Автоматизований моніторинг інфраструктури за допомогою машинного навчання в хмарі
Уявіть собі масштабну інфраструктуру, що складається з різноманітних пристроїв, які потребують регулярного технічного обслуговування або постійного контролю для забезпечення їх безпечної роботи.
Традиційний підхід передбачає відправлення технічних спеціалістів до кожної точки інфраструктури для перевірки стану обладнання. Хоча це і дієвий спосіб, він вимагає значних витрат часу та ресурсів. У випадку великої інфраструктури, можливо, навіть не вдасться охопити всі об’єкти протягом одного року.
Альтернативним рішенням є автоматизація процесу перевірки за допомогою хмарних технологій. Для цього необхідно виконати кілька ключових кроків:
👉 **Швидке отримання зображень пристроїв.** Цю операцію можуть виконувати люди, оскільки фотографування значно швидше за повну технічну перевірку. Крім того, можна використовувати фотографії, зроблені з автомобілів або дронів, що дозволить значно пришвидшити та автоматизувати процес збору зображень.
👉 **Передача зображень до хмарного сховища.** Усі отримані фотографії необхідно централізовано зберігати в хмарі.
👉 **Автоматизований аналіз зображень у хмарі.** У хмарі, за допомогою спеціальних алгоритмів машинного навчання, проводиться аналіз зображень для виявлення пошкоджень або аномалій.
👉 **Візуалізація результатів.** Отримані результати аналізу повинні бути доступними для відповідних користувачів, щоб вони могли запланувати необхідний ремонт.
Розглянемо докладніше, як можна реалізувати виявлення аномалій на зображеннях за допомогою хмарної інфраструктури AWS. Amazon надає низку готових моделей машинного навчання, які можна використовувати для цих цілей.
Створення моделі для візуального виявлення аномалій
Процес створення моделі для візуального виявлення аномалій включає кілька етапів:
Етап 1: Чітке визначення проблеми, яку необхідно вирішити, та видів аномалій, які потрібно виявити. Це допоможе у виборі відповідного набору даних для навчання моделі.
Етап 2: Збір великого набору зображень, які відображають як нормальні, так і аномальні стани. Необхідно маркувати зображення, щоб вказати, які з них є нормальними, а які містять аномалії.
Етап 3: Вибір архітектури моделі, яка найкраще підходить для поставленого завдання. Можна використовувати попередньо навчені моделі, адаптуючи їх до конкретних потреб, або ж створити спеціальну модель з нуля.
Етап 4: Навчання моделі за допомогою підготовленого набору даних та обраного алгоритму. Для цього можна використовувати методи трансферного навчання на основі попередньо навчених моделей або навчати модель з нуля, використовуючи, наприклад, згорткові нейронні мережі (CNN).
Навчання моделі машинного навчання
Джерело: aws.amazon.com
Навчання моделей машинного навчання AWS для виявлення візуальних аномалій зазвичай складається з кількох важливих кроків.
#1. Збір даних
Першим кроком є збір та маркування великого набору зображень, що відображають як нормальні, так і аномальні стани. Чим більший набір даних, тим кращою буде якість навчання моделі. Проте, більший набір даних також вимагає більше часу на навчання.
Для початку навчання рекомендується мати принаймні 1000 зображень у наборі для тестування.
#2. Підготовка даних
Зображення необхідно попередньо обробити, щоб моделі машинного навчання могли їх ефективно аналізувати. Попередня обробка може включати:
- Організацію вхідних зображень у окремі папки, виправлення метаданих.
- Зміну розміру зображень відповідно до вимог моделі.
- Розподіл зображень на менші фрагменти для більш ефективної паралельної обробки.
#3. Вибір моделі
Необхідно обрати модель, яка найкраще підходить для виконання поставленого завдання. Можна використовувати попередньо навчену модель або ж створити спеціальну модель для виявлення візуальних аномалій.
#4. Оцінка результатів
Після обробки даних моделлю необхідно оцінити її продуктивність та перевірити, чи відповідають результати поставленим цілям. Наприклад, точність виявлення може становити понад 99% для вхідних даних.
