
Регресія та класифікація є двома найбільш фундаментальними та значущими областями машинного навчання.
Може бути важко розрізнити алгоритми регресії та класифікації, коли ви тільки починаєте машинне навчання. Розуміння того, як ці алгоритми працюють і коли їх використовувати, може мати вирішальне значення для прийняття точних прогнозів і ефективних рішень.
Спочатку подивимося на машинне навчання.
Що таке машинне навчання?
Машинне навчання — це метод навчання комп’ютерів навчатися та приймати рішення без явного програмування. Він передбачає навчання комп’ютерної моделі на наборі даних, що дозволяє моделі робити прогнози або приймати рішення на основі шаблонів і зв’язків у даних.
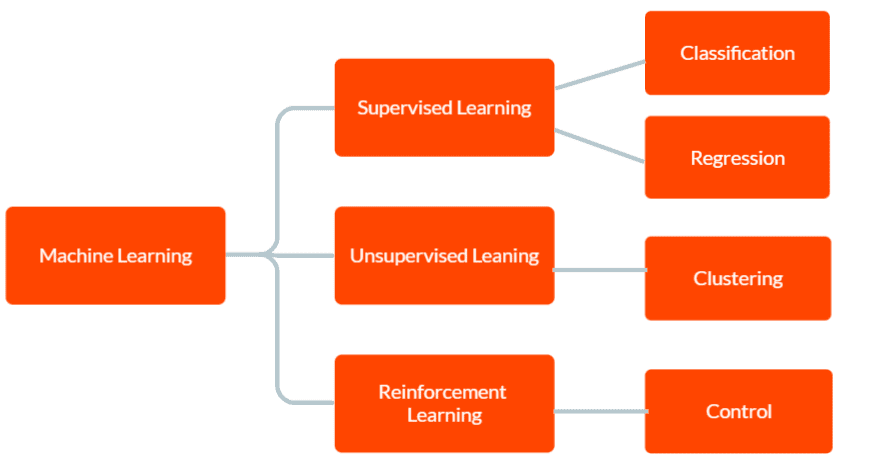
Існує три основних типи машинного навчання: контрольоване навчання, неконтрольоване навчання та навчання з підкріпленням.
У контрольованому навчанні модель надається з позначеними навчальними даними, включаючи вхідні дані та відповідний правильний вихід. Мета полягає в тому, щоб модель робила прогнози щодо вихідних даних для нових, невидимих даних на основі шаблонів, які вона дізналася з навчальних даних.
У неконтрольованому навчанні моделі не надаються жодні позначені навчальні дані. Замість цього залишається самостійно виявляти закономірності та зв’язки в даних. Це можна використовувати для ідентифікації груп або кластерів у даних або для пошуку аномалій чи незвичайних моделей.
А в Reinforcement Learning агент вчиться взаємодіяти зі своїм середовищем, щоб максимізувати винагороду. Це передбачає навчання моделі приймати рішення на основі відгуків, які вона отримує від середовища.
Машинне навчання використовується в різних програмах, включаючи розпізнавання зображень і мови, обробку природної мови, виявлення шахрайства та безпілотні автомобілі. Він має потенціал для автоматизації багатьох завдань і покращення процесу прийняття рішень у різних галузях.
Ця стаття в основному зосереджена на концепціях класифікації та регресії, які підпадають під контрольоване машинне навчання. Давайте розпочнемо!
Класифікація в машинному навчанні

Класифікація — це техніка машинного навчання, яка передбачає навчання моделі призначати мітку класу заданому вхідному сигналу. Це контрольоване навчальне завдання, що означає, що модель навчається на позначеному наборі даних, який включає приклади вхідних даних і відповідних міток класу.
Модель спрямована на вивчення зв’язку між вхідними даними та мітками класу, щоб передбачити мітку класу для нових, невидимих вхідних даних.
Існує багато різних алгоритмів, які можна використовувати для класифікації, включаючи логістичну регресію, дерева рішень і опорні векторні машини. Вибір алгоритму буде залежати від характеристик даних і бажаної продуктивності моделі.
Деякі поширені програми класифікації включають виявлення спаму, аналіз настроїв і виявлення шахрайства. У кожному з цих випадків вхідні дані можуть містити текст, числові значення або комбінацію обох. Мітки класів можуть бути двійковими (наприклад, спам або не спам) або багатокласовими (наприклад, позитивні, нейтральні, негативні настрої).
Наприклад, розглянемо набір даних відгуків клієнтів про продукт. Вхідними даними може бути текст відгуку, а міткою класу може бути оцінка (наприклад, позитивна, нейтральна, негативна). Модель буде навчена на наборі даних позначених відгуків, а потім зможе передбачити рейтинг нового відгуку, якого вона раніше не бачила.
Типи алгоритмів класифікації ML
У машинному навчанні існує кілька типів алгоритмів класифікації:
Логістична регресія
Це лінійна модель, яка використовується для бінарної класифікації. Він використовується для прогнозування ймовірності настання певної події. Мета логістичної регресії — знайти найкращі коефіцієнти (ваги), які мінімізують похибку між прогнозованою ймовірністю та спостережуваним результатом.
