

Дані є невід’ємною частиною бізнесу та організацій, і вони цінні лише тоді, коли вони правильно структуровані та ефективні.
Згідно зі статистичними даними, 95% підприємств сьогодні вважають проблемою управління та структурування неструктурованих даних.
Ось тут і з’являється інтелектуальний аналіз даних. Це процес виявлення, аналізу та вилучення значущих шаблонів і цінної інформації з великих наборів неструктурованих даних.
Компанії використовують програмне забезпечення для виявлення шаблонів у великих пакетах даних, щоб дізнатися більше про своїх клієнтів і цільову аудиторію та розробити бізнес-стратегії та маркетингові стратегії для покращення продажів і зниження витрат.
Окрім цієї переваги, виявлення шахрайства та аномалій є найважливішими застосуваннями інтелектуального аналізу даних.
У цій статті пояснюється виявлення аномалій і далі досліджується, як це може допомогти запобігти витоку даних і мережевим вторгненням для забезпечення безпеки даних.
Що таке виявлення аномалій та їх типи?
Хоча інтелектуальний аналіз даних передбачає пошук закономірностей, кореляцій і тенденцій, які пов’язані між собою, це чудовий спосіб знайти аномалії або викиди даних у мережі.
Аномалії інтелектуального аналізу даних – це точки даних, які відрізняються від інших точок даних у наборі даних і відхиляються від нормальної моделі поведінки набору даних.
Аномалії можна класифікувати за різними типами та категоріями, зокрема:
- Зміни в подіях: стосуються раптових або систематичних змін у порівнянні з попередньою нормальною поведінкою.
- Викиди: невеликі аномальні шаблони, які несистематично з’являються під час збору даних. Їх можна далі класифікувати на глобальні, контекстуальні та колективні викиди.
- Дрейфи: поступові, ненаправлені та довгострокові зміни в наборі даних.
Таким чином, виявлення аномалій є дуже корисною технікою обробки даних для виявлення шахрайських транзакцій, обробки тематичних досліджень із дисбалансом високого класу та виявлення захворювань для побудови надійних моделей науки про дані.
Наприклад, компанія може захотіти проаналізувати свій грошовий потік, щоб знайти незвичайні або повторювані транзакції на невідомий банківський рахунок, щоб виявити шахрайство та провести подальше розслідування.
Переваги виявлення аномалій
Виявлення аномалій у поведінці користувачів допомагає зміцнити системи безпеки та зробити їх точнішими.
Він аналізує та осмислює різноманітну інформацію, яку надають системи безпеки, щоб ідентифікувати загрози та потенційні ризики в мережі.
Ось переваги виявлення аномалій для компаній:
- Виявлення в режимі реального часу загроз кібербезпеці та витоків даних, оскільки алгоритми штучного інтелекту (ШІ) постійно сканують ваші дані, щоб виявити незвичайну поведінку.
- Це робить відстеження аномальних дій і шаблонів швидшим і легшим, ніж ручне виявлення аномалій, скорочуючи роботу та час, необхідні для усунення загроз.
- Мінімізує операційні ризики шляхом виявлення операційних помилок, таких як раптові падіння продуктивності, ще до їх виникнення.
- Це допомагає усунути серйозні збитки бізнесу шляхом швидкого виявлення аномалій, оскільки без системи виявлення аномалій компаніям можуть знадобитися тижні та місяці, щоб виявити потенційні загрози.
Таким чином, виявлення аномалій є величезним активом для компаній, які зберігають великі набори клієнтських і бізнес-даних, щоб знайти можливості для зростання та усунути загрози безпеці та операційні вузькі місця.
Методи виявлення аномалій
Виявлення аномалій використовує кілька процедур і алгоритмів машинного навчання (ML) для моніторингу даних і виявлення загроз.
Ось основні методи виявлення аномалій:
#1. Методи машинного навчання

Методи машинного навчання використовують алгоритми ML для аналізу даних і виявлення аномалій. Різні типи алгоритмів машинного навчання для виявлення аномалій включають:
- Алгоритми кластеризації
- Алгоритми класифікації
- Алгоритми глибокого навчання
А стандартні методи ML для виявлення аномалій і загроз включають машини опорних векторів (SVM), кластеризацію k-середніх і автокодери.
#2. Статистичні методи
Статистичні методи використовують статистичні моделі для виявлення незвичайних моделей (наприклад, незвичайних коливань у продуктивності певної машини) у даних для виявлення значень, які виходять за межі діапазону очікуваних значень.
Загальні методи статистичного виявлення аномалій включають перевірку гіпотез, IQR, Z-показник, модифікований Z-показник, оцінку щільності, коробковий графік, аналіз екстремальних значень і гістограму.
#3. Методи інтелектуального аналізу даних

Методи аналізу даних використовують методи класифікації даних і кластеризації, щоб знайти аномалії в наборі даних. Деякі поширені методи аналізу даних включають спектральну кластеризацію, кластеризацію на основі щільності та аналіз головних компонентів.
Алгоритми інтелектуального аналізу даних кластеризації використовуються для групування різних точок даних у кластери на основі їх подібності для пошуку точок даних і аномалій, що виходять за межі цих кластерів.
З іншого боку, алгоритми класифікації розподіляють точки даних для конкретних попередньо визначених класів і виявляють точки даних, які не належать до цих класів.
#4. Методи, засновані на правилах
Як випливає з назви, методи виявлення аномалій на основі правил використовують набір заздалегідь визначених правил для пошуку аномалій у даних.
Ці методи порівняно прості та прості в налаштуванні, але вони можуть бути негнучкими та неефективними в адаптації до мінливої поведінки та шаблонів даних.
Наприклад, ви можете легко запрограмувати систему на основі правил, щоб позначати транзакції, що перевищують певну суму в доларах, як шахрайські.
#5. Доменно-специфічні методи
Для виявлення аномалій у певних системах даних можна використовувати методи, що стосуються домену. Однак, хоча вони можуть бути дуже ефективними у виявленні аномалій у певних доменах, вони можуть бути менш ефективними в інших доменах поза вказаним.
Наприклад, використовуючи предметно-спеціальні методи, ви можете розробити методи спеціально для пошуку аномалій у фінансових операціях. Але вони можуть не працювати для пошуку аномалій або падіння продуктивності машини.
Необхідність машинного навчання для виявлення аномалій
Машинне навчання є дуже важливим і дуже корисним у виявленні аномалій.
Сьогодні більшість компаній і організацій, яким потрібне виявлення викидів, мають справу з величезними обсягами даних, від тексту, інформації про клієнтів і транзакцій до медіафайлів, таких як зображення та відеовміст.
Переглядати всі банківські транзакції та дані, що генеруються щосекунди вручну, щоб отримати значущу інформацію, майже неможливо. Крім того, більшість компаній стикаються з проблемами та великими труднощами у структуруванні неструктурованих даних і впорядкуванні даних у значущий спосіб для аналізу даних.
Саме тут такі інструменти та методи, як машинне навчання (ML), відіграють величезну роль у зборі, очищенні, структуруванні, упорядкуванні, аналізі та зберіганні величезних обсягів неструктурованих даних.
Методи та алгоритми машинного навчання обробляють великі набори даних і забезпечують гнучкість використання та комбінування різних методів і алгоритмів для отримання найкращих результатів.
Крім того, машинне навчання також допомагає оптимізувати процеси виявлення аномалій для реальних програм і заощаджує цінні ресурси.
Ось ще деякі переваги та важливість машинного навчання для виявлення аномалій:
- Це полегшує виявлення аномалій масштабування, автоматизуючи ідентифікацію шаблонів і аномалій без необхідності явного програмування.
- Алгоритми машинного навчання добре адаптуються до змін шаблонів наборів даних, що робить їх високоефективними та надійними з часом.
- Легко обробляє великі та складні набори даних, роблячи виявлення аномалій ефективним, незважаючи на складність набору даних.
- Забезпечує ранню ідентифікацію та виявлення аномалій шляхом виявлення аномалій у міру їх виникнення, заощаджуючи час і ресурси.
- Системи виявлення аномалій на основі машинного навчання допомагають досягти більш високого рівня точності виявлення аномалій порівняно з традиційними методами.
Таким чином, виявлення аномалій у поєднанні з машинним навчанням допомагає швидшому та більш ранньому виявленню аномалій, щоб запобігти загрозам безпеці та зловмисним порушенням.
Алгоритми машинного навчання для виявлення аномалій
Ви можете виявити аномалії та викиди в даних за допомогою різних алгоритмів інтелектуального аналізу