#5. Розгортання моделі
Якщо результати та продуктивність моделі є задовільними, необхідно розгорнути її в середовищі AWS, щоб інші процеси та сервіси могли її використовувати.
#6. Моніторинг та вдосконалення
Необхідно постійно оцінювати роботу моделі на різних тестових наборах даних, щоб переконатися, що параметри визначення аномалій залишаються точними. За необхідності модель потрібно перенавчити, додавши до набору даних нові зображення, де вона дала неправильні результати.
Моделі машинного навчання AWS
Розглянемо деякі конкретні моделі, доступні в хмарі Amazon.
Розпізнавання AWS
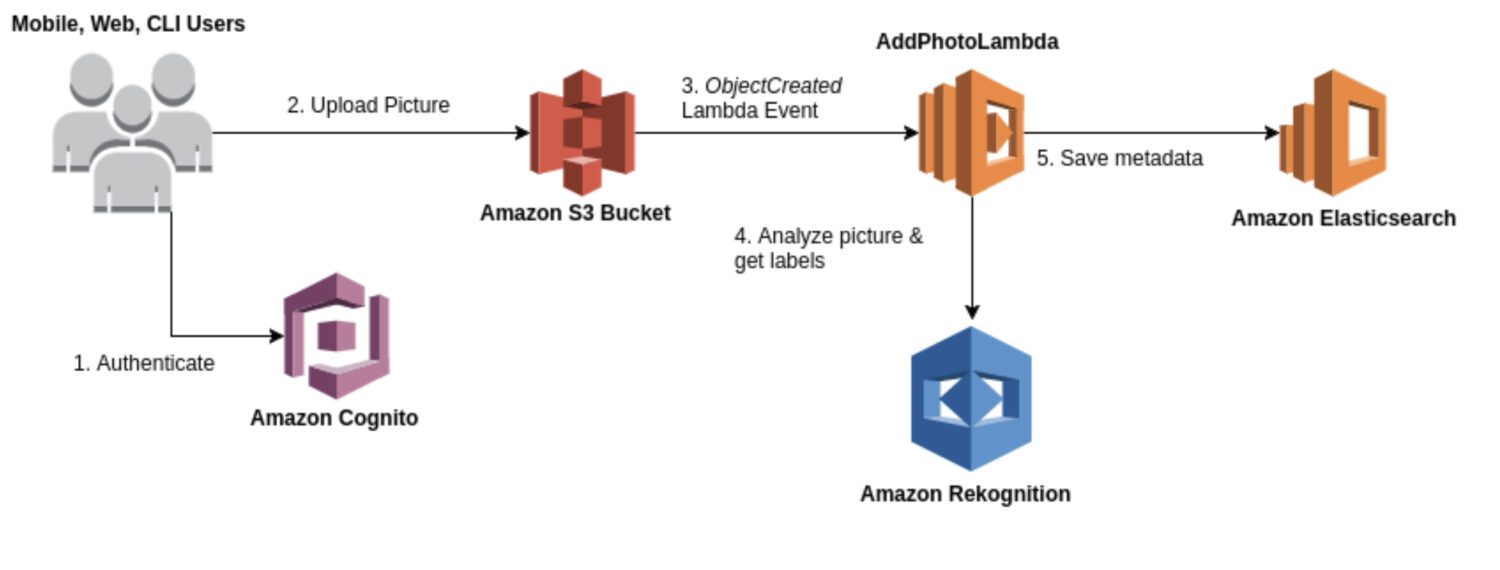
Джерело: aws.amazon.com
Rekognition – це універсальний сервіс аналізу зображень та відео, що може використовуватися для різних цілей, таких як розпізнавання облич, виявлення об’єктів та розпізнавання тексту. Зазвичай Rekognition використовується для початкового отримання результатів виявлення, які потім використовуються для формування бази даних аномалій.
Сервіс надає ряд готових моделей, які можна використовувати без додаткового навчання. Rekognition забезпечує аналіз зображень та відео в реальному часі з високою точністю та низькою затримкою.
Деякі типові випадки використання Rekognition для виявлення аномалій:
- Загальне виявлення аномалій на зображеннях або відео.
- Виявлення аномалій в реальному часі.
