

Розпізнавання іменованих сутностей (NER) пропонує чудовий спосіб зрозуміти дану текстову інформацію та ідентифікувати конкретні сутності або теги в ній для різних програм.
Від класифікації імен людей до вказівок на дати, організації, місця тощо, NER робить свій шлях для кращого розуміння мови.
Багато організацій мають справу з великим обсягом даних у формі вмісту, особистої інформації, відгуків клієнтів, деталей продукту та багато іншого.
Коли інформація потрібна миттєво, для отримання результату потрібно буде виконати пошукові операції, що може забрати багато часу, енергії та ресурсів, особливо при роботі з великими обсягами даних.
Щоб надати організаціям ефективне рішення для пошукових операцій і пошуку потрібних даних, NER є чудовим вибором.
У цій статті я детально обговорю NER, його математичну концепцію, різні способи використання та інші важливі моменти.
Давайте розпочнемо!
Що таке розпізнавання іменованих сутностей?
Розпізнавання іменованих сутностей (NER) — це метод обробки природної мови (NLP), який може ідентифікувати та класифікувати сутності в текстових неструктурованих даних.
Ці об’єкти містять широкий спектр інформації, як-от організації, місцезнаходження, імена осіб, числові значення, дати тощо. Він дає змогу машинам видобувати зазначені вище сутності, що робить його корисним інструментом для таких програм, як переклад, відповіді на запитання тощо в кількох галузях.
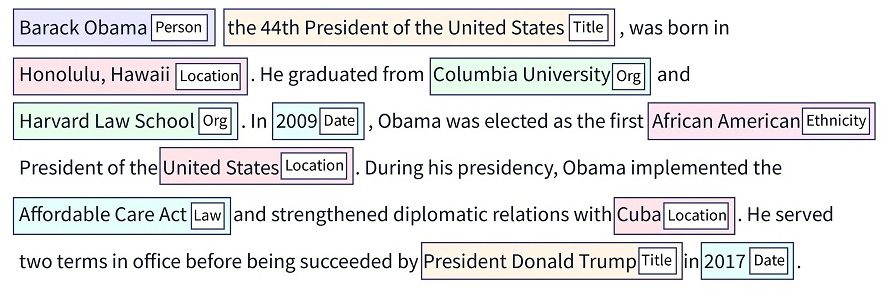 Джерело: Скалер
Джерело: Скалер
Таким чином, NER намагається знайти та класифікувати різні об’єкти в неструктурованому тексті в заздалегідь визначені групи, такі як організації, медичні коди, кількості, імена осіб, відсотки, грошові значення, вирази часу тощо.
Давайте зрозуміємо це на прикладі:
[William] купив нерухомість у [Z1 Corp.] в [2023]. Тут блоки — це сутності, ідентифіковані NER. Вони класифікуються як:
- Вільям – Ім’я людини
- Z1 Corp. – Організація
- 2003 – Час
NER використовується в кількох сферах штучного інтелекту, включаючи глибоке навчання, машинне навчання (ML) і нейронні мережі. Це критично важливий компонент систем НЛП, таких як інструменти аналізу настроїв, пошукові системи та чат-боти. Крім того, його можна використовувати у фінансах, підтримці клієнтів, вищій освіті, охороні здоров’я, людських ресурсах та аналізі соціальних мереж.
Простіше кажучи, NER ідентифікує, класифікує та витягує важливу інформацію з неструктурованого тексту без будь-якого людського аналізу. Він може швидко витягувати ключову інформацію з доступного набору великих даних.
Крім того, NER надає вашій організації важливу інформацію про продукти, ринкові тенденції, клієнтів і конкуренцію. Наприклад, заклади охорони здоров’я використовують NER для отримання основних медичних даних із записів пацієнтів. Багато компаній використовують його, щоб визначити, чи згадуються вони в будь-яких публікаціях.
Ключові поняття: NER

Важливо знати основні поняття, пов’язані з NER. Давайте обговоримо деякі ключові терміни, пов’язані з NER, з якими слід ознайомитися.
- Іменована сутність: будь-яке слово, яке стосується місця, організації, особи чи іншої сутності.
- Корпус: колекція різних текстів, які використовуються для аналізу мов і навчання моделей NER.
- POS-теги: процес, у якому текст позначається відповідно до відповідної мови, наприклад прикметників, дієслів та іменників.
