота, чутливість або частка істинно позитивних результатів (TPR) – це відношення правильно визначених позитивних випадків (TP) до загальної кількості позитивних випадків (TP і FN).
R = TP/(TP + FN)
Повнота – це міра правильно визначених позитивних випадків з усіх можливих. Висока повнота означає менше хибно негативних результатів, що є бажаним для алгоритму. Використовуйте повноту, коли важливо знати про хибно негативні результати. Наприклад, якщо у пацієнта є закупорка серця, а модель стверджує, що з ним все гаразд, це може призвести до фатальних наслідків.
#2. Точність
Точність – це міра правильно визначених позитивних результатів серед усіх спрогнозованих позитивних результатів, включаючи істинні та хибні.
Pr = TP/(TP + FP)
Точність дуже важлива, коли хибні спрацювання є критичними. Наприклад, якщо у людини немає діабету, але модель це показує, і лікар призначає ліки. Це може призвести до серйозних побічних ефектів.
#3. Специфічність
Специфічність, або частка істинно негативних результатів (TNR), – це правильні негативні результати з усіх можливих негативних результатів.
S = TN/(TN + FP)
Це показник того, наскільки добре ваш класифікатор визначає негативні значення.
#4. Загальна точність
Загальна точність – це кількість правильних прогнозів з усіх прогнозів. Наприклад, якщо ви правильно визначили 20 позитивних і 10 негативних значень із вибірки в 50, точність моделі буде 30/50.
A = (TP + TN)/(TP + TN + FP + FN)
#5. Поширеність
Поширеність – це частка позитивних результатів серед усіх результатів.
P = (TP + FN)/(TP + TN + FP + FN)
#6. F-міра
Іноді важко порівняти два класифікатори (моделі), використовуючи лише точність і повноту, які є лише середніми арифметичними значеннями. У таких випадках можна використовувати F-міру або F1-міру, яка є середнім гармонійним, що є більш точним, оскільки не сильно змінюється для високих значень. Вищий показник F (макс. 1) означає кращу модель.
F-міра = 2 * Точність * Повнота / (Повнота + Точність)
Коли важливо враховувати як хибно позитивні, так і хибно негативні результати, F1-міра є гарним показником. Наприклад, тих, хто не є ковід-позитивними (але алгоритм показує це), не потрібно ізолювати без потреби. Так само, тих, хто є позитивним на Covid (але алгоритм сказав, що ні), потрібно ізолювати.
#7. ROC-криві
Показники, як-от точність, є ефективними, якщо дані збалансовані. Для незбалансованих даних висока точність не завжди означає ефективність класифікатора. Наприклад, 90 зі 100 учнів у групі знають іспанську. Якщо ваш алгоритм скаже, що всі 100 знають іспанську, точність буде 90%, що створить неправильне уявлення про модель. У випадках незбалансованих наборів даних, показники, як ROC, є більш ефективними.
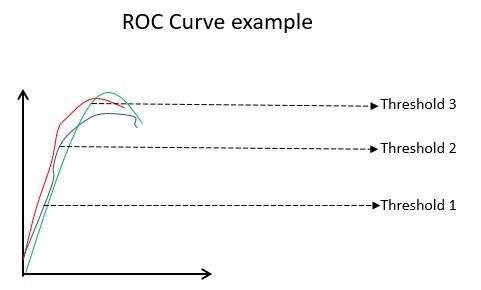
ROC-крива (робоча характеристика приймача) графічно відображає ефективність моделі бінарної класифікації при різних порогових значеннях. Це графік TPR (частки істинно позитивних результатів) проти FPR (частки хибно позитивних результатів), яка обчислюється як (1-специфічність) при різних порогових значеннях. Значення, найближче до 45 градусів (лівий верхній кут) є найточнішим пороговим значенням. Якщо поріг зависокий, у нас не буде багато хибних спрацювань, але ми отримаємо більше хибно негативних результатів, і навпаки.
Зазвичай, коли будуються ROC-криві для різних моделей, найкращою вважається модель з найбільшою площею під кривою (AUC).
