Обробка великих масивів даних є однією з найбільш вимогливих задач для сучасних організацій. Ця складність зростає експоненційно, коли необхідно обробляти величезні обсяги інформації в режимі реального часу.
У цій статті ми розглянемо, що саме означає обробка великих даних, як вона відбувається, а також детально проаналізуємо два провідні інструменти в цій галузі: Apache Kafka та Spark.
Що таке обробка інформації та як вона здійснюється?
Обробка даних – це будь-яка дія або послідовність дій, які виконуються над інформацією, незалежно від того, чи є цей процес автоматизованим. Її суть полягає у зборі, впорядкуванні та структуруванні інформації у відповідності до логічних принципів для подальшого аналізу.
Коли користувач надсилає запит до бази даних і отримує результати, саме обробка даних забезпечує надання відповідної інформації. Отримана інформація є результатом цього процесу. Саме тому інформаційні технології приділяють значну увагу обробці даних.
Раніше обробка даних здійснювалася за допомогою простого програмного забезпечення. Однак, з появою концепції Big Data, ситуація кардинально змінилася. “Великі дані” – це інформаційні масиви, обсяг яких може сягати сотень терабайт і навіть петабайт.
Крім того, така інформація постійно оновлюється. Прикладом можуть бути дані з контакт-центрів, соціальних мереж, біржових торгів тощо. Ці дані часто називають “потоком даних” – безперервним, неконтрольованим потоком інформації. Головна його особливість полягає у відсутності чітких меж, що унеможливлює визначення початку або кінця цього потоку.
Дані обробляються в момент їхнього надходження. Деякі спеціалісти називають цей процес “обробкою в реальному часі” або “онлайн-обробкою”. Альтернативний підхід – це обробка блоками або “пакетна обробка”, коли дані обробляються у визначені часові проміжки (години або дні). Часто пакетна обробка виконується вночі, консолідуючи дані за день. Існують також випадки, коли часові інтервали у тиждень або місяць створюють застарілі звіти.
Оскільки провідні платформи для обробки великих даних є відкритими джерелами, такі як Kafka та Spark, це дозволяє використовувати їх у поєднанні з іншими додатковими платформами. Відкритий код сприяє швидшому розвитку та інтеграції з різноманітними інструментами. Таким чином, дані надходять з різних джерел без перерв та зі змінною швидкістю.
Далі ми розглянемо два найбільш відомі інструменти для обробки даних та порівняємо їхні можливості:
Apache Kafka
Apache Kafka – це платформа обміну повідомленнями, призначена для створення потокових додатків, що працюють з безперервними потоками даних. Розроблена спочатку в LinkedIn, Kafka базується на концепції “журналу”. Журнал є основним способом зберігання, де кожна нова порція інформації додається в кінець файлу.

Kafka є одним з провідних рішень для роботи з великими даними, завдяки своїй високій пропускній здатності. За допомогою Apache Kafka можна перетворити навіть пакетну обробку в обробку в реальному часі.
Apache Kafka – це система обміну повідомленнями за принципом “публікація-підписка”, де додаток публікує повідомлення, а підписаний додаток їх отримує. Час між публікацією та отриманням повідомлення може становити мілісекунди, що робить Kafka рішенням з низькою затримкою.
Структура Кафки
Архітектура Apache Kafka включає видавців, споживачів і сам кластер. Видавцем є будь-який додаток, що публікує повідомлення в кластер. Споживачем є будь-який додаток, що отримує повідомлення від Kafka. Кластер Kafka – це набір вузлів, які працюють як єдиний екземпляр сервісу обміну повідомленнями.