- Розбиття на частини: це процес, який використовується для групування слів у різні значущі фрази на основі синтаксичної структури та частини мови.
- Дані навчання та тестування: це процес, який використовується для навчання моделі з позначеними даними та оцінки продуктивності першого набору на іншому наборі даних.
Використання NER в НЛП

NER має багато застосувань у НЛП, таких як аналіз настроїв, системи рекомендацій, відповіді на запитання, вилучення інформації тощо.
- Аналіз настроїв: NER використовується для виявлення настроїв, виражених у реченні чи абзаці, щодо конкретної названої сутності, наприклад продукту чи послуги. Ці дані використовуються для покращення досвіду клієнтів і визначення областей покращення.
- Системи рекомендацій: NER використовується для визначення вподобань та інтересів користувачів на основі названих об’єктів, згаданих у онлайн-взаємодіях або пошукових запитах. Ці дані використовуються для покращення роботи користувача шляхом надання персоналізованих рекомендацій.
- Відповідь на запитання: NER використовується для виявлення певних сутностей у тексті, який далі використовується для відповіді на запит або конкретне запитання. Це зазвичай використовується для віртуальних помічників і чат-ботів.
- Вилучення інформації: NER використовується для вилучення важливої інформації з більшого набору неструктурованого тексту. Це включає дописи в соціальних мережах, онлайн-огляди, новинні статті тощо. Ці дані використовуються для отримання цінної інформації та прийняття рішень на основі даних.
Математичні поняття: NER
Процес NER включає різні математичні концепції, такі як машинне навчання, глибоке навчання, теорія ймовірностей тощо. Ось деякі математичні прийоми:
- Приховані марковські моделі: приховані марковські моделі або HMM — це статистичний підхід для послідовності завдань класифікації, наприклад NER. Він передбачає представлення певної послідовності слів у тексті як різних станів, де кожен стан представляє певну названу сутність. Аналізуючи ймовірності, ви можете ідентифікувати названі сутності з тексту.
- Глибоке навчання: у завданнях NER використовуються методи глибокого навчання, такі як нейронні мережі. Це дозволяє ефективно та точно ідентифікувати та класифікувати названі сутності.
- Умовні випадкові поля: вони підпадають під графічну модель, яка використовується в завданнях позначення послідовності. Вони пропонують моделювання умовної ймовірності кожного тегу, що містить послідовність слів. Це дозволяє ідентифікувати названі сутності в тексті.
Як працює NER?
 Джерело: Публікації ACS
Джерело: Публікації ACS
Розпізнавання іменованих об’єктів (NER) працює як вилучення інформації. Його функціонування поділяється на кілька ключових етапів:
#1. Попередньо обробіть текст
На першому етапі NER передбачає підготовку текстової інформації для аналізу. Зазвичай це включає такі завдання, як токенізація. Тут текст спочатку розділився на токени, перш ніж NER почав ідентифікувати сутності.
Наприклад, «Білл Гейтс заснував Microsoft» можна розділити на різні токени, наприклад «Білл», «Гейтс», «заснований» і «Microsoft».
#2. Визначте сутності
Потенційні іменовані сутності можна виявити за допомогою статистичних методів або лінгвістичних правил. Цей крок передбачає розпізнавання шаблонів, наприклад певних форматів (дати) або використання великих літер в іменах («Білл Гейтс»). Після завершення функції попередньої обробки алгоритми NER сканують текст, щоб визначити слова в послідовностях, які відповідають сутностям.
#3. Класифікуйте сутності
Після того, як NER ідентифікує сутності, вона класифікує ці розпізнані сутності за типами, класами або групами. Загальними категоріями є організація, дата, місцезнаходження, особа тощо. Це досягається моделями машинного навчання, які навчаються на позначених даних.
Наприклад, «Білл Гейтс» буде визнано «особою», а «Microsoft» — «організацією».
#4. Контекстний аналіз
NER ніколи не зупиняється на розпізнаванні та класифікації сутностей. Він часто враховує контекст для підвищення точності. На цьому етапі враховується контекст, у якому з’являються сутності, надаючи точну категоризацію.
Наприклад, «Білл Гейтс заснував Microsoft». Тут контекст дозволяє системам ідентифікувати «Рахунок» як ім’я особи, а не платіжний рахунок.
#5. Подальша обробка
Після первинної ідентифікації та категоризації необхідна додаткова обробка для уточнення кінцевих результатів. Це передбачає вирішення неоднозначностей, використання баз знань, об’єднання сутностей із кількома маркерами тощо для покращення даних сутностей.