Давайте розрахуємо всі значення для наших матриць неточностей Класифікатора I та Класифікатора II:
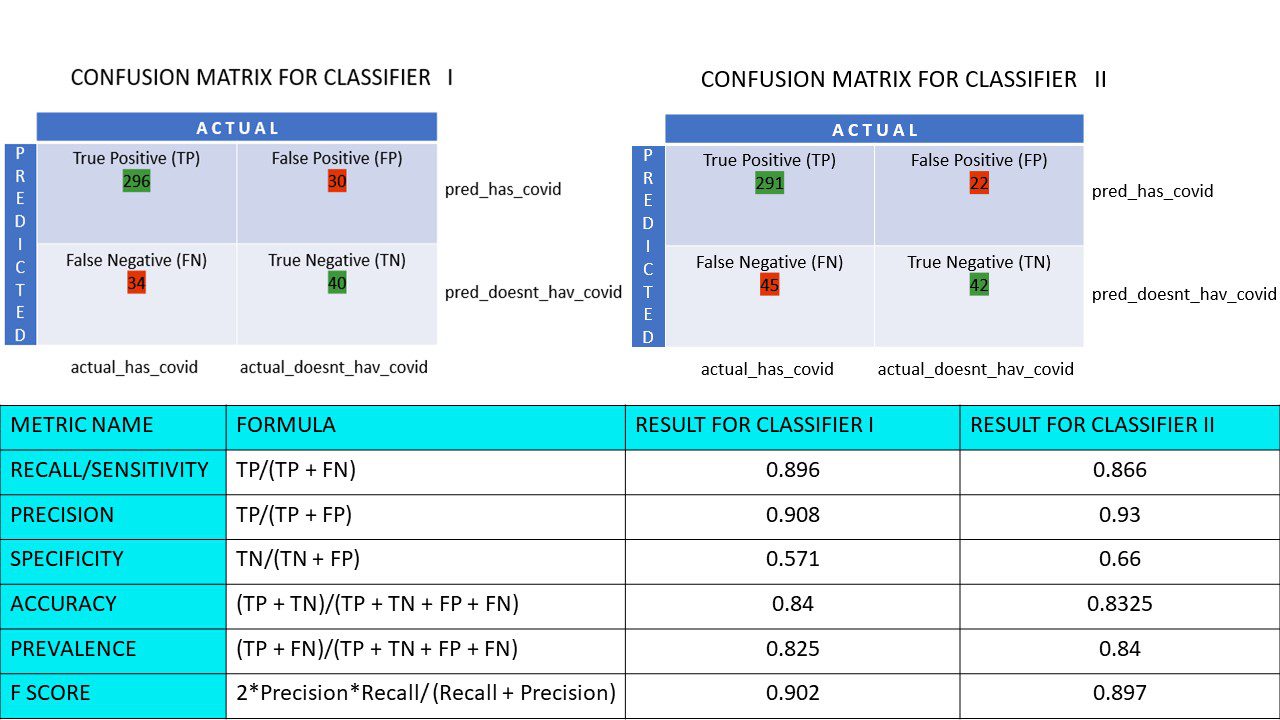
Ми бачимо, що точність вища у класифікатора II, тоді як повнота трохи вища у класифікатора I. Виходячи з конкретного завдання, особи, що приймають рішення, можуть обрати класифікатор I або II.
N x N матриця неточностей
Ми розглядали матрицю неточностей для бінарних класифікаторів. А що, якщо категорій більше ніж так/ні чи подобається/не подобається? Наприклад, алгоритм сортує зображення на червоні, зелені та сині. Такий тип класифікації називається багатокласовою. Кількість вихідних змінних визначає розмір матриці. У цьому випадку матриця неточностей буде 3×3.

Висновок
Матриця неточностей – це ефективна система оцінки, що надає детальну інформацію про продуктивність алгоритму класифікації. Вона добре працює як для бінарних, так і для багатокласових класифікаторів. Матрицю неточностей легко візуалізувати, і за її допомогою можна розрахувати інші показники, такі як F-міра, точність, ROC та повнота.
Також ви можете ознайомитися з алгоритмами ML для задач регресії.