

План аварійного відновлення — це першочерговий захід, який організація повинна мати перед тим, як її спіткає незвичайна подія.
В ІТ-індустрії це починається зі створення офіційного документа, що містить плани, дії та процедури боротьби з катастрофою та її наслідками.
Катастрофа — це подія, яка виникає раптово, без попереднього повідомлення, і може бути різного типу. І коли це трапляється, окремі особи та організації стикаються з різними труднощами, включаючи фінансові проблеми та досвід користувача.
Якщо станеться атака, ви повинні бути готові мінімізувати її наслідки та швидше відновити роботу. Саме тут підготовка практичного плану аварійного відновлення допоможе вам утримати або запобігти катастрофі. Ви також можете зменшити його наслідки з точки зору взаємодії з користувачем, вартості та часу простою.
Крім того, ви повинні тримати свої плани, людей, стратегії, обладнання та системи готовими, щоб повернути все в дію. Але для цього ви повинні глибоко розуміти аварійне відновлення.
У цій статті я детально обговорю це разом із ключовою термінологією аварійного відновлення, щоб ви могли сміливо відбиватися та вийти сильнішими в таких несприятливих умовах.
Давайте почнемо!
Що таке катастрофа?
Катастрофа — це непередбачена подія, яка може статися де завгодно, включно з ІТ-індустрією. Це відбувається або природним шляхом, або людьми і може заважати діяльності компанії та порушувати структуру інфраструктури.
В результаті цього страждає організація та її клієнти, постачальники, співробітники та партнери. Це створює тиск на організацію з точки зору фінансів, репутації галузі, довіри клієнтів і периметра безпеки.
Тому ви повинні бути заздалегідь готові подолати такий сценарій. Для цього вам потрібно миттєво відновити кожну операцію та дані. Простими словами, ви повинні підготувати свою організацію до того, щоб відновити все в найкоротші терміни для ваших клієнтів.
Лиха бувають багатьох типів, наприклад кібератаки, диверсії, терористичні атаки, програми-вимагачі або фізичні загрози, урагани, землетруси, пожежі, повені, промислові аварії, збої в електропостачанні та багато іншого.
Що ви маєте на увазі під аварійним відновленням?

Аварійне відновлення — це процес відновлення нормальної роботи після катастрофи. Це передбачає відновлення доступу до апаратного забезпечення, програмного забезпечення, обладнання, підключення, мережі, живлення та даних. Ви повинні встановити правила та процедури в документально оформленому процесі, щоб підготувати вашу організацію до катастрофи.
Однак, якщо об’єкти вашої організації знищені, ви повинні розширити деякі види діяльності, попрацювавши над зв’язком, транспортом, пошуком джерел, робочими місцями тощо.
Чому план аварійного відновлення важливий?
Розробка ідеального плану відновлення після стихійного лиха або спричиненого людиною катастрофи є важливою для кожної галузі ІТ. Переконайтеся, що у вас є потрібний працівник і інструменти в потрібному місці, щоб безперешкодно виконати план.
Давайте глибше розберемося, чому аварійне відновлення має вирішальне значення.
Обмеження збитків
Катастрофа непередбачувана. Ніхто не знає, коли воно приходить і йде. Але ви заздалегідь готуєтеся контролювати шкоду, завдану вашій інфраструктурі.
Наприклад, у затоплених районах ви можете розмістити свої основні документи та різне обладнання на верхньому поверсі, щоб уникнути пошкодження.
Так само зробіть резервну копію своїх важливих даних, перш ніж кібератаки можуть зламати дані або викрасти їх.
Послуги відновлення
Якщо ви підготуєте надійний план відновлення після аварії, відновити всі служби до нормального вигляду можна швидко й легко. Це означає, що за короткий проміжок часу ви можете відновити майже всі основні активи та послуги.
Мінімізуйте переривання
Ви не можете знати, що станеться завтра чи на наступному етапі операції. Але з ідеальним планом відновлення вам не доведеться особливо турбуватися про наслідки. Ваша інфраструктура може продовжувати роботу з мінімальними перервами.
