

Ключові висновки
- Платформи соціальних медіа продають дані користувачів компаніям зі штучним інтелектом для навчання генеративних моделей ШІ, незважаючи на проблеми конфіденційності.
- Такі платформи, як Meta, Reddit, Tumblr і WordPress.com, активно беруть участь у цих угодах щодо ліцензування даних для навчання ШІ.
- Користувачі можуть зробити деякі невеликі кроки, щоб захистити свої дані, як-от налаштувати параметри конфіденційності, відмовитися від спільного доступу та бути обережними щодо того, що вони публікують в Інтернеті.
Один із найновіших способів монетизації даних користувачів компаніями соціальних медіа – це угоди з компаніями штучного інтелекту. Але чи можуть звичайні користувачі щось зробити, щоб захистити свої дані та вміст?
Використання даних соціальних медіа для навчання генеративних моделей штучного інтелекту було суперечливим кроком, але, здається, це не заважає компаніям соціальних мереж роздавати дані користувачів.
Meta вже використовує дані соціальних медіа для навчання генеративних функцій штучного інтелекту, анонсованих на Meta Connect у 2023 році. Це включає Meta AI та такі функції, як створення згенерованих штучним інтелектом стікерів у WhatsApp.
Як заявив Майк Кларк, директор з управління продуктами компанії Meta, в a Допис Meta Newsroom:
«Публічні публікації з Instagram і Facebook, включаючи фотографії та текст, були частиною даних, які використовувалися для навчання генеративних моделей штучного інтелекту, що лежать в основі функцій, які ми анонсували на Connect».
Ця тенденція, схоже, не сповільниться у 2024 році ReutersReddit уклав угоду з Google, щоб зробити вміст платформи соціальних мереж доступним для навчання моделей ШІ.
Заявка Reddit S-1 для свого IPO, поданого 22 лютого 2024 року, підтверджує, що компанія вивчає ліцензійні угоди. У поданні зазначено:
«Дані Reddit є основою для створення поточної технології ШІ та багатьох LLM. Ми віримо, що величезний корпус розмовних даних і знань Reddit продовжуватиме відігравати важливу роль у навчанні та вдосконаленні LLM».
У ньому зазначено, що Reddit «на ранніх етапах надання дозволу третім особам надавати ліцензії на доступ до пошуку, аналізу та відображення історичних даних і даних у режимі реального часу з нашої платформи» з метою навчання магістрів права.
І хоча Meta та Reddit є одними з найбільших імен у соціальних мережах, вони не єдині платформи, які використовують дані соціальних мереж для навчання ШІ. За словами а повідомляє 404 медіаTumblr і WordPress.com готуються продавати дані користувачів Midjourney і OpenAI.
Швидше за все, якщо ви користуєтеся Facebook, Instagram, Reddit, Tumblr або WordPress.com, ваш загальнодоступний вміст уже використовувався під час навчання магістрів права.
Наприклад, якщо ви використовуєте Інструмент пошуку Washington Post щоб побачити, які сайти були включені до набору даних Google C4, який використовувався як частина навчання Барда, ви побачите, що на Reddit.com припадає 7,9 мільйонів токенів.

На Tumblr.com припадає 1,6 мільйона токенів. Мій власний невеликий веб-сайт, який використовує WordPress.com, налічував 14 000 токенів, тож невеликі особисті блоги могли бути включені в набір даних.
У зв’язку з поточними угодами між компаніями штучного інтелекту та компаніями соціальних медіа ліцензійні угоди означатимуть, що ці дані будуть активно продаватися, а не просто зчищатися з Інтернету.
Але що ви можете з цим зробити, коли справа доходить до майбутньої обробки? Meta представила a форма для генеративних прав суб’єкта даних AI що дозволяє заперечувати чи обмежувати обробку ваших персональних даних третіми сторонами для навчання генеративних моделей ШІ Meta.
