
Машинам складно зрозуміти людські мови, оскільки вони містять багато абревіатур, різних значень, підсмислів, граматичних правил, контексту, сленгу та багатьох інших аспектів.
Але багато бізнес-процесів і операцій використовують машини та вимагають взаємодії між машинами та людьми.
Отже, вченим була потрібна технологія, яка допомогла б машині декодувати людські мови та спростила їх вивчення.
Саме тоді з’явилася обробка природної мови або алгоритми НЛП. Це зробило комп’ютерні програми здатними розуміти різні людські мови, незалежно від того, написані вони чи вимовлені.
НЛП використовує різні алгоритми для обробки мов. А з появою алгоритмів NLP ця технологія стала важливою частиною штучного інтелекту (ШІ), щоб допомогти оптимізувати неструктуровані дані.
У цій статті я обговорю НЛП і деякі з найбільш обговорюваних алгоритмів НЛП.
Давайте почнемо!
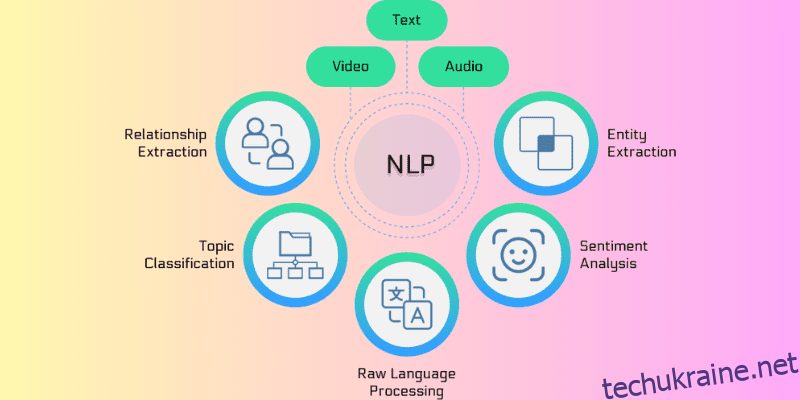
Що таке НЛП?
Процес природної мови (NLP) — це галузь інформатики, лінгвістики та штучного інтелекту, яка займається взаємодією між людською мовою та комп’ютером. Це допомагає програмувати машини так, щоб вони могли аналізувати та обробляти великі обсяги даних, пов’язаних із природними мовами.
Іншими словами, НЛП – це сучасна технологія або механізм, який використовується машинами для розуміння, аналізу та інтерпретації людської мови. Це дає машинам можливість розуміти тексти та розмовну мову людей. За допомогою NLP машини можуть виконувати переклад, розпізнавання мовлення, резюмування, сегментацію тем і багато інших завдань від імені розробників.
Найкраще те, що НЛП виконує всю роботу та завдання в режимі реального часу за допомогою кількох алгоритмів, що робить його набагато ефективнішим. Це одна з тих технологій, яка поєднує машинне навчання, глибоке навчання та статистичні моделі з обчислювальним моделюванням на основі лінгвістичних правил.
Алгоритми NLP дозволяють комп’ютерам обробляти людську мову за допомогою текстів або голосових даних і декодувати їх значення для різних цілей. Здатність комп’ютерів до інтерпретації розвинулася настільки, що машини можуть навіть зрозуміти людські почуття та наміри, що стоять за текстом. НЛП також може передбачати наступні слова або речення, які спадають на думку користувача, коли він пише або говорить.
Ця технологія існує десятиліттями, і з часом вона була оцінена та досягла кращої точності процесу. Коріння НЛП пов’язані з лінгвістикою і навіть допомогли розробникам створити пошукові системи для Інтернету. У міру розвитку технологій з часом використання НЛП розширилося.
Сьогодні НЛП знаходить застосування у величезній кількості галузей, від фінансів, пошукових систем і бізнес-аналітики до охорони здоров’я та робототехніки. Крім того, НЛП пішло глибоко в сучасні системи; він використовується для багатьох популярних програм, таких як GPS з голосовим керуванням, чат-боти для обслуговування клієнтів, цифрова допомога, перетворення мови в текст і багато іншого.
