

У цій статті ми обговоримо векторизацію – техніку НЛП, і зрозуміємо її значення за допомогою вичерпного посібника з різних типів векторизації.
Ми обговорили основні концепції попередньої обробки NLP і очищення тексту. Ми розглянули основи НЛП, різні його застосування та методи, такі як токенізація, нормалізація, стандартизація та очищення тексту.

Перш ніж обговорювати векторизацію, давайте переглянемо, що таке токенізація та чим вона відрізняється від векторизації.
Що таке токенізація?
Токенізація — це процес поділу речень на менші одиниці, які називаються лексемами. Токен допомагає комп’ютерам легко розуміти текст і працювати з ним.
ПРИКЛ. “Ця стаття хороша”
Жетони- [‘This’, ‘article’, ‘is’, ‘good’.]
Що таке векторизація?
Як ми знаємо, моделі та алгоритми машинного навчання розуміють числові дані. Векторизація — це процес перетворення текстових або категоріальних даних у числові вектори. Перетворюючи дані в числові дані, ви можете точніше навчити свою модель.
Навіщо нам потрібна векторизація?
❇️ Токенізація та векторизація мають різне значення в обробці природної мови (NPL). Токенізація розбиває речення на невеликі лексеми. Векторизація перетворює його в числовий формат, щоб комп’ютер/модель ML міг це зрозуміти.
❇️ Векторизація корисна не лише для перетворення його в числову форму, але також корисна для захоплення семантичного значення.
❇️ Векторизація може зменшити розмірність даних і зробити їх більш ефективними. Це може бути дуже корисним під час роботи з великим набором даних.
❇️ Багато алгоритмів машинного навчання вимагають числового введення, як-от нейронні мережі, тому нам може допомогти векторизація.
Існують різні типи технік векторизації, про які ми розповімо в цій статті.
Сумка слів
Якщо у вас є купа документів або речень, і ви хочете їх проаналізувати, Bag of Words спростить цей процес, розглядаючи документ як мішок, наповнений словами.
Підхід «мішок слів» може бути корисним для класифікації тексту, аналізу настроїв і пошуку документів.
Припустимо, ви працюєте над великою кількістю тексту. Сумка слів допоможе вам представити текстові дані, створивши словник унікальних слів у наших текстових даних. Після створення словника він кодуватиме кожне слово як вектор на основі частоти (як часто кожне слово з’являється в тексті) цих слів.
Ці вектори складаються з невід’ємних чисел (0,1,2…..), які представляють кількість частот у цьому документі.
Сумка слів складається з трьох кроків:
Крок 1: Токенізація
Він розбиватиме документи на токени.
Ex – (Речення: «Я люблю піцу і люблю бургери»)
Крок 2: унікальне розділення слів/створення словника
Створіть список усіх унікальних слів, які зустрічаються у ваших реченнях.
[“I”, “love”, “Pizza”, “and”, “Burgers”]
Крок 3: Підрахунок входжень слів/створення вектора
На цьому кроці буде підраховано, скільки разів повторюється кожне слово зі словника, і збережено в розрідженій матриці. У розрідженій матриці кожен рядок у векторі речень, довжина якого (стовпці матриці) дорівнює розміру словника.
Імпорт CountVectorizer
Ми збираємося імпортувати CountVectorizer для навчання нашої моделі Bag of words
from sklearn.feature_extraction.text import CountVectorizer
Створіть векторизатор
На цьому кроці ми збираємося створити нашу модель за допомогою CountVectorizer і навчити її за допомогою нашого зразка текстового документа.
# Sample text documents
documents = [
"This is the first document.",
"This document is the second document.",
"And this is the third one.",
"Is this the first document?",
]
# Create a CountVectorizer
cv = CountVectorizer()
# Fit and Transform X = cv.fit_transform(documents)
Перетворення в щільний масив
На цьому кроці ми перетворимо наші представлення в щільний масив. Крім того, ми отримаємо назви функцій або слова.
# Get the feature names/words feature_names = vectorizer.get_feature_names_out() # Convert to dense array X_dense = X.toarray()
Давайте надрукуємо матрицю термінів документа та характерні слова
# Print the DTM and feature names
print("Document-Term Matrix (DTM):")
print(X_dense)
print("\nFeature Names:")
print(feature_names)
Документ – матриця термінів (DTM):
 Матриця
Матриця
Назви функцій:
 Особливі слова
Особливі слова
Як ви бачите, вектори складаються з невід’ємних чисел (0,1,2……), які представляють частоту слів у документі.
У нас є чотири зразки текстових документів, і ми визначили дев’ять унікальних слів із цих документів. Ми зберегли ці унікальні слова в нашому словнику, присвоївши їм «Назви функцій».