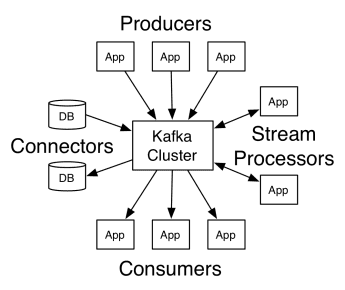 Структура Кафки
Структура Кафки
Кластер Kafka складається з кількох брокерів. Брокер – це сервер Kafka, що отримує повідомлення від видавців та записує їх на диск. Кожен брокер керує списком “топіків”, і кожен топік поділений на декілька розділів.
Після отримання повідомлень брокер розсилає їх зареєстрованим споживачам для кожного конкретного топіка.
Налаштуваннями Apache Kafka керує Apache Zookeeper, що зберігає метадані кластера, такі як місцезнаходження розділів, список імен, список топіків та доступні вузли. Zookeeper забезпечує синхронізацію між різними елементами кластера.
Zookeeper є важливим елементом, оскільки Kafka – це розподілена система. Запис і читання даних здійснюється декількома клієнтами одночасно. У випадку збою, Zookeeper обирає заміну та відновлює роботу.
Сценарії використання
Kafka набула популярності, особливо як інструмент для обміну повідомленнями, але її універсальність виходить за ці рамки. Її можна використовувати у різних сценаріях, приклади яких наведено нижче.
Обмін повідомленнями
Асинхронна форма зв’язку, що роз’єднує сторони, що спілкуються. В цій моделі одна сторона надсилає дані як повідомлення до Kafka, а інший додаток споживає їх пізніше.
Відстеження дій
Дозволяє зберігати та обробляти дані про взаємодію користувача з вебсайтом, наприклад перегляди сторінок, кліки, введення даних тощо. Цей тип діяльності зазвичай генерує величезний обсяг даних.
Метрики
Включає агрегування даних та статистичних даних з багатьох джерел для створення централізованого звіту.
Агрегація логів
Централізовано збирає та зберігає файли логів, отримані з різних систем.
Потокова обробка
Обробка конвеєрів даних складається з кількох етапів, де необроблені дані з топіків споживаються, агрегуються, збагачуються або перетворюються на інші топіки.
Для підтримки цих функцій платформа надає три основні API:
- Streams API: виступає як потоковий процесор, що споживає дані з одного топіка, перетворює їх і записує в інший.
- API конекторів: дозволяє підключати топіки до існуючих систем, таких як реляційні бази даних.
- API видавця та споживача: дає можливість додаткам публікувати та використовувати дані Kafka.
Переваги
Репліковано, розділено та впорядковано
Повідомлення в Kafka реплікуються між розділами на вузлах кластера в порядку надходження, щоб забезпечити надійність і швидкість доставки.
Перетворення даних
Завдяки Apache Kafka можна трансформувати пакетну обробку в реальному часі за допомогою Streams API для ETL.
Послідовний доступ до диска
Apache Kafka зберігає повідомлення на диску, а не в оперативній пам’яті, оскільки це забезпечує більшу ефективність. Хоча доступ до пам’яті зазвичай швидший, особливо при випадковому доступі до даних, Kafka використовує послідовний доступ, що робить диск більш ефективним в цьому випадку.
Apache Spark
Apache Spark – це механізм обробки великих даних та набір бібліотек для паралельної обробки даних у кластерах. Spark є еволюцією Hadoop та парадигми програмування Map-Reduce. Він може бути в 100 разів швидшим завдяки ефективному використанню пам’яті, не зберігаючи дані на дисках під час обробки.
Spark організовано на трьох рівнях:
- API низького рівня: цей рівень містить базові функції для виконання завдань та інші функції, необхідні для інших компонентів. Інші важливі функції цього рівня включають управління безпекою, мережею, планування та логічний доступ до файлових систем HDFS, GlusterFS, Amazon S3 та інших.
- Структуровані API: Рівень структурованого API забезпечує маніпулювання даними за допомогою наборів даних або фреймів даних, що можуть бути прочитані з форматів, таких як Hive, Parquet, JSON та інші. За допомогою SparkSQL (API, який дозволяє писати запити SQL) ми можемо маніпулювати даними, як нам потрібно.