- Інтеграція моделі з сервісами AWS, такими як Amazon S3, Amazon Kinesis або AWS Lambda.
Приклади аномалій, які можна виявити за допомогою Rekognition:
- Аномалії обличчя, наприклад, виявлення незвичних виразів або емоцій.
- Відсутні або неправильно розміщені об’єкти на зображенні.
- Неправильно написані слова або незвичні шаблони тексту.
- Незвичайні умови освітлення або неочікувані об’єкти на зображенні.
- Неприйнятний або образливий контент на зображеннях або відео.
- Раптові зміни в русі або несподівані моделі руху.
AWS Lookout for Vision
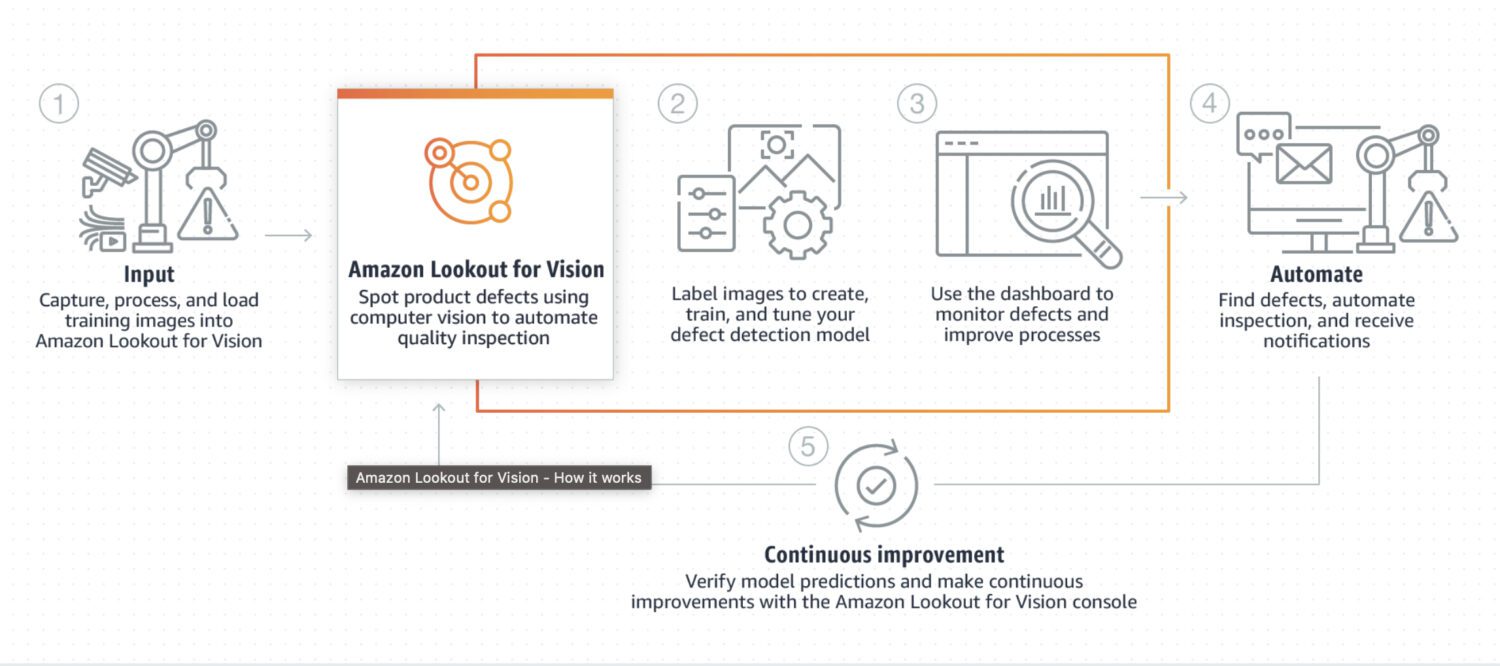
Джерело: aws.amazon.com
Lookout for Vision – це модель, спеціально розроблена для виявлення аномалій у промислових процесах, таких як виробництво. Зазвичай для її використання потрібна попередня обробка коду та постобробка зображення за допомогою Python. Lookout for Vision спеціалізується на конкретних проблемах на зображенні.