Потім наша модель Bag of Words перевіряє, чи присутнє перше унікальне слово в нашому першому документі. Якщо він присутній, він присвоює значення 1, інакше він призначає 0.
Якщо слово з’являється кілька разів (наприклад, 2 рази), воно присвоює відповідне значення.
Наприклад, у другому документі слово «документ» повторюється двічі, тому його значення в матриці буде 2.
Якщо ми хочемо окреме слово як функцію в ключі словника – представлення Unigram.
n – грами = уніграми, біграми…….тощо.
Існує багато бібліотек, таких як scikit-learn, для реалізації пакета слів: Keras, Gensim та інші. Це просто і може бути корисним у різних випадках.
Але Bag of words працює швидше, але має деякі обмеження.
Щоб вирішити цю проблему, ми можемо вибрати кращі підходи, одним із них є TF-IDF. Давайте, розберемося докладніше.
TF-IDF
TF-IDF, або частота термінів – зворотна частота документа, – це числове представлення для визначення важливості слів у документі.
Навіщо нам TF-IDF замість Bag of Words?
Сумка слів обробляє всі слова однаково, і лише стосується частоти унікальних слів у реченнях. TF-IDF надає важливості словам у документі, враховуючи як частоту, так і унікальність.
Слова, які повторюються надто часто, не переважають над менш частими та більш важливими словами.
TF: Частота термінів визначає, наскільки важливе слово в одному реченні.
IDF: Зворотна частота документа визначає, наскільки важливе слово у всій колекції документів.
TF = частота слів у документі / загальна кількість слів у цьому документі
DF = Документ, що містить слово w / Загальна кількість документів
IDF = журнал (Загальна кількість документів / Документи, що містять слово w)
IDF є величиною, зворотною DF. Причина цього полягає в тому, що чим частіше це слово зустрічається в усіх документах, тим менше його значення в поточному документі.
Остаточний рахунок TF-IDF: TF-IDF = TF * IDF
Це спосіб дізнатися, які слова є загальними в одному документі та унікальними для всіх документів. Ці слова можуть бути корисними для пошуку основної теми документа.
Наприклад,
Doc1 = «Я люблю машинне навчання»
Doc2 = «Я люблю techukraine.net»
Ми повинні знайти матрицю TF-IDF для наших документів.
Спочатку ми створимо словниковий запас унікальних слів.
Словниковий запас = [“I,” “love,” “machine,” “learning,” “Geekflare”]
Отже, маємо 5 п’ять слів. Давайте знайдемо TF і IDF для цих слів.
TF = частота слів у документі / загальна кількість слів у цьому документі
TF:
- Для «I» = TF для Doc1: 1/4 = 0,25 і для Doc2: 1/3 ≈ 0,33
- Для «любові»: TF для Doc1: 1/4 = 0,25 і для Doc2: 1/3 ≈ 0,33
- Для «Машини»: TF для Doc1: 1/4 = 0,25 і для Doc2: 0/3 ≈ 0
- Для «Навчання»: TF для Doc1: 1/4 = 0,25 і для Doc2: 0/3 ≈ 0
- Для «techukraine.net»: TF для Doc1: 0/4 = 0 і для Doc2: 1/3 ≈ 0,33
Тепер обчислимо IDF.
IDF = журнал (Загальна кількість документів / Документи, що містять слово w)
IDF:
- Для «I»: IDF дорівнює log(2/2) = 0
- Для «любові»: IDF дорівнює log(2/2) = 0
- Для «Машини»: IDF дорівнює log(2/1) = log(2) ≈ 0,69
- Для «навчання»: IDF дорівнює log(2/1) = log(2) ≈ 0,69
- Для «techukraine.net»: IDF дорівнює log(2/1) = log(2) ≈ 0,69
Тепер розрахуємо остаточний бал TF-IDF:
- Для «I»: TF-IDF для Doc1: 0,25 * 0 = 0 і TF-IDF для Doc2: 0,33 * 0 = 0
- Для «любові»: TF-IDF для Doc1: 0,25 * 0 = 0 і TF-IDF для Doc2: 0,33 * 0 = 0
- Для «Машини»: TF-IDF для Doc1: 0,25 * 0,69 ≈ 0,17 і TF-IDF для Doc2: 0 * 0,69 = 0
- Для «Навчання»: TF-IDF для Doc1: 0,25 * 0,69 ≈ 0,17 і TF-IDF для Doc2: 0 * 0,69 = 0
- Для «techukraine.net»: TF-IDF для Doc1: 0 * 0,69 = 0 і TF-IDF для Doc2: 0,33 * 0,69 ≈ 0,23
Матриця TF-IDF виглядає так:
I love machine learning techukraine.net Doc1 0.0 0.0 0.17 0.17 0.0 Doc2 0.0 0.0 0.0 0.0 0.23
Значення в матриці TF-IDF говорять про те, наскільки важливим є кожен термін у кожному документі. Високі значення вказують на те, що термін є важливим у конкретному документі, тоді як низькі значення вказують на те, що термін є менш важливим або поширеним у цьому контексті.