Дивовижна частина NER полягає в тому, що він має здатність інтерпретувати та розуміти неструктурований текст, який містить необхідні для вашого бізнесу фрагменти даних. Він отримує значну частину даних із статей новин, веб-сторінок, наукових статей, публікацій у соціальних мережах тощо.
Розпізнаючи та класифікуючи іменовані сутності, NER додає текстовому ландшафту додатковий рівень значення та структури.
Методи НЕР

Найбільш часто використовувані методи:
#1. Метод на основі керованого машинного навчання
Цей метод використовує моделі машинного навчання, які навчаються на текстах, попередньо позначених людьми іменованими категоріями об’єктів.
Цей підхід використовує алгоритми, включаючи максимальну ентропію та умовні випадкові поля, щоб отримати складні статистичні мовні моделі. Він ефективний для вирішення мовних значень разом з іншими складнощами, але для виконання операції потрібен великий обсяг навчальних даних.
#2. Системи на основі правил
Цей метод використовує різні правила для збору інформації. Він містить заголовки або великі літери, як-от «Er». У цьому методі необхідне значне людське втручання, щоб вводити дані, контролювати та змінювати правила. Цей метод може пропустити текстові варіації, які не включені в навчальні анотації. Ось чому системи, засновані на правилах, не в змозі мати справу з моделями складності та машинного навчання.
#3. Системи на основі словників
У цьому методі словник, що містить велику кількість синонімів і колекцію словників, використовується для ідентифікації та перехресної перевірки іменованих ідентичностей. Цей метод стикається з проблемами при класифікації іменованих сутностей, які мають різні варіанти написання.
Крім того, існує багато інших нових методів NER. Давайте також обговоримо їх:
#4. Системи машинного навчання без контролю
Ці системи ML використовують моделі машинного навчання, які попередньо не навчаються на текстових даних. Моделі неконтрольованого навчання більш здатні виконувати складні завдання, ніж моделі під наглядом.
#5. Системи завантаження
Системи завантаження також відомі як самоконтрольовані системи, які класифікують названі сутності залежно від граматичних характеристик, включаючи теги частин мови, використання великих літер та інші попередньо навчені категорії.
Потім людина налаштовує систему початкового завантаження, позначаючи прогнози системи як неправильні або правильні та додаючи правильні до нового навчального набору.
#6. Нейромережеві системи
Він будує модель розпізнавання іменованих сутностей, використовуючи моделі навчання двонаправленої архітектури (представлення двонаправленого кодера від Transformers), нейронних мереж і методів кодування. Цей метод мінімізує взаємодію людини.
#7. Статистичні системи
Цей метод використовує ймовірнісні моделі, які навчаються на текстових зв’язках і шаблонах. Це допомагає легко передбачити іменовані сутності на основі нових текстових даних.
#8. Системи маркування семантичних ролей
Ця система попередньо обробляє модель розпізнавання іменованих сутностей, використовуючи методи семантичного навчання, які навчають зв’язку між категоріями та контекстом.
#9. Гібридні системи
Цей цікавий метод використовує аспекти кількох підходів у поєднанні.
Переваги NER
Моделі NER мають численні переваги.
- NER автоматизує процес вилучення даних для великого обсягу даних.
- Він використовується в кожній галузі для вилучення ключової інформації з неструктурованого тексту.
- Це може заощадити вам і вашим співробітникам час на виконання завдань вилучення даних.
- Це може підвищити точність процесів і завдань НЛП.
- Він забезпечує безпеку даних, розміщуючи власні моделі NER, усуваючи необхідність обмінюватися конфіденційною інформацією зі сторонніми постачальниками.
- Він вміщує нові типи об’єктів і термінологію в міру розвитку домену.
Виклики НЕР
- Двозначність: багато слів, використаних у тексті, можуть бути оманливими. Наприклад, слово «Амазонка» стосується компанії, річки та лісу. Його можна диференціювати за певним контекстом. Таким чином, це робить розпізнавання сутності трохи складнішим.
- Залежність від контексту: слова, отримані з навколишнього контексту, мають різні значення; наприклад, «Apple» у тексті, присвяченому техніці, відноситься до корпорації, а в оточенні – до фруктів. Розпізнати точну сутність неважко.