- Високий рівень: на найвищому рівні знаходиться екосистема Spark з різноманітними бібліотеками, включаючи Spark Streaming, Spark MLlib та Spark GraphX. Вони відповідають за обробку потокових даних, відновлення після збоїв, створення та валідацію моделей машинного навчання, а також роботу з графами та алгоритмами.
Робота Spark
Архітектура програми Spark складається з трьох основних компонентів:
Програма-драйвер: відповідає за організацію виконання обробки даних.
Менеджер кластера: компонент, що керує різними машинами у кластері. Потрібен лише, якщо Spark працює в розподіленому режимі.
Робочі вузли: машини, що виконують завдання програми. Якщо Spark запускається локально на вашій машині, він виконує роль як програми-драйвера, так і робочих вузлів. Цей спосіб запуску Spark називається Standalone.
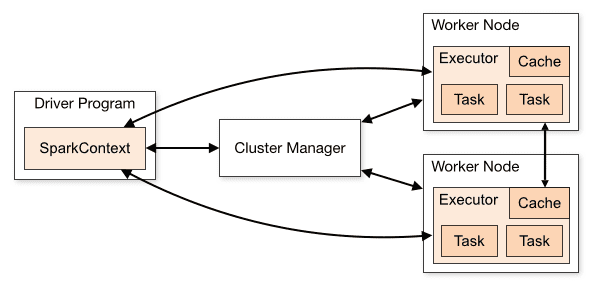 Огляд кластера
Огляд кластера
Код Spark можна написати на кількох різних мовах. Консоль Spark, відома як Spark Shell, є інтерактивною для вивчення та аналізу даних.
Так звана програма Spark складається з одного або декількох завдань, забезпечуючи підтримку масштабної обробки даних.
Spark має два режими виконання:
- Клієнт: драйвер запускається безпосередньо на клієнті, без проходження через диспетчер ресурсів.
- Кластер: драйвер запускається на головному пристрої програми через диспетчер ресурсів (у режимі кластера, якщо клієнт від’єднається, програма продовжить роботу).
Необхідно правильно використовувати Spark, щоб зв’язані служби, такі як Resource Manager, могли визначити потреби кожного виконання, забезпечуючи оптимальну продуктивність. Розробник повинен розуміти, як найкраще виконувати завдання Spark, структурувати виклики та налаштовувати виконавців Spark відповідно до потреб.
Завдання Spark в основному використовують пам’ять, тому зазвичай налаштовують значення конфігурації Spark для виконавців робочих вузлів. Залежно від робочого навантаження, можна визначити, що певна нестандартна конфігурація Spark забезпечує краще виконання. Для цього можна проводити порівняльні тести між різними конфігураціями та стандартними налаштуваннями Spark.
Сценарії використання
Apache Spark допомагає обробляти величезні обсяги даних, як у реальному часі, так і архівних, структурованих чи неструктурованих. Нижче наведено деякі популярні випадки використання.
Збагачення даних
Компанії часто використовують комбінацію історичних даних про клієнтів з даними про поведінку в реальному часі. Spark може допомогти створити безперервний конвеєр ETL для перетворення неструктурованих даних подій на структуровані дані.
Активація виявлення подій
Spark Streaming дозволяє швидко виявляти та реагувати на певну рідкісну або підозрілу поведінку, що може вказувати на потенційні проблеми або шахрайство.
Комплексний аналіз даних сесії
З Spark Streaming можна групувати та аналізувати події, пов’язані з сесією користувача, наприклад дії після входу в програму. Цю інформацію можна також використовувати для постійного оновлення моделей машинного навчання.
Переваги
Ітеративна обробка
Якщо завдання полягає в повторній обробці даних, відмовостійкі розподілені набори даних (RDD) Spark дозволяють виконувати декілька операцій з картами в пам’яті без необхідності записувати проміжні результати на диск.