Для створення спеціальної моделі необхідно провести навчання на наборі даних, що містять нормальні та аномальні зображення. Ця модель не призначена для обробки даних у реальному часі, а більше орієнтована на пакетну обробку з акцентом на точність.
Типові випадки використання Lookout for Vision:
- Виявлення дефектів на виробленій продукції або несправностей обладнання.
- Обробка великих наборів зображень.
- Виявлення аномалій в промислових процесах.
- Інтеграція з іншими сервісами AWS, такими як Amazon S3 або AWS IoT.
Приклади аномалій, які можна виявити за допомогою Lookout for Vision:
- Дефекти на виробах, такі як подряпини, вм’ятини або інші недоліки.
- Несправності обладнання на виробничій лінії.
- Проблеми контролю якості, виявлення продуктів, які не відповідають специфікаціям.
- Небезпечні ситуації на виробничій лінії.
- Аномалії у виробничому процесі, такі як несподівані зміни у потоці матеріалів.
AWS Sagemaker
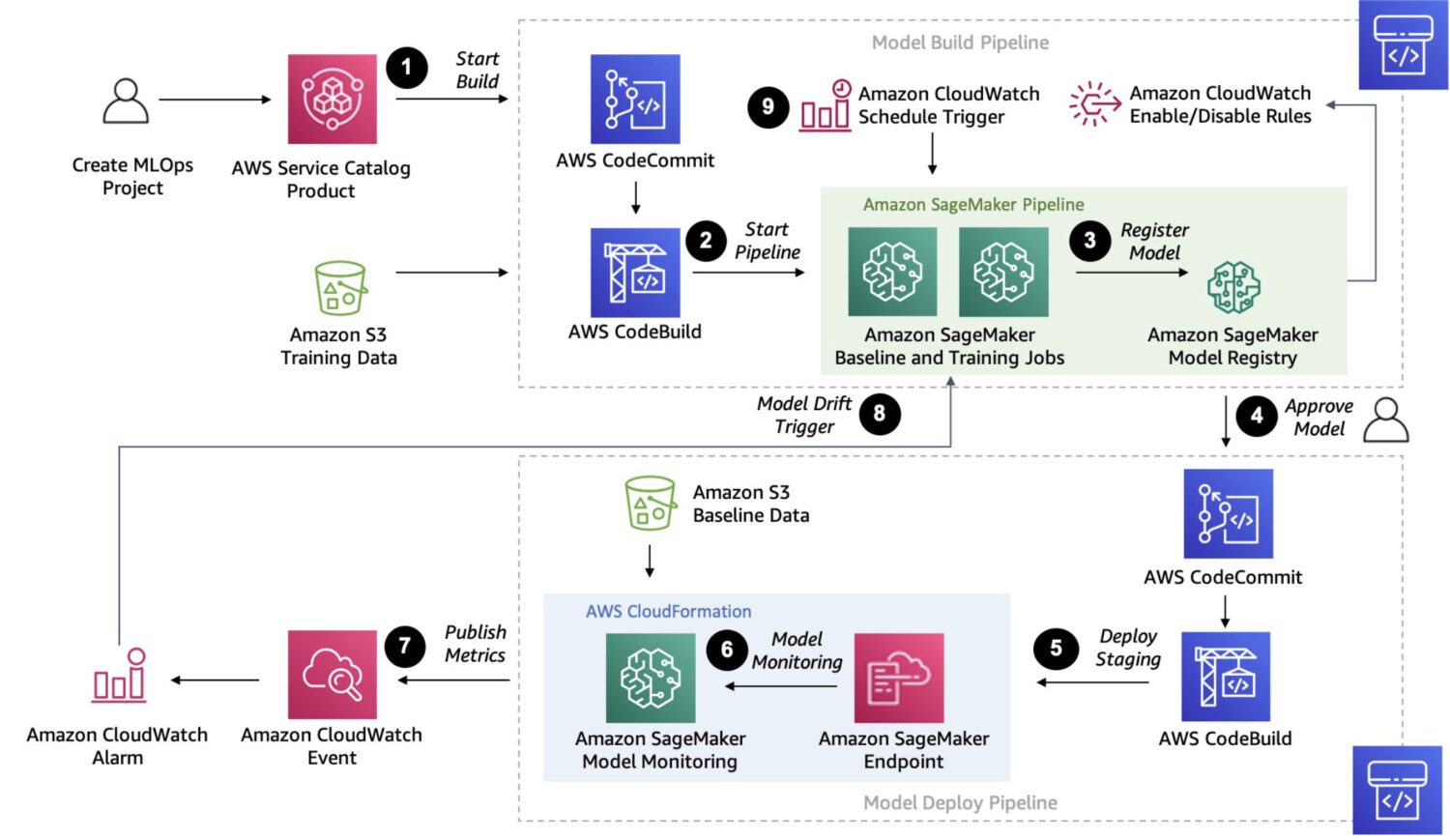
Джерело: aws.amazon.com
Sagemaker – це керована платформа для створення, навчання та розгортання спеціальних моделей машинного навчання.