TF-IDF здебільшого використовується для класифікації тексту, створення інформаційного пошуку чат-бота та підсумовування тексту.
Імпорт TfidfVectorizer
Давайте імпортуємо TfidfVectorizer із sklearn
from sklearn.feature_extraction.text import TfidfVectorizer
Створіть векторизатор
Як ви бачите, ми створимо нашу модель Tf Idf за допомогою TfidfVectorizer.
# Sample text documents
text = [
"This is the first document.",
"This document is the second document.",
"And this is the third one.",
"Is this the first document?",
]
# Create a TfidfVectorizer
cv = TfidfVectorizer()
Створіть матрицю TF-IDF
Давайте навчимо нашу модель, надаючи текст. Після цього ми перетворимо репрезентативну матрицю в щільний масив.
# Fit and transform to create the TF-IDF matrix X = cv.fit_transform(text)
# Get the feature names/words feature_names = vectorizer.get_feature_names_out() # Convert the TF-IDF matrix to a dense array for easier manipulation (optional) X_dense = X.toarray()
Надрукуйте матрицю TF-IDF і характерні слова
# Print the TF-IDF matrix and feature words
print("TF-IDF Matrix:")
print(X_dense)
print("\nFeature Names:")
print(feature_names)
Матриця TF-IDF:
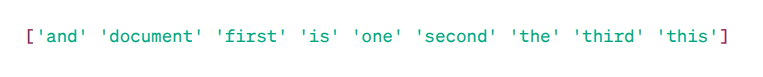 Особливі слова
Особливі слова
Як бачите, ці десяткові цілі числа вказують на важливість слів у конкретних документах.
Крім того, ви можете поєднувати слова в групи по 2,3,4 і так далі за допомогою n-грам.
Є й інші параметри, які ми можемо включити: min_df, max_feature, subliner_tf тощо.
Дотепер ми досліджували основні частотні методи.
Але TF-IDF не може забезпечити семантичне значення та контекстне розуміння тексту.
Давайте розберемося з більш досконалими техніками, які змінили світ вбудовування слів і які кращі для семантичного значення та розуміння контексту.
Word2Vec
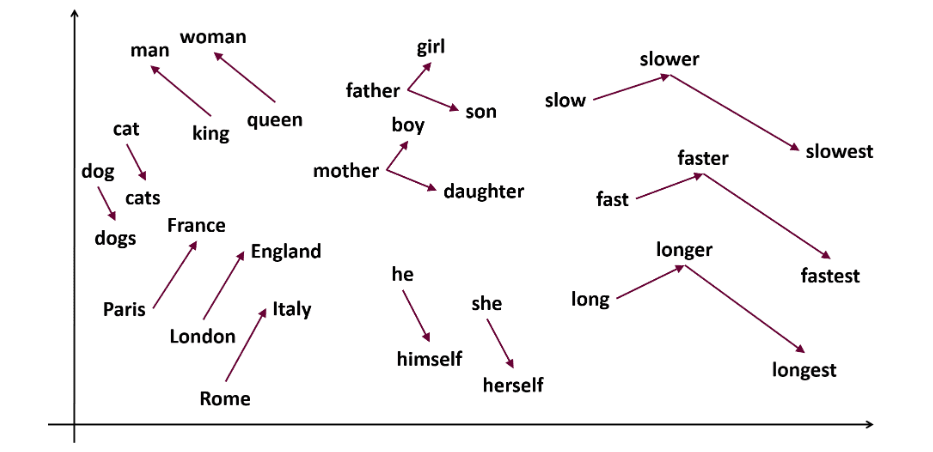
Word2vec є популярним вкладання слів (тип вектора слів і корисний для фіксації семантичної та синтаксичної подібності) техніка в НЛП. Він був розроблений Томасом Міколовим і його командою з Google у 2013 році. Word2vec представляє слова як безперервні вектори в багатовимірному просторі.
Word2vec має на меті представити слова таким чином, щоб передати їх семантичне значення. Вектори Word, згенеровані word2vec, розташовані в безперервному векторному просторі.
Наприклад, вектори «Кіт» і «Собака» будуть ближчими, ніж вектори «кіт» і «дівчина».
 Джерело: usna.edu
Джерело: usna.edu
Word2vec може використовувати дві архітектури моделі для створення вбудовування слів.