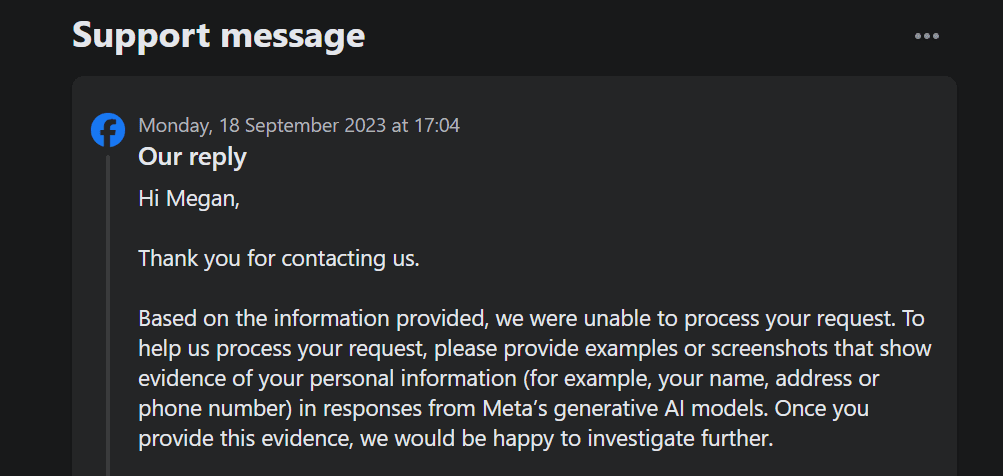
Примітно, що ця опція не дозволяє вам заперечувати проти власної обробки Meta першою стороною ваших даних для навчання генеративного ШІ. Крім того, коли я подав запит, щоб заперечити використання моїх особистих даних за допомогою форми, запит служби підтримки вимагав від мене довести, що моя особиста інформація вже з’являється в генеративних результатах штучного інтелекту Meta.
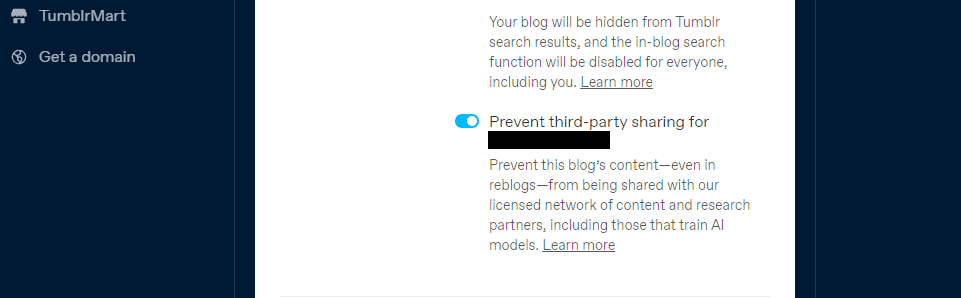
Tumblr також запровадив опцію відмови від надання доступу до вмісту ваших загальнодоступних блогів третім особам за допомогою налаштувань вашого блогу. Ви можете знайти його у своїх налаштуваннях, клацнувши свій блог і прокрутивши вниз до налаштувань видимості. Потім виберіть опцію Запобігти поширенню третьою стороною вашого блогу.
Що стосується такої платформи, як Instagram, ви можете спробувати змінити обліковий запис Instagram на приватний, щоб запобігти використанню ваших даних. Це не гарантує, що ваші дані не будуть використані, але оскільки сканування даних для LLM, здається, зосереджено на загальнодоступних даних, це може бути потенційним запобіжним заходом.
Ви також можете зробити свій обліковий запис X (Twitter) приватним, але знову ж таки це лише потенційний запобіжний захід і не гарантує, що ваші дані залишаться конфіденційними.
А спільна заява різними національними уповноваженими з питань інформації та експертами в усьому світі також запропонували деякі дії для осіб, які прагнуть мінімізувати ризик конфіденційності, пов’язаний із збиранням даних компаніями зі штучним інтелектом. Порада включає:
- Прочитайте умови та політику конфіденційності веб-сайту, щоб дізнатися, як він ділиться вашою особистою інформацією.
- Обмежте інформацію, яку ви публікуєте в Інтернеті, особливо конфіденційну інформацію.
- Керуйте налаштуваннями конфіденційності.
- Думайте про інформацію, якою ви ділитеся в Інтернеті, довгостроково.
- Зверніться до соціальної мережі або веб-сайту, якщо ви вважаєте, що ваші дані були зібрані неналежним чином. Якщо ви не задоволені їхньою відповіддю, надішліть скаргу до відповідного органу із захисту даних.
Ви також можете видалити певну інформацію в Інтернеті, якщо вам не подобається, що треті сторони мають до неї доступ, хоча загальнодоступну інформацію у ваших профілях, можливо, вже було вилучено.
На жаль, ми як звичайні користувачі можемо зробити дуже багато, щоб захистити свої дані від компаній ШІ. Справжній контроль над цією інформацією, ймовірно, прийде лише за допомогою регуляторів.