Навчання та підготовка

ІТ-інфраструктура складається з багатьох співробітників, які працюють під дахом. Усі повинні знати про відновлення, щоб негайно діяти відповідно до вимог і очікувань у разі надзвичайної ситуації.
Правильна підготовка також знизить рівень стресу для всіх, хто пов’язаний з вашою організацією. Крім того, ви можете навчити своїх співробітників вживати необхідних дій у разі несподіваної події.
Термінології аварійного відновлення
Почнемо з термінології, щоб ближче зрозуміти аварійне відновлення.
RTO
Цільовий час відновлення (RTO) – це кількість часу, яку організація встановлює відповідно до характеру бізнесу, щоб витримати катастрофу без впливу на фінансове зростання.
Встановлюючи RTO, компанія повинна перевірити простої, які можуть вплинути на вашу організацію різними способами. Він використовується для вивчення життєздатних стратегій продовження ваших бізнес-операцій навіть після катастрофи. Коли клієнти стикаються з будь-якими порушеннями в роботі програми, вони запитують, скільки часу знадобиться програмі, щоб повернутися до дії. Відповідь: RTO для кожної організації.
Приклад. Припустімо, що ви є компанією, що займається онлайн-транзакціями, наприклад PayPal або Pioneer, і стикаєтеся з непередбачуваними подіями. У цьому випадку ваш RTO буде достатньо швидким, щоб відновити операцію.
Іншими словами, компанія встановлює RTO на годину або дві, щоб уникнути наслідків у вигляді фінансів або даних.
РРО
Цілі точки відновлення (RPO) — це втрата даних, яку ІТ-інфраструктура може впоратися з точки зору часу та обсягу інформації.
Збиває з пантелику?
Візьмемо приклад бази даних, яка записує транзакції банку, включаючи перекази, планування, платежі тощо. Коли трапляється катастрофа, база даних відновлюється в режимі реального часу. Різниця між базою даних на момент аварії та відновленням бази даних після аварії в цьому випадку дорівнює нулю.
Для деяких компаній допустимо витратити близько 24 годин на відновлення всієї інформації з резервної копії, але іноді це може бути катастрофічним. Важливо налаштувати свою інфраструктуру відповідно до вимог RPO. Це включає підвищення частоти резервного копіювання, додавання резервної бази даних до вашої архітектури тощо.
Перехід після відмови
Згадайте ситуацію, коли ви їдете на велику відстань. Раптом у вас спустило колесо з якоїсь несподіваної причини. Ви дякуєте за наявну у вашому автомобілі запасну шину та інструменти для заміни несправної шини.
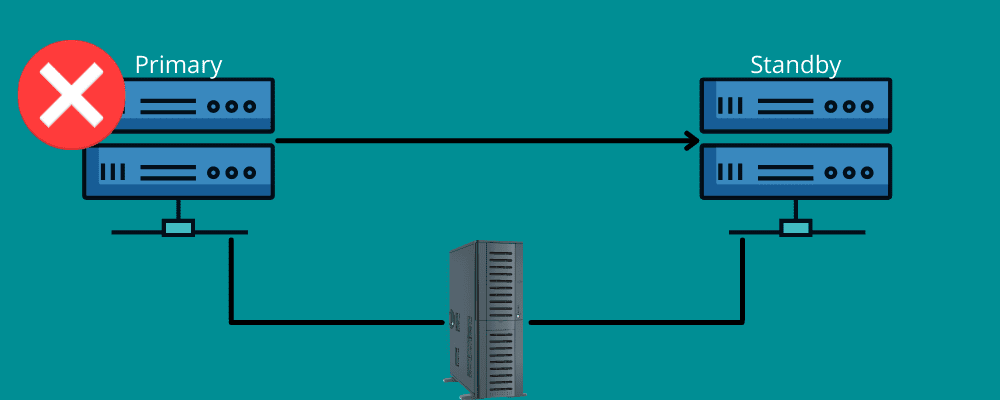
Відмова працює таким же чином.