Sagemaker – це надійне рішення, яке дозволяє об’єднувати в ланцюжки кілька етапів обробки даних. На відміну від AWS Lambda, Sagemaker не має 15-хвилинного обмеження для обробки одного завдання, оскільки використовує спеціальні екземпляри EC2.
Sagemaker також підтримує автоматичне налаштування моделей, що робить його відмінним варіантом для розробки та розгортання. Платформа дозволяє легко інтегрувати моделі у виробниче середовище.
Типові випадки використання SageMaker:
- Створення індивідуальних моделей, які не охоплюються попередньо створеними API.
- Обробка великих наборів зображень або інших даних.
- Виявлення аномалій у реальному часі.
- Інтеграція моделі з іншими сервісами AWS, такими як Amazon S3, Amazon Kinesis або AWS Lambda.
Приклади аномалій, які можна виявити за допомогою Sagemaker:
- Виявлення шахрайства у фінансових операціях.
- Виявлення кіберзагроз у мережевому трафіку.
- Медична діагностика на основі медичних зображень.
- Виявлення аномалій в роботі обладнання.
- Контроль якості у виробничих процесах.
- Виявлення незвичайних моделей споживання енергії.
Інтеграція моделей в безсерверну архітектуру
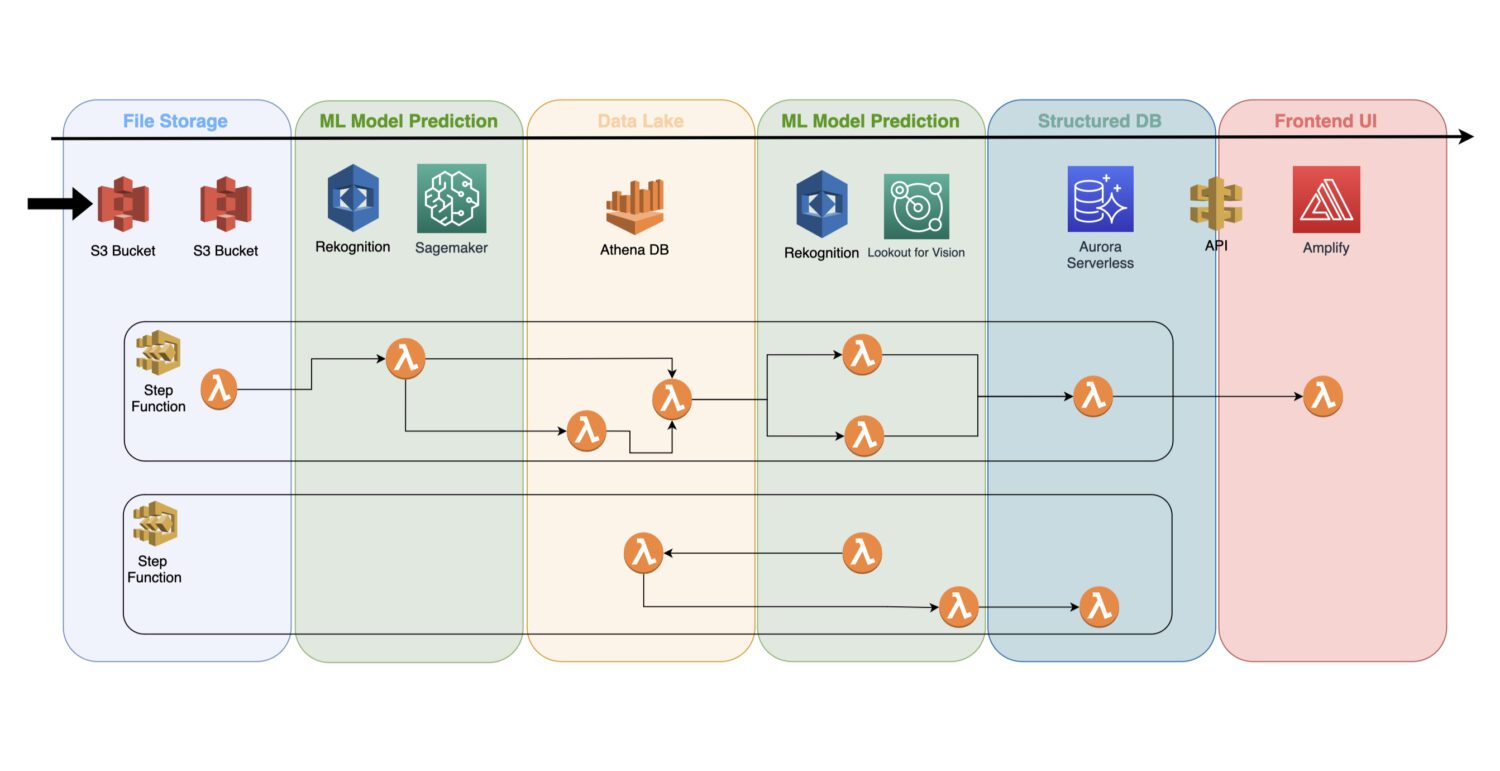
Навчена модель машинного навчання є хмарним сервісом, який не потребує кластерних серверів. Це дозволяє легко інтегрувати її в існуючу безсерверну архітектуру.
Автоматизація процесу відбувається за допомогою AWS Lambda, об’єднаних у послідовність кроків за допомогою AWS Step Functions.
Зазвичай, одразу після збору зображень та їх попередньої обробки на S3 необхідно провести первинне виявлення. Це дозволить виявити аномалії на вхідних зображеннях та зберегти результати, наприклад, у базі даних Athena.