Це робиться за допомогою алгоритму оптимізації, наприклад градієнтного спуску, для коригування коефіцієнтів, доки модель якомога краще відповідатиме навчальним даним.
Дерева рішень
Це деревоподібні моделі, які приймають рішення на основі значень ознак. Їх можна використовувати як для бінарної, так і для багатокласової класифікації. Дерева рішень мають кілька переваг, включаючи їх простоту та взаємодію.
Вони також швидко навчаються та роблять прогнози, а також можуть обробляти як числові, так і категоричні дані. Однак вони можуть бути схильні до переобладнання, особливо якщо дерево глибоке і має багато гілок.
Випадкова класифікація лісу
Класифікація випадкового лісу – це метод ансамблю, який поєднує прогнози кількох дерев рішень для отримання більш точного та стабільного прогнозу. Він менш схильний до переобладнання, ніж одне дерево рішень, оскільки прогнози окремих дерев усереднюються, що зменшує дисперсію в моделі.
AdaBoost
Це алгоритм підвищення, який адаптивно змінює вагу неправильно класифікованих прикладів у навчальному наборі. Його часто використовують для бінарної класифікації.
Наївний Байєс
Наївний Байєс базується на теоремі Байєса, яка є способом оновлення ймовірності події на основі нових доказів. Це ймовірнісний класифікатор, який часто використовується для класифікації тексту та фільтрації спаму.
K-найближчий сусід
K-найближчі сусіди (KNN) використовуються для завдань класифікації та регресії. Це непараметричний метод, який класифікує точку даних на основі класу її найближчих сусідів. KNN має кілька переваг, включаючи його простоту та те, що його легко реалізувати. Він також може обробляти як числові, так і категоричні дані, і не робить жодних припущень щодо базового розподілу даних.
Посилення градієнта
Це ансамблі слабких учнів, які навчаються послідовно, при цьому кожна модель намагається виправити помилки попередньої моделі. Їх можна використовувати як для класифікації, так і для регресії.
Регресія в машинному навчанні
У машинному навчанні регресія — це тип навчання під наглядом, метою якого є прогнозування змінної, залежної від змінного струму, на основі однієї або кількох вхідних характеристик (також званих предикторами або незалежними змінними).
Алгоритми регресії використовуються для моделювання зв’язку між вхідними та вихідними даними та створення прогнозів на основі цього співвідношення. Регресію можна використовувати як для безперервних, так і для категоріальних залежних змінних.
Загалом мета регресії полягає в тому, щоб побудувати модель, яка може точно передбачити результат на основі вхідних характеристик і зрозуміти основний зв’язок між вхідними характеристиками та результатом.
Регресійний аналіз використовується в різних галузях, зокрема в економіці, фінансах, маркетингу та психології, щоб зрозуміти та передбачити взаємозв’язки між різними змінними. Це фундаментальний інструмент для аналізу даних і машинного навчання, який використовується для прогнозування, виявлення тенденцій і розуміння механізмів, що лежать в основі даних.
Наприклад, у простій моделі лінійної регресії метою може бути прогнозування ціни будинку на основі його розміру, розташування та інших характеристик. Розмір будинку та його розташування були б незалежними змінними, а ціна будинку була б залежною змінною.
Модель буде навчено на вхідних даних, які включають розмір і розташування кількох будинків разом із відповідними цінами. Коли модель навчена, її можна використовувати для прогнозування ціни будинку, враховуючи його розмір і розташування.
Типи алгоритмів регресії ML
Алгоритми регресії доступні в різних формах, і використання кожного алгоритму залежить від кількості параметрів, таких як тип значення атрибута, модель лінії тренду та кількість незалежних змінних. Методи регресії, які часто використовуються, включають:
Лінійна регресія
Ця проста лінійна модель використовується для прогнозування постійного значення на основі набору ознак. Він використовується для моделювання зв’язку між функціями та цільовою змінною шляхом підгонки лінії до даних.
Поліноміальна регресія
Це нелінійна модель, яка використовується для підгонки кривої до даних. Він використовується для моделювання зв’язків між ознаками та цільовою змінною, коли зв’язок не є лінійним. Він заснований на ідеї додавання членів вищого порядку до лінійної моделі, щоб охопити нелінійні зв’язки між залежними та незалежними змінними.
Хребтова регресія
Це лінійна модель, яка розглядає переобладнання в лінійній регресії. Це регуляризована версія лінійної регресії, яка додає штрафний термін до функції витрат, щоб зменшити складність моделі.