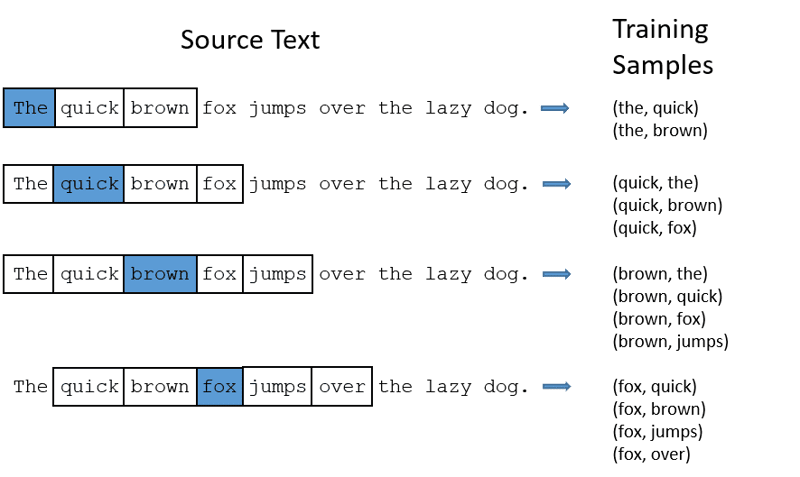
CBOW: Continuous bag of words або CBOW намагається передбачити слово, усереднюючи значення сусідніх слів. Він приймає фіксовану кількість або вікно слів навколо цільового слова, потім перетворює його в числову форму (вбудовування), потім усереднює все та використовує це середнє для прогнозування цільового слова за допомогою нейронної мережі.
Екс-передбачена ціль: “Лисиця”
Слова речення: “The”, “quick”, “brown”, “jumps”, “over”, “the”
 Word2Vec
Word2Vec
- CBOW приймає вікно фіксованого розміру (кількість) слів, наприклад 2 (2 ліворуч і 2 праворуч)
- Перетворення на вбудовування слів.
- CBOW усереднює вбудовування слів.
- CBOW усереднює вбудовування слова в контекстні слова.
- Усереднений вектор намагається передбачити цільове слово за допомогою нейронної мережі.
Тепер давайте розберемося, чим skip-gram відрізняється від CBOW.
Skip-gram: це модель вбудовування слів, але вона працює інакше. Замість передбачення цільового слова, skip-gram передбачає контекстні слова, задані цільовими словами.
Skip-grams краще вловлює семантичні зв’язки між словами.
Колишній «король – чоловіки + жінки = королева»
Якщо ви хочете працювати з Word2Vec, у вас є два варіанти: ви можете навчити власну модель або використати попередньо навчену модель. Ми будемо проходити через попередньо навчену модель.
Імпорт gensim
Ви можете встановити gensim за допомогою pip install:
pip install gensim
Токенізуйте речення за допомогою word_tokenize:
СПОЧАТКУ ми перетворимо речення на нижчі. Після цього ми будемо токенізувати наші речення за допомогою word_tokenize.
# Import necessary libraries
from gensim.models import Word2Vec
from nltk.tokenize import word_tokenize
# Sample sentences
sentences = [
"I love thor",
"Hulk is an important member of Avengers",
"Ironman helps Spiderman",
"Spiderman is one of the popular members of Avengers",
]
# Tokenize the sentences
tokenized_sentences = [word_tokenize(sentence.lower()) for sentence in sentences]
Давайте навчимо нашу модель:
Ми навчимо нашу модель, надавши лексифіковані речення. Ми використовуємо 5 вікон для цієї моделі навчання, ви можете адаптувати відповідно до ваших вимог.
# Train a Word2Vec model
model = Word2Vec(sentences=tokenized_sentences, vector_size=100, window=5, min_count=1, sg=0)
# Find similar words
similar_words = model.wv.most_similar("avengers")
# Print similar words
print("Similar words to 'avengers':")
for word, score in similar_words:
print(f"{word}: {score}")
Слова, схожі на «месники»:
 Подібність Word2Vec
Подібність Word2Vec
Це деякі зі слів, які схожі на «месники» на основі моделі Word2Vec, а також їхні оцінки схожості.
Модель обчислює оцінку подібності (здебільшого косинусну подібність) між векторами слів «месники» та іншими словами у своєму словнику. Оцінка подібності вказує на те, наскільки тісно пов’язані два слова у векторному просторі.
колишній –
Тут слово «допомагає» зі схожістю косинуса -0,005911458611011982 зі словом «месники». Від’ємне значення означає, що вони можуть бути несхожими один на одного.