Як працює НЛП?
НЛП — це динамічна технологія, яка використовує різні методології для перекладу складної людської мови на машини. Він в основному використовує штучний інтелект для обробки та перекладу письмових або усних слів, щоб їх могли зрозуміти комп’ютери.
Подібно до того, як люди мають мозок для обробки всіх вхідних даних, комп’ютери використовують спеціалізовану програму, яка допомагає їм обробляти вхідні дані до зрозумілого результату. NLP працює в два етапи під час перетворення, де один – це обробка даних, а інший – розробка алгоритму.
Обробка даних є першою фазою, на якій вхідні текстові дані готуються та очищаються, щоб машина могла їх проаналізувати. Дані обробляються таким чином, щоб виділити всі особливості у введеному тексті та зробити його придатним для комп’ютерних алгоритмів. По суті, етап обробки даних готує дані у формі, яку може зрозуміти машина.
На цьому етапі використовуються такі техніки:
 Джерело: Амазин
Джерело: Амазин
- Токенізація: вхідний текст розділено на малі форми, щоб НЛП могла над ними працювати.
- Зупинка видалення слів: Техніка видалення стоп-слів видаляє всі знайомі слова з тексту та перетворює їх у форму, яка зберігає всю інформацію в мінімальному стані.
- Лематизація та коріння: Лематизація та коріння призводить до того, що слова зменшуються до кореневої структури, щоб машинам було легше їх обробити.
- Позначення частин мови: у такий спосіб введені слова позначаються на основі їхніх іменників, прикметників і дієслів, а потім вони обробляються.
Після того, як вхідні дані пройшли першу фазу, на наступній машині розробляється алгоритм, за яким вона може остаточно їх обробити. Серед усіх алгоритмів НЛП, які використовуються для обробки попередньо оброблених слів, широко використовуються системи на основі правил і машинного навчання:
- Системи на основі правил: тут система використовує лінгвістичні правила для остаточної обробки слів. Це старий алгоритм, який все ще використовується у великих масштабах.
- Системи на основі машинного навчання: це розширений алгоритм, який поєднує нейронні мережі, глибоке навчання та машинне навчання для визначення власного правила обробки слів. Оскільки в ньому використовуються статистичні методи, алгоритм вирішує обробку слів на основі навчальних даних і вносить зміни по ходу процесу.
Різні категорії алгоритмів НЛП
Алгоритми NLP — це алгоритми або інструкції на основі ML, які використовуються під час обробки природних мов. Вони займаються розробкою протоколів і моделей, які дозволяють машині інтерпретувати людські мови.

Алгоритми НЛП можуть змінювати свою форму відповідно до підходу штучного інтелекту, а також тренувальних даних, які вони отримували. Основне завдання цих алгоритмів полягає в тому, щоб використовувати різні методи для ефективного перетворення заплутаних або неструктурованих вхідних даних у обґрунтовану інформацію, на якій може навчатися машина.
Разом з усіма методами, алгоритми НЛП використовують принципи природної мови, щоб зробити вхідні дані кращими зрозумілими для машини. Вони відповідають за те, щоб допомогти машині зрозуміти контекстне значення даного введення; інакше машина не зможе виконати запит.
Алгоритми NLP поділяються на три різні основні категорії, а моделі ШІ вибирають будь-яку з категорій залежно від підходу дослідника даних. Ці категорії:
#1. Символічні алгоритми
Символічні алгоритми служать однією з основ алгоритмів НЛП. Вони відповідають за аналіз значення кожного введеного тексту, а потім за його використання для встановлення зв’язку між різними поняттями.
Символічні алгоритми використовують символи для представлення знань, а також зв’язку між поняттями. Оскільки ці алгоритми використовують логіку та призначають значення словам на основі контексту, ви можете досягти високої точності.
Графи знань також відіграють вирішальну роль у визначенні концепцій мови введення разом із зв’язком між цими концепціями. Завдяки здатності правильно визначати поняття та легко розуміти контексти слів, цей алгоритм допомагає створювати XAI.