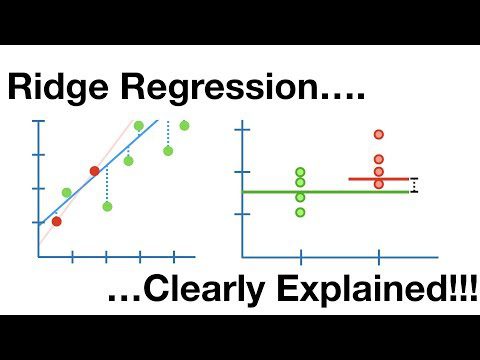
Підтримка векторної регресії
Як і SVM, опорна векторна регресія — це лінійна модель, яка намагається підігнати дані, знаходячи гіперплощину, яка максимізує запас між залежними та незалежними змінними.
Однак, на відміну від SVM, які використовуються для класифікації, SVR використовується для завдань регресії, де метою є прогнозування постійного значення, а не мітки класу.
Регресія ласо
Це ще одна регуляризована лінійна модель, яка використовується для запобігання переобладнанню в лінійній регресії. Він додає штрафний термін до функції витрат на основі абсолютного значення коефіцієнтів.
Байєсова лінійна регресія
Лінійна регресія Байєса — це ймовірнісний підхід до лінійної регресії, заснований на теоремі Байєса, який є способом оновлення ймовірності події на основі нових доказів.
Ця регресійна модель має на меті оцінити апостеріорний розподіл параметрів моделі за даними. Це робиться шляхом визначення попереднього розподілу за параметрами, а потім використання теореми Байєса для оновлення розподілу на основі спостережених даних.
Регресія проти класифікації
Регресія та класифікація — це два типи навчання під наглядом, що означає, що вони використовуються для прогнозування результату на основі набору вхідних характеристик. Однак між ними є кілька ключових відмінностей:
RegressionClassificationDefinitionТип контрольованого навчання, який передбачає безперервне значенняТип контрольованого навчання, який передбачає категоричне значення. Тип результату. Безперервний. Дискретний. Метрики оцінки. Середньоквадратична помилка (MSE), середньоквадратична помилка (RMSE). Точність, точність, відкликання, оцінка F1. Алгоритми. Дерево рішеньЛогістична регресія, SVM, Наївний Байєс, KNN, Дерево рішеньСкладність моделі Менш складні моделіБільш складні моделіПрипущенняЛінійний зв’язок між функціями та цільовим призначеннямНемає конкретних припущень щодо зв’язку між функціями та дисбалансом цільового класуНезастосовноЦе може бути проблемоюВикидиМоже впливати на продуктивність моделіЗвичайно не є проблемоюВажливість функціїФункції впорядковані за важливістюОсобливості не впорядковані за важливістю. Приклади програм. Прогнозування цін, температур, кількості. Прогнозування спаму електронною поштою, прогнозування відтоку клієнтів.
Навчальні ресурси
Може бути складно вибрати найкращі онлайн-ресурси для розуміння концепцій машинного навчання. Ми перевірили популярні курси, які надають надійні платформи, щоб надати вам наші рекомендації щодо найкращих курсів машинного навчання з регресії та класифікації.
#1. Класифікаційний курс машинного навчання на Python
Це курс, який пропонується на платформі Udemy. Він охоплює різноманітні алгоритми та методи класифікації, включаючи дерева рішень та логістичну регресію, а також підтримує векторні машини.

Ви також можете дізнатися про такі теми, як переобладнання, компроміс зміщення та оцінка моделі. У курсі використовуються бібліотеки Python, такі як sci-kit-learn і pandas, для реалізації та оцінки моделей машинного навчання. Отже, для початку вивчення цього курсу необхідні базові знання Python.
#2. Майстер-клас регресії машинного навчання на Python
У цьому курсі Udemy тренер охоплює основи та базову теорію різних алгоритмів регресії, включаючи лінійну регресію, поліноміальну регресію та методи регресії Ласо та Ріджа.
До кінця цього курсу ви зможете впроваджувати алгоритми регресії та оцінювати продуктивність навчених моделей машинного навчання за допомогою різних ключових показників ефективності.
Підведенню
Алгоритми машинного навчання можуть бути дуже корисними в багатьох програмах, і вони можуть допомогти автоматизувати та оптимізувати багато процесів. Алгоритми ML використовують статистичні методи, щоб вивчати шаблони в даних і робити прогнози або приймати рішення на основі цих шаблонів.
Їх можна навчити працювати з великими обсягами даних і використовувати для виконання завдань, які людям було б складно або довго виконувати вручну.
Кожен алгоритм ML має свої сильні та слабкі сторони, і вибір алгоритму залежить від характеру даних і вимог завдання. Важливо вибрати відповідний алгоритм або комбінацію алгоритмів для конкретної проблеми, яку ви намагаєтеся вирішити.
Важливо вибрати правильний тип алгоритму для вашої проблеми, оскільки використання неправильного типу алгоритму може призвести до низької продуктивності та неточних прогнозів. Якщо ви не впевнені, який алгоритм використовувати, може бути корисно спробувати як алгоритми регресії, так і алгоритми класифікації та порівняти їх ефективність у вашому наборі даних.
Сподіваюся, ця стаття була для вас корисною для вивчення регресії та класифікації в машинному навчанні. Вам також може бути цікаво дізнатися про найпопулярніші моделі машинного навчання.