Значення подібності косинусів коливаються від -1 до 1, де:
- 1 означає, що два вектори ідентичні та мають позитивну подібність.
- Значення, близькі до 1, вказують на високу позитивну подібність.
- Значення, близькі до 0, вказують на те, що вектори не сильно пов’язані.
- Значення, близькі до -1, вказують на високу несхожість.
- -1 вказує на те, що два вектори абсолютно протилежні та мають ідеальну негативну подібність.
Відвідайте це посилання якщо ви хочете краще зрозуміти моделі word2vec і візуальне представлення того, як вони працюють. Це дійсно чудовий інструмент для спостереження за CBOW і skip-gram у дії.
Подібно до Word2Vec, у нас є GloVe. GloVe може створювати вбудовування, які потребують менше пам’яті порівняно з Word2Vec. Давайте розберемося більше про GloVe.
GloVe
Глобальні вектори для представлення слів (GloVe) — це техніка, подібна до word2vec. Він використовується для представлення слів як векторів у безперервному просторі. Концепція GloVe така ж, як у Word2Vec: вона створює контекстне вбудовування слів, враховуючи чудову продуктивність Word2Vec.
Навіщо нам GloVe?
Word2vec — це віконний метод, який використовує сусідні слова для розуміння слів. Це означає, що на семантичне значення цільового слова впливають лише навколишні слова в реченнях, що є неефективним використанням статистики.
У той час як GloVe фіксує як глобальну, так і локальну статистику з додаванням слів.
Коли використовувати GloVe?
Використовуйте GloVe, якщо вам потрібно вбудовування слів, яке фіксує ширші семантичні зв’язки та глобальні асоціації слів.
GloVe кращий за інші моделі в задачах розпізнавання іменованих об’єктів, аналогії слів і схожості слів.
Спочатку нам потрібно встановити Gensim:
pip install gensim
Крок 1: ми збираємося встановити важливі бібліотеки
# Import the required libraries import numpy as np import matplotlib.pyplot as plt from sklearn.manifold import TSNE import gensim.downloader as api
Крок 2. Імпортуйте модель рукавички
import gensim.downloader as api
glove_model = api.load('glove-wiki-gigaword-300')
Крок 3. Отримайте векторне представлення слова для слова “милий”
glove_model["cute"]
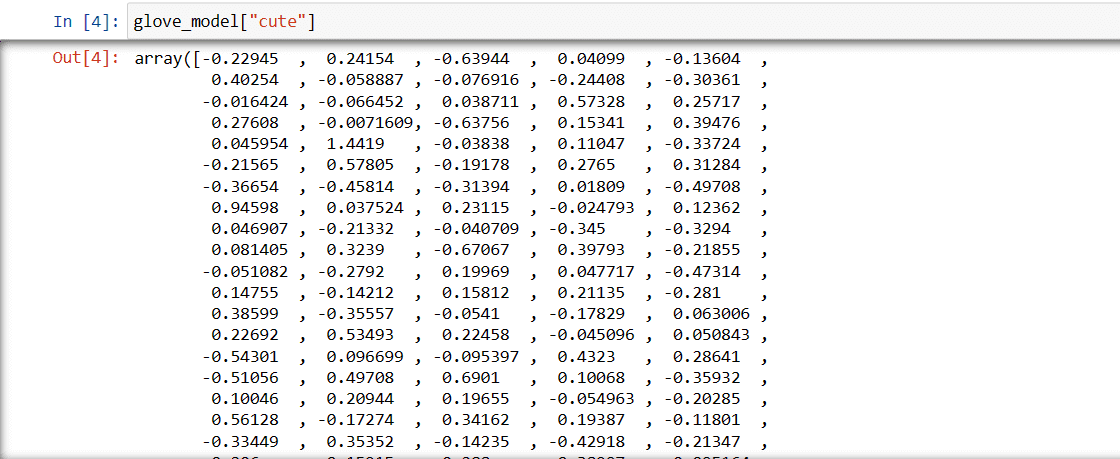 Вектор для слова “милий”
Вектор для слова “милий”
Ці значення фіксують значення слова та його зв’язки з іншими словами. Позитивні значення вказують на позитивні асоціації з певними поняттями, тоді як негативні значення вказують на негативні асоціації з іншими поняттями.
У моделі GloVe кожен вимір у векторі слів представляє певний аспект значення або контексту слова.
Негативні та позитивні значення в цих вимірах впливають на те, наскільки «милий» семантично пов’язаний з іншими словами у словнику моделі.