Однак символічні алгоритми не можуть розширити набір правил через різні обмеження.
#2. Статистичні алгоритми
Статистичні алгоритми можуть полегшити роботу машин, переглядаючи тексти, розуміючи кожен із них і відновлюючи значення. Це високоефективний алгоритм НЛП, оскільки він допомагає машинам вивчати людську мову, розпізнаючи шаблони та тенденції в масиві вхідних текстів. Цей аналіз допомагає машинам передбачити, яке слово, ймовірно, буде написано після поточного слова в режимі реального часу.
Від розпізнавання мовлення, аналізу настроїв і машинного перекладу до пропонування тексту, статистичні алгоритми використовуються для багатьох програм. Основною причиною його широкого використання є те, що він може працювати з великими наборами даних.
Крім того, статистичні алгоритми можуть визначити, чи схожі за змістом два речення в абзаці та яке з них використовувати. Однак основним недоліком цього алгоритму є те, що він частково залежить від розробки складних функцій.
#3. Гібридні алгоритми
Цей тип алгоритму НЛП поєднує потужність як символічного, так і статистичного алгоритмів для отримання ефективного результату. Зосереджуючись на основних перевагах і функціях, можна легко звести нанівець максимальну слабкість будь-якого підходу, що важливо для високої точності.
Існує багато способів використання обох підходів:
- Символічна підтримка машинного навчання
- Машинне навчання підтримує символіку
- Символічне та машинне навчання працюють паралельно
Символьні алгоритми можуть підтримувати машинне навчання, допомагаючи йому навчити модель таким чином, що їй доводиться докладати менше зусиль для самостійного вивчення мови. Незважаючи на те, що машинне навчання підтримує символічні способи, модель ML може створити початковий набір правил для символічного і позбавити спеціаліста з даних від створення його вручну.
Однак коли символічне та машинне навчання працюють разом, це призводить до кращих результатів, оскільки може гарантувати, що моделі правильно розуміють певний фрагмент.
Найкращі алгоритми НЛП
Є численні алгоритми НЛП, які допомагають комп’ютеру емулювати людську мову для розуміння. Ось найкращі алгоритми НЛП, якими ви можете скористатися:
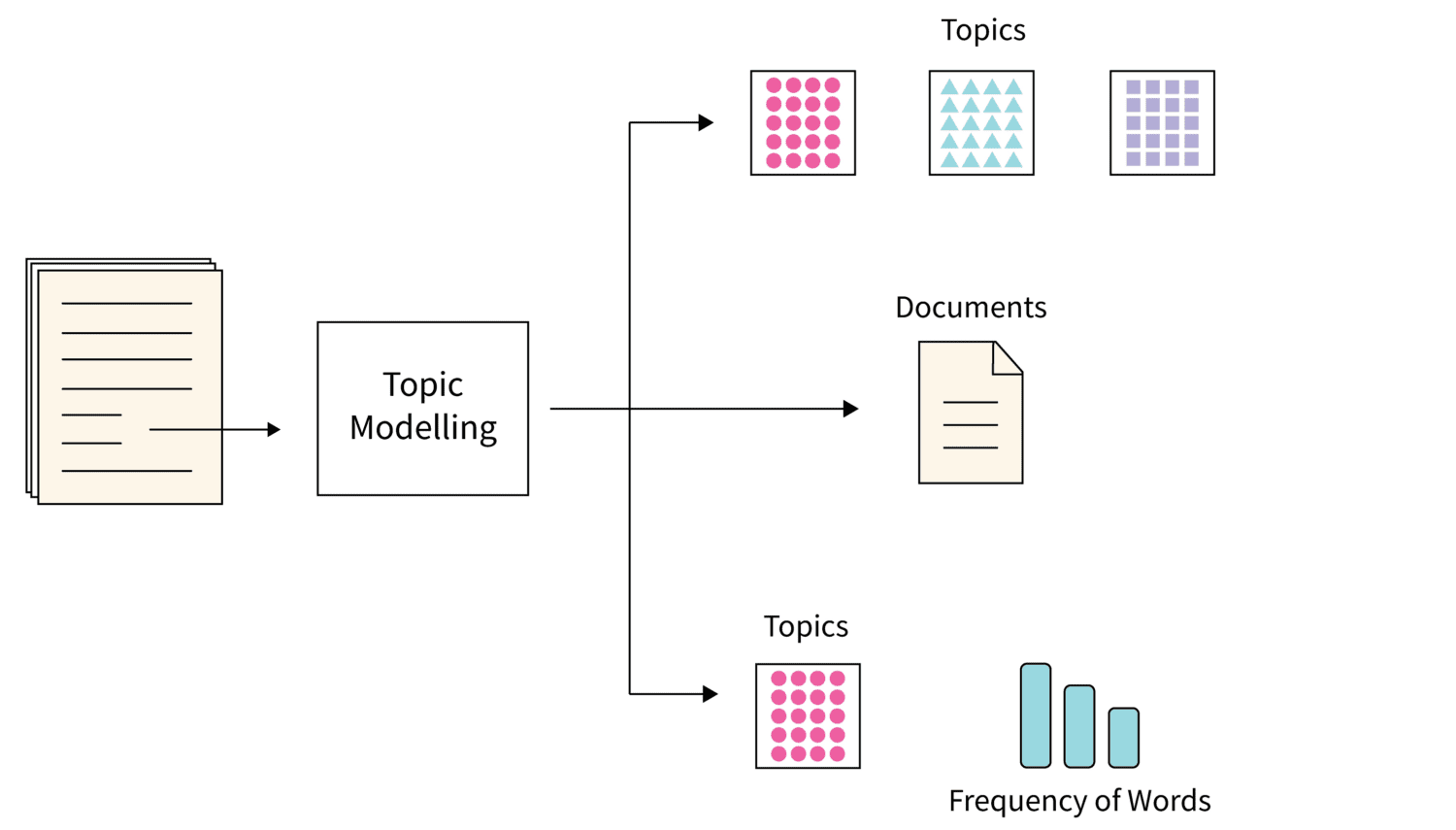
#1. Моделювання теми
 Джерело зображення: Scaler
Джерело зображення: Scaler
Моделювання тем є одним із тих алгоритмів, які використовують статистичні методи NLP, щоб знайти теми або основні теми з величезної купи текстових документів.
По суті, це допомагає машинам знаходити предмет, який можна використати для визначення певного текстового набору. Оскільки кожен корпус текстових документів містить численні теми, цей алгоритм використовує будь-яку відповідну техніку, щоб знайти кожну тему, оцінюючи окремі набори словникового запасу слів.
Прихований розподіл Діріхле є популярним вибором, коли йдеться про використання найкращої техніки для моделювання теми. Це неконтрольований алгоритм ML, який допомагає накопичувати та організовувати архіви великої кількості даних, які неможливо анотувати людиною.
#2. Конспектування тексту
Це дуже вимоглива техніка НЛП, де алгоритм коротко підсумовує текст, і це також у плавній формі. Це швидкий процес, оскільки резюмування допомагає отримати всю цінну інформацію, не переглядаючи кожне слово.
Узагальнення можна здійснити двома способами:
- Резюмування на основі вилучення: воно змушує машину витягувати лише основні слова та фрази з документа без змінення оригіналу.
- Резюмування на основі абстракції: у цьому процесі нові слова та фрази створюються з текстового документа, який відображає всю інформацію та наміри.
#3. Сентиментальний аналіз
Це алгоритм НЛП, який допомагає машині зрозуміти значення або намір тексту користувача. Він широко популярний і використовується в різних бізнес-моделях ШІ, оскільки допомагає компаніям зрозуміти, що клієнти думають про їхні продукти чи послуги.
Розуміючи намір текстових або голосових даних клієнта на різних платформах, моделі штучного інтелекту можуть розповісти вам про почуття клієнта та допомогти вам відповідним чином підійти до нього.
#4. Вилучення ключових слів
Вилучення ключових слів — ще один популярний алгоритм NLP, який допомагає витягувати велику кількість цільових слів і фраз із величезного набору текстових даних.