Обробка графіків
Обчислювальна модель Spark із GraphX API чудово підходить для ітераційних обчислень, типових для обробки графів.
Машинне навчання
Spark має MLlib – вбудовану бібліотеку машинного навчання, яка містить готові алгоритми, що також працюють в пам’яті.
Kafka проти Spark
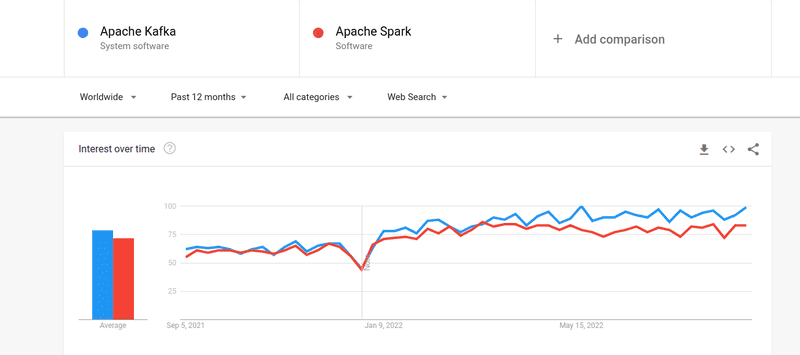
Незважаючи на те, що інтерес до Kafka та Spark є приблизно однаковим, між ними існують серйозні відмінності. Давайте їх розглянемо.
#1. Обробка даних
Kafka – це інструмент потокової передачі та зберігання даних у реальному часі, призначений для передачі даних між додатками. Однак, цього недостатньо для створення комплексного рішення. Для завдань, яких немає у Kafka, потрібні інші інструменти, такі як Spark. Spark, в свою чергу, є платформою для пакетної обробки даних, яка отримує дані з топіків Kafka та перетворює їх у зведені схеми.
#2. Управління пам’яттю
Spark використовує надійні розподілені набори даних (RDD) для управління пам’яттю. Замість обробки великих обсягів даних на одному вузлі, він розподіляє їх між кількома вузлами кластера. Kafka, навпаки, використовує послідовний доступ, подібний до HDFS, та зберігає дані в буферній пам’яті.
#3. Перетворення ETL
І Spark, і Kafka підтримують процес перетворення ETL, який копіює записи з однієї бази даних в іншу, зазвичай з транзакційної бази (OLTP) в аналітичну основу (OLAP). Однак, на відміну від Spark, що має вбудовані можливості для ETL, Kafka використовує Streams API для підтримки цього процесу.
#4. Постійність даних

Використання RDD в Spark дозволяє зберігати дані в кількох місцях для подальшого використання. У Kafka потрібно визначити об’єкти набору даних в конфігурації для збереження даних.
#5. Складність
Spark є комплексним рішенням, яке легше освоїти завдяки підтримці різних мов програмування високого рівня. Kafka залежить від ряду різних API та сторонніх модулів, що може ускладнити роботу.
#6. Відновлення
Spark та Kafka пропонують варіанти відновлення. Spark використовує RDD, що дозволяє постійно зберігати дані, і в разі збою кластера вони можуть бути відновлені.

Kafka постійно копіює дані всередині кластера та реплікує між брокерами, що дозволяє переключатися на інші брокери в разі збою.
Подібності між Spark та Kafka
| Apache Spark | Apache Kafka |
| Open Source | Open Source |
| Build Data Streaming Application | Build Data Streaming Application |
| Supports Stateful Processing | Supports Stateful Processing |
| Supports SQL | Supports SQL |
Підсумки
Kafka та Spark є інструментами з відкритим вихідним кодом, написаними на Scala та Java, які дозволяють створювати програми потокової обробки даних у реальному часі. Вони мають декілька спільних рис, включаючи обробку стану, підтримку SQL та ETL. Kafka та Spark можна також використовувати як додаткові інструменти для вирішення проблеми складної передачі даних між додатками.