Для різних моделей значення можуть бути різними. Давайте знайдемо слова, схожі на слово “хлопець”
Топ-10 схожих слів, які модель вважає найбільш схожими на слово “хлопець”
# find similar word
glove_model.most_similar("boy")
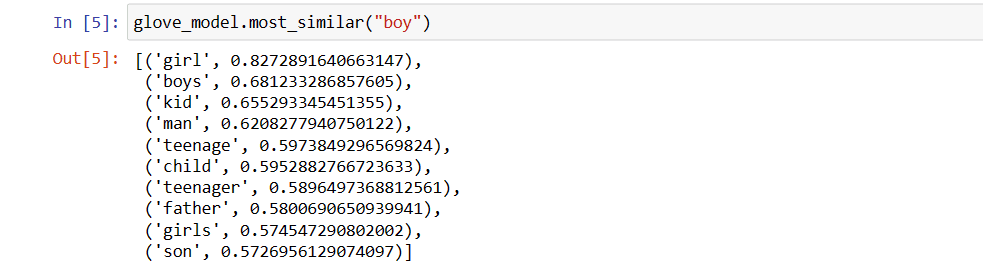 10 найпопулярніших слів, схожих на “хлопець”
10 найпопулярніших слів, схожих на “хлопець”
Як бачите, слово «хлопчик» найбільш схоже на слово «дівчинка».
Тепер ми спробуємо знайти, наскільки точно модель отримає семантичне значення від поданих слів.
glove_model.most_similar(positive=['boy', 'queen'], negative=['girl'], topn=1)
 Найактуальніше слово для “королев”
Найактуальніше слово для “королев”
Наша модель здатна знаходити ідеальний зв’язок між словами.
Визначте список слів:
Тепер давайте спробуємо зрозуміти семантичне значення або зв’язок між словами за допомогою сюжету. Визначте список слів, які ви хочете візуалізувати.
# Define the list of words you want to visualize vocab = ["boy", "girl", "man", "woman", "king", "queen", "banana", "apple", "mango", "cow", "coconut", "orange", "cat", "dog"]
Створіть матрицю вбудовування:
Давайте напишемо код для створення матриці вбудовування.
# Your code for creating the embedding matrix
EMBEDDING_DIM = glove_model.vectors.shape[1]
word_index = {word: index for index, word in enumerate(vocab)}
num_words = len(vocab)
embedding_matrix = np.zeros((num_words, EMBEDDING_DIM))
for word, i in word_index.items():
embedding_vector = glove_model[word]
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
Визначте функцію для візуалізації t-SNE:
З цього коду ми визначимо функцію для нашої діаграми візуалізації.
def tsne_plot(embedding_matrix, words):
tsne_model = TSNE(perplexity=3, n_components=2, init="pca", random_state=42)
coordinates = tsne_model.fit_transform(embedding_matrix)
x, y = coordinates[:, 0], coordinates[:, 1]
plt.figure(figsize=(14, 8))
for i, word in enumerate(words):
plt.scatter(x[i], y[i])
plt.annotate(word,
xy=(x[i], y[i]),
xytext=(2, 2),
textcoords="offset points",
ha="right",
va="bottom")
plt.show()
Подивимося, як виглядає наш сюжет:
# Call the tsne_plot function with your embedding matrix and list of words tsne_plot(embedding_matrix, vocab)
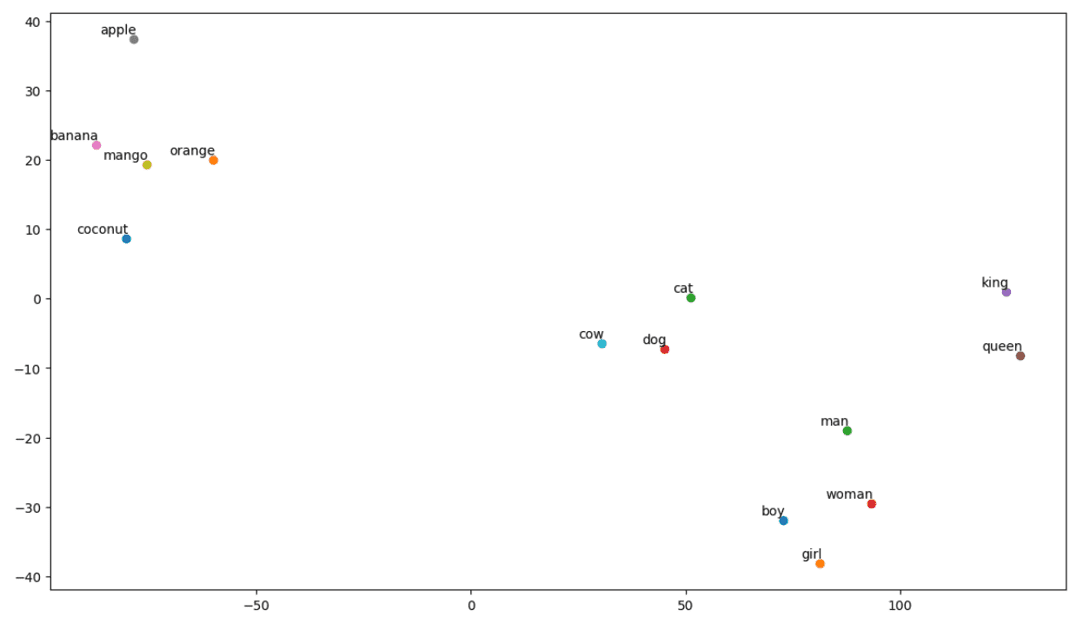 графік t-SNE
графік t-SNE
Отже, як ми бачимо, у лівій частині нашого графіка є такі слова, як «банан», «манго», «апельсин», «кокос» і «яблуко». Тоді як «корова», «собака» і «кішка» схожі один на одного, тому що вони тварини.