Існують різні алгоритми вилучення ключових слів, які включають такі популярні назви, як TextRank, Term Frequency і RAKE. Деякі з алгоритмів можуть використовувати додаткові слова, тоді як деякі з них можуть допомогти у вилученні ключових слів на основі вмісту певного тексту.
Кожен з алгоритмів вилучення ключових слів використовує власні теоретичні та фундаментальні методи. Це корисно для багатьох організацій, оскільки допомагає зберігати, шукати та отримувати вміст із значного набору неструктурованих даних.
#5. Графи знань
Коли справа доходить до вибору найкращого алгоритму НЛП, багато хто розглядає алгоритми графів знань. Це чудова техніка, яка використовує трійки для зберігання інформації.
Цей алгоритм по суті є сумішшю трьох речей – суб’єкта, предиката та сутності. Однак створення графа знань не обмежується однією технікою; натомість для більшої ефективності та деталізації потрібні численні техніки НЛП. Суб’єктний підхід використовується для вилучення впорядкованої інформації з купи неструктурованих текстів.
#6. TF-IDF
TF-IDF — це статистичний алгоритм NLP, який важливий для оцінки важливості слова для конкретного документа, що належить до великої колекції. Ця техніка передбачає множення відмітних значень, якими є:
- Частота термінів: значення частоти термінів дає вам загальну кількість разів, коли слово з’являється в певному документі. Стоп-слова зазвичай часто зустрічаються в документі.
- Зворотна частота документа. З іншого боку, зворотна частота документа виділяє терміни, які є дуже специфічними для документа, або слова, які рідше зустрічаються в цілому корпусі документів.
#7. Хмара слів
Words Cloud – це унікальний NLP-алгоритм, який використовує техніки візуалізації даних. У цьому алгоритмі важливі слова виділяються, а потім відображаються в таблиці.
Основні слова в документі надруковані великими літерами, а найменш важливі – дрібним шрифтом. Іноді менш важливі речі навіть не видно на столі.
Навчальні ресурси
Крім наведеної вище інформації, якщо ви хочете дізнатися більше про обробку природної мови (NLP), ви можете розглянути наступні курси та книги.
#1. Наука про дані: обробка природної мови в Python

Цей курс від Udemy отримав високу оцінку учнів і ретельно створений компанією Lazy Programmer Inc. Він навчає всьому про НЛП і алгоритми НЛП, а також навчає вас, як писати аналіз настроїв. Цей курс загальною тривалістю 11 годин 52 хвилини дає вам доступ до 88 лекцій.
#2. Обробка природної мови: НЛП із трансформаторами на Python
Завдяки цьому популярному курсу від Udemy ви не лише дізнаєтесь про НЛП із моделями трансформаторів, але й отримаєте можливість створювати налаштовані моделі трансформаторів. Цей курс повністю висвітлює НЛП із 11,5 годинами відео на вимогу та 5 статтями. Крім того, ви дізнаєтеся про методи побудови векторів і попередньої обробки текстових даних для НЛП.
#3. Обробка природної мови за допомогою трансформаторів
Ця книга була вперше випущена в 2017 році і мала на меті допомогти дослідникам обробки даних і програмістам дізнатися про НЛП. Коли ви почнете читати книгу, ви зможете будувати й оптимізувати моделі трансформаторів для багатьох завдань НЛП. Ви також дізнаєтесь, як можна використовувати трансформатори для міжмовного трансферного навчання.
#4. Практична обробка природної мови
У цій книзі автори пояснили завдання, проблеми та підходи до вирішення НЛП. У цій книзі також розповідається про впровадження та оцінку різних застосувань НЛП.
Висновок
НЛП є невід’ємною частиною сучасного світу ШІ, який допомагає машинам розуміти людські мови та інтерпретувати їх. Алгоритми НЛП стають корисними для різних додатків, від пошукових систем та ІТ до фінансів, маркетингу тощо.
Крім наведених вище деталей, я також перерахував деякі з найкращих курсів і книг з НЛП, які допоможуть вам покращити свої знання з НЛП.