Це означає, що вам потрібне резервне з’єднання під час катастрофи. У двох словах, відновлення після збоїв означає наявність мереж і систем, які можна використовувати під час аварії для перемикання вашої інформації в систему відновлення.
Відмовостійкість гарантує безперебійну роботу всіх ваших служб, навіть якщо виникають інфраструктурні або апаратні збої. Таким чином ви можете запобігти втраті даних і прибутку вашою організацією та уникнути збоїв у роботі кінцевих користувачів.
Ви можете встановити його вручну або дозволити йому функціонувати автоматично для переміщення даних на резервний сервер.
Відмова
ІТ-відмовлення — це проста операція, під час якої початкове виробництво повертається на своє початкове місце (систему) після усунення аварії. Під час атаки компанії виконують операцію відновлення після відмови, завдяки якій усі робочі навантаження переходять до репліки віртуальної машини або системи резервного копіювання.
Однак ви не можете просто пропустити наступний крок повернення. Коли ви все відновите та повернетеся до роботи, вам потрібно буде перенести всі робочі навантаження на їхні вихідні віртуальні машини або системи. Цей загальний процес повернення робочих навантажень на початкове робоче місце або систему відомий як відновлення після відмови. Це означає, що ви «повертаєтеся» після нападу.
Повернення до відмови також використовується для планового технічного обслуговування підприємства. Це правда, що відновлення після відмови завжди відбувається після відмови. Іншими словами, відновлення після збою — це перший крок, а відновлення — другий крок у відновленні важливих даних. Його можна налаштувати між хмарою та хмарою, локально на локально, локально на хмару або будь-яку комбінацію з цих.
ЛІКАР
Аварійне відновлення (DR) — це процес, у якому у вас є заздалегідь розроблені плани відновлення ваших активів у визначений термін.
DR дає можливість організації швидко реагувати та відновлювати кожну послугу після несподіваної події. Він також надає офіційну документацію, яка містить інструкції щодо вжиття негайних дій у разі непередбачених інцидентів.
BCP
План безперервності бізнесу (BCP) — це один із найбільш прийнятних планів аварійного відновлення, який дозволяє ІТ-інфраструктурі розробляти стратегії для обробки ІТ-збоїв у роботі серверів, мобільних пристроїв, персональних комп’ютерів і мереж.
BCP дещо відрізняється від аварійного відновлення, оскільки допомагає організації будувати плани щодо відновлення корпоративного програмного забезпечення та продуктивності для задоволення ключових потреб бізнесу.
Тут компанія створює систему відновлення для подолання потенційних загроз, таких як кібератаки чи стихійні лиха. Він призначений для забезпечення безпеки активів і забезпечення швидкого відновлення роботи всіх служб після страйку.
BCM

Управління безперервністю бізнесу (BCM) — це процес управління ризиками, спеціально розроблений для захисту від загроз для бізнес-процесів. BCM є наступним кроком BCP, де він перевіряє плани відновлення, щоб переконатися, що всі в бізнесі миттєво реагують на план і відновлюють усі важливі речі.
BCM діє як структура управління для виявлення ризиків інфраструктури, коли вона стикається із зовнішніми та/або внутрішніми загрозами. Це також гарантує, що структура працює ефективно за допомогою регулярного тестування для підвищення передбачуваності, зниження ризику та узгодження плану майбутніх атак.
BIA
Аналіз впливу на бізнес (BIA) — це процес аналізу рівня виживання бізнесу шляхом визначення важливих систем, операцій і процесів. У ньому розповідається про вплив катастрофи на вашу організацію через перерву у вашій діяльності.
BIA прогнозує наслідки ще до того, як атака справді відбудеться, щоб зібрати ключову інформацію, яка може допомогти створити ефективні стратегії відновлення. Він також визначає витрати, пов’язані з несправностями, такі як вартість заміни обладнання, втрата грошових потоків, прибутку, зарплати тощо.
Під час створення звіту BIA ви повинні враховувати ключові процеси, пов’язані з вашим бізнесом, вплив збоїв на різні сфери, прийнятну тривалість, допустимі зони, фінансові витрати тощо.
Дерево дзвінків
Дерево викликів – це процес складання списку персоналу, до якого потрібно звернутися під час надзвичайної ситуації. Це процедура, яка має деревоподібну структуру.
Наприклад, під час катастрофи одна особа зв’яжеться з невеликою групою членів із терміновим повідомленням, ці співробітники дзвонять кожній групі окремо. Таким чином, увесь персонал буде проінформований під час загрози та розпочне свою призначену роботу, щоб вчасно відновити всі функції та процеси. Створити список просто, але реалізація його в режимі реального часу створює плутанину.
Ви повинні виконувати регулярні виклики, щоб підготувати кожного співробітника екстреної служби до готовності. Регулярне тестування також може допомогти виявити змінені або відсутні числа, які можуть серйозно вплинути на продуктивність.
Дерево викликів містить інформацію, яка використовується під час екстреної ситуації для доставки інструкцій. Це також можна зробити вручну, але люди використовують автоматизацію, щоб прискорити процес і сповістити учасників у сучасному цифровому світі.
Командний центр/Центр управління
Це віртуальний або фізичний об’єкт, спеціально підготовлений для надання команди або контролю над планами відновлення під час кризи. Він спілкується з командою для керування системами та функціями під час катастрофи.
Традиційно інфраструктура залежить від командного центру, який вирішує кризи без належного підходу. У наш час організації ідеально спроектували свій центр управління, що перетворює негайну реакцію на ключову компетенцію.
Як тільки він відчуває катастрофу, командний центр швидко переходить до фази відновлення. Крім того, він служить пунктом звітності у випадку послуг, преси, доставки тощо. Це також об’єднує людей з різних дисциплін під час таких сценаріїв.
Реагування на інцидент

Відповідь на інцидент – це тип відповіді, який дається для боротьби з нападом. Це робиться за допомогою правильних процедур і персоналу для ефективного збереження безпеки мережі та даних у потрібний час.
Якщо організація має план інциденту до несподіваної події, вона може захистити свої дані від загроз у режимі реального часу. Фахівці з реагування на інциденти завжди уважні до проблем і діють природно під час інциденту. Вони вживають певних заходів, щоб уникнути порушень безпеки, гарантуючи, що вони не пропускають жодного кроку під час аварійного відновлення.
На початку ви повинні визначити критичні дані та зберегти їх у хмарі або будь-якому віддаленому місці для забезпечення безпеки. Регулярно оновлюйте плани реагування на інциденти.
Резервне копіювання
Рішення для резервного копіювання допомагають ІТ-інфраструктурі зберігати копії даних і безпечно зберігати їх у потрібний час. Якщо ви зіткнулися з пошкодженням бази даних, випадковим видаленням усіх даних або будь-якою іншою проблемою, ви повинні бути готові до створення резервної копії, щоб миттєво відновити дані та продовжити роботу з послугами.

Він передбачає реплікацію файлів і збереження їх у безпечному місці для легкого доступу до всіх даних після незвичайної події. Це допоможе, якщо ви створите резервну копію своїх даних у кількох місцях, щоб гарантувати, що ви зможете відновити їх навіть у разі збою сайту.
Стійкість
Здатність спільнот, держав, організацій і окремих осіб протистояти катастрофі без шкоди для послуг і систем називається стійкістю до катастрофи.
Організація повинна бути готова витримати велику кількість стресу через небезпеки. Переконайтеся, що у вас є можливості мінімізувати свої втрати за допомогою кращого планування, а не чекати, поки хтось прийде і врятує вас. Це допоможе вам впоратися з катастрофами та ефективно відновити вашу ІТ-інфраструктуру.
Тут головна мета полягає в тому, щоб зберегти та відновити основні функції та структури в потрібний час, коли це необхідно. Щоб стати організацією, стійкою до стихійних лих, ви повинні підготуватися заздалегідь і мати здатність передбачати ризики, пристосовуватися до змін, ділитися та навчатися, інтегрувати різні сектори та керувати рівнями ризику.
SLA

Угода про рівень обслуговування (SLA) — це план на випадок стихійного лиха, у якому ви згадуєте кінцевих користувачів про час, який може знадобитися для відновлення послуг під час надзвичайної ситуації.
Угода про рівень обслуговування гарантує клієнтам, що їхні дані в безпеці, не скомпрометовані та не передані третім особам. Це єдина точка контакту з питаннями кінцевого користувача.
Кожна ІТ-інфраструктура гарантує своїм клієнтам виконання SLA. Отже, переконайтеся, що ви спілкуєтеся з кінцевими користувачами заздалегідь.
SPOF
Єдина точка відмови (SPOF) — це частина обладнання, окрема особа, ресурс або програма, до якої підключено багато інших систем або програм.
Якщо таке обладнання чи ресурс виходить з ладу, разом із ним виходять із ладу всі важливі частини, підключені до системи. Таким чином, це вплине на весь процес і бізнес-операцію.
Тому ви повинні мати стратегію вирішення такої проблеми, щоб підтримувати роботу вашої організації. Найперше, що ви можете зробити, це визначити той окремий елемент обладнання чи системи, який може впливати більше. Далі запустіть аналіз впливу на бізнес і отримайте оцінку ризику, щоб бути в курсі сцен, які відбуватимуться. Копайте та знайдіть їх до події.
Перерахувавши всі SPOF, класифікуйте їх відповідно до процесу відновлення. Розмістіть кожен SPOF у трьох різних категоріях:
- Відновлюйте легко та безпосередньо за меншого часу та бюджету.
- Відновлення буде складним, але можна розробити надійний процес відновлення.
- Нічого не можна зробити для відновлення після того, як він вийде.
Ви можете діяти відповідно на основі категорії.
Відновлення системи
Під час збою апаратного забезпечення ви повинні запустити процес відновлення, щоб відновити певну систему або сервер до початкової форми. А щоб відновити всю систему, вам потрібно підготувати вимоги до відновлення, резервне копіювання, сумісність вбудованого програмного забезпечення та апаратного забезпечення.
Відновлення системи — це процес, який повертає машину до її попередніх налаштувань або того самого стану, у якому вона була під час створення. Це знищить усі вірусні інфекції через встановлене програмне забезпечення або програми у вашій системі.
Цей процес включає планування відновлення ІТ-інфраструктури, яка встановлює та дотримується певних процедур для забезпечення доступності даних у разі техногенних або природних збоїв.
Відновлення системи
Відновлення системи — це інструмент відновлення, який дозволяє в потрібний час відновити певні файли та інформацію до попереднього стану.
За допомогою відновлення системи ви можете відновити ключі реєстру, встановлені програми, драйвери, системні файли тощо до попередньої версії. Це є порятунком під час багатьох катастроф.
План тестування
Це стосується документа, який зберігає інформацію про стратегію тестування, оцінки, ресурси, кінцеві терміни, цілі та графіки. Він працює як план, який запускає тести для забезпечення безпеки апаратного та програмного забезпечення.
Це включає різні тести відповідно до процедур і кроків, запланованих для управління наслідками катастрофи. Виконуйте регулярні тести, щоб підготувати себе та свою організацію до того, щоб не пропустити жодного кроку під час виконання дій. Таким чином ІТ-інфраструктура зможе зрозуміти недоліки та бути готовою до боротьби.
Висновок
Ніхто не знає, коли станеться лихо. Тому належні заходи безпеки є важливими для кожного підприємства.
Термінологія аварійного відновлення допоможе вам зрозуміти, як реагувати на атаки та катастрофи. Це також допоможе вам підготуватися заздалегідь, щоб ви могли захистити свою інфраструктуру під час несподіваної події. Ви зможете створити ефективну стратегію аварійного відновлення в реальному часі, щоб заощадити мільйони доларів і втримати довіру клієнтів.