- Розрідженість даних: для методів NER на основі ML доступність позначених даних є важливою. Однак отримання таких даних, особливо для спеціалізованих доменів або менш поширених мов, може бути складним завданням.
- Мовні варіації: людські мови мають різні форми залежно від їх діалектів, регіональних відмінностей і сленгу. Отже, важко витягнути текст іншою мовою.
- Узагальнення моделі: моделі NER можуть бути відмінними в класифікації об’єктів в одній області, але можуть заплутати узагальнення в іншій області. Отже, моделі NER можуть по-різному поводитися в різних доменах.
Ці проблеми можна вирішити, якщо поєднати передові алгоритми, лінгвістичний досвід і якісні дані. Оскільки NER розвивається, команди дослідників і розробників повинні вдосконалювати різні методи для вирішення цих проблем.
Випадки використання NER
#1. Категоризація вмісту

Видавництва та новини створюють великий обсяг онлайн-контенту. Отже, ефективне керування ними має вирішальне значення, щоб отримати максимальну віддачу від статті чи новини.
Розпізнавання іменованих об’єктів автоматично сканує весь вміст і витягує дані, як-от імена організацій, місць і людей, які використовуються у вмісті. Знання необхідних тегів для кожної статті допоможе вам класифікувати статті за визначеною ієрархією, покращуючи доставку вмісту.
#2. Алгоритми пошуку
Припустімо, що у вас є внутрішній алгоритм пошуку для вашого онлайн-видавця, який містить мільйони статей. Для кожного пошукового запиту ваш внутрішній алгоритм пошуку збирає всі слова з цих статей. Це трудомісткий процес.
Тепер, якщо ви використовуєте NER для свого онлайн-видавця, він легко отримає основні об’єкти з усіх статей і збереже їх окремо. Це прискорить процес пошуку.
#3. Рекомендації щодо змісту
Автоматизація процесу рекомендацій є основним варіантом використання NER. Системи рекомендацій допомагають у відкритті нових ідей і контенту.
Netflix є найкращим прикладом цього. Це доказ того, що побудова ефективної системи рекомендацій допоможе вам стати більш захоплюючими та привабливими.
Для видавців новин NER ефективно рекомендує подібні статті. Це можна зробити, зібравши теги з певної статті та порекомендувавши інший вміст, який має подібні сутності.
#4. Підтримка клієнтів

Для кожної організації підтримка клієнтів є важливою справою. Ось чому існує кілька способів зробити функцію обробки відгуків клієнтів гладкою. NER є одним із них. Розберемося в цьому на прикладі.
Припустімо, що клієнт надає відгук: «Персонал магазину розпродажів Adidas у Сан-Дієго відчуває брак тонких деталей спортивного взуття». Тут NER витягує теги «Сан-Дієго» (місце розташування) і «спортивне взуття» (товар).
Таким чином, NER використовується для класифікації кожної скарги та надсилання її до відповідного відділу організації для розгляду проблеми. Ви можете розробити базу даних, що складається з відгуків, розділених на різні відділи, і проаналізувати кожен відгук.
#5. Наукові праці
Веб-сайт онлайн-видання чи журналу містить багато наукових статей і наукових робіт. Ви можете знайти сотні документів, що нагадують подібні теми з невеликими змінами. Таким чином, організувати всі ці дані в структурований спосіб може бути складним завданням.
Щоб пропустити тривалий процес, ви можете розділити ці документи на основі відповідних тегів.
Наприклад, є тисячі робіт про машинне навчання. Щоб знайти той, у якому згадується використання згорткових нейронних мереж (CNN), вам потрібно помістити в них сутності. Це допоможе вам швидко знайти статтю відповідно до ваших вимог.
Висновок
Техніка NLP, розпізнавання іменованих сутностей (NER), допомагає в ідентифікації іменованих сутностей у неструктурованому тексті та категоризації цих сутностей у заздалегідь визначені групи, як-от розташування, імена людей, продукти тощо.
Основна мета NER — зібрати структуровану інформацію з неструктурованого тексту та представити її у зручному для читання форматі. Він включає різні моделі та процеси та приносить багато переваг професіоналам і підприємствам. Він також використовується для різних застосувань, крім НЛП.
Сподіваюся, ви зрозуміли наведене вище пояснення щодо цієї техніки, щоб мати змогу застосувати її у своєму бізнесі та вчасно отримувати відповідну цінну інформацію.
Ви також можете ознайомитися з кращими курсами НЛП, щоб навчитися обробці природної мови