У деяких випадках цього первинного виявлення може бути недостатньо. Можливо, знадобиться більш детальний аналіз. Наприклад, початкова модель (Rekognition) може виявити проблему на пристрої, але не зможе визначити її тип. У цьому випадку можна використовувати іншу модель (Lookout for Vision) для аналізу підмножини зображень, на яких початкова модель виявила проблему.
Такий підхід також допомагає заощадити кошти, оскільки не потрібно запускати другу модель для обробки всіх зображень, а лише для тих, де це необхідно.
Функції AWS Lambda забезпечують обробку даних за допомогою коду на Python або Javascript. Кількість лямбда-функцій та послідовність їх виконання залежить від складності процесу. Ліміт часу виконання лямбда-функцій (15 хвилин) впливає на кількість кроків, які можуть входити до процесу.
Заключні слова
Робота з хмарними моделями машинного навчання — це захоплююче завдання, яке вимагає команди з різноманітними навичками. Команда має розуміти, як навчати моделі, як готові, так і створені з нуля. Це вимагає знань математики та алгебри для досягнення балансу між надійністю та ефективністю результатів.
Крім того, необхідні навички кодування на Python або Javascript, знання роботи з базами даних та SQL. Після завершення розробки необхідні навички DevOps, щоб інтегрувати рішення в автоматизований конвеєр.
Визначення аномалій та навчання моделі – це лише частина завдання. Об’єднання всіх елементів в єдину систему, здатну ефективно обробляти результати, зберігати дані та надавати їх кінцевим користувачам, є складним, але важливим завданням.
Дізнайтеся більше про розпізнавання облич для компаній.