Отже, наша модель також може знаходити семантичне значення та зв’язки між словами!
Просто змінивши слово або створивши свою модель з нуля, ви можете експериментувати з різними словами.
Ви можете використовувати цю матрицю вбудовування як завгодно. Його можна застосувати лише до завдань зі схожості слів або подати на рівень вбудовування нейронної мережі.
GloVe навчається на матриці спільного виникнення, щоб отримати семантичне значення. Він ґрунтується на ідеї, що співпадання слів і слів є важливою частиною знань і що їх використання є ефективним способом використання статистики для створення вставок слів. Ось як GloVe додає «глобальну статистику» до кінцевого продукту.
І це GloVe; Іншим популярним методом векторизації є FastText. Давайте обговоримо це докладніше.
FastText
FastText — це бібліотека з відкритим вихідним кодом, представлена дослідницькою командою Facebook AI Research для класифікації тексту та аналізу настроїв. FastText надає інструменти для навчання вбудовуванню слів, які є щільним векторним представленням слів. Це корисно для фіксації семантичного значення документа. FastText підтримує класифікацію як з кількома мітками, так і з кількома класами.
Чому FastText?
FastText кращий за інші моделі через його здатність узагальнювати невідомі слова, чого не було в інших методах. FastText надає попередньо підготовлені вектори слів для різних мов, що може бути корисним у різних завданнях, де нам потрібні попередні знання про слова та їх значення.
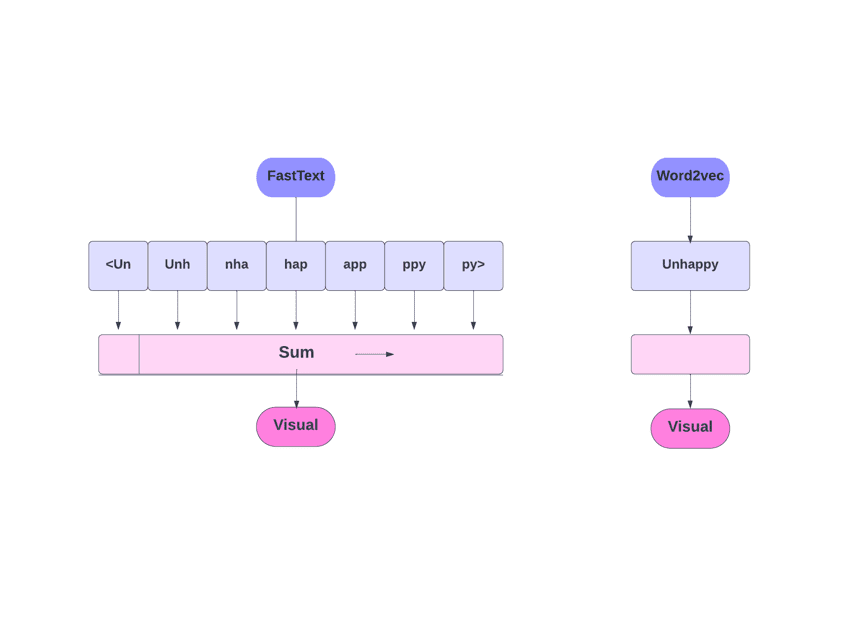 FastText проти Word2Vec
FastText проти Word2Vec
Як це працює?
Як ми обговорювали, інші моделі, такі як Word2Vec і GloVe, використовують слова для вбудовування слів. Але будівельним блоком FastText є букви замість слів. Це означає, що вони використовують літери для вставлення слів.
Використання символів замість слів має ще одну перевагу. Для навчання потрібно менше даних. Коли слово стає своїм контекстом, у результаті з тексту можна отримати більше інформації.
Вбудовування Word, отримане за допомогою FastText, є комбінацією вбудовування нижчого рівня.
Тепер давайте подивимося, як FastText використовує інформацію про підслова.
Скажімо, у нас є слово «читання». Для цього слова n-грами символів довжиною 3-6 будуть згенеровані таким чином:
- Початок і кінець позначаються кутовими дужками.
- Хешування використовується тому, що може бути велика кількість n-грамів; замість того, щоб вивчати вкладення для кожної окремої n-грами, ми вивчаємо загальну кількість вбудовань B, де B означає розмір відра. В оригінальному папері використовувався розмір відра 2 мільйони.
- Кожна символьна n-грама, наприклад «eadi», відображається на ціле число від 1 до B за допомогою цієї функції хешування, і цей індекс має відповідне вбудовування.
- Шляхом усереднення цих складових вкладень n-грамів отримують повне вкладення слів.
- Навіть якщо цей підхід до хешування призводить до колізій, він значною мірою допомагає обробляти розмір словника.
- Мережа, яка використовується у FastText, подібна до Word2Vec. Як і там, ми можемо навчити FastText у двох режимах – CBOW і skip-gram. Таким чином, нам не потрібно повторювати цю частину тут знову.
Ви можете навчити свою власну модель або використовувати попередньо навчену модель. Ми будемо використовувати попередньо навчену модель.
Спочатку вам потрібно встановити FastText.
pip install fasttext
Ми будемо використовувати набір даних, який складається з розмовного тексту про кілька наркотиків, і ми повинні класифікувати ці тексти на 3 типи. Як і з видами наркотиків, з якими вони пов’язані.
 Набір даних
Набір даних
Тепер, щоб навчити модель FastText на будь-якому наборі даних, нам потрібно підготувати вхідні дані в певному форматі, а саме:
__label__<значення мітки><пробіл><пов’язана точка даних>
Давайте також зробимо це для нашого набору даних.
all_texts = train['text'].tolist()
all_labels = train['drug type'].tolist()
prep_datapoints=[]
for i in range(len(all_texts)):
sample="__label__"+ str(all_labels[i]) + ' '+ all_texts[i]
prep_datapoints.append(sample)
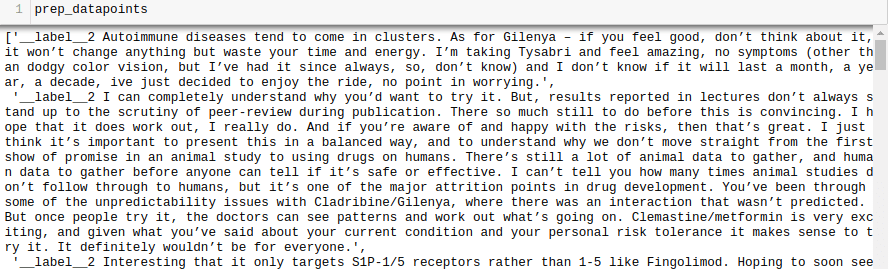 prep_datapoints
prep_datapoints
На цьому кроці ми пропустили багато попередньої обробки. Інакше наша стаття буде занадто великою. У реальних задачах найкраще виконати попередню обробку, щоб зробити дані придатними для моделювання.
Тепер запишіть підготовлені точки даних у файл .txt.
with open('train_fasttext.txt','w') as f:
for datapoint in prep_datapoints:
f.write(datapoint)
f.write('n')
f.close()
Давайте навчимо нашу модель.
model = fasttext.train_supervised('train_fasttext.txt')
Ми отримаємо прогнози з нашої моделі.

Модель передбачає мітку та призначає їй оцінку надійності.
Як і у випадку з будь-якою іншою моделлю, продуктивність цієї моделі залежить від різноманітних змінних, але якщо ви хочете отримати швидке уявлення про очікувану точність, FastText може бути чудовим вибором.
Висновок
Підсумовуючи, такі методи векторизації тексту, як Bag of Words (BoW), TF-IDF, Word2Vec, GloVe та FastText, надають різноманітні можливості для завдань NLP.
У той час як Word2Vec фіксує семантику слів і адаптується для різноманітних завдань НЛП, BoW і TF-IDF прості та підходять для класифікації тексту та рекомендацій.
Для програм, таких як аналіз настроїв, GloVe пропонує попередньо навчені вбудовування, а FastText добре справляється з аналізом на рівні підслова, що робить його корисним для структурно складних мов і розпізнавання сутностей.
Вибір техніки залежить від завдання, даних і ресурсів. Ми глибше обговорюватимемо складність НЛП у ході цієї серії. Щасливого навчання!
Далі перегляньте найкращі курси НЛП, щоб навчитися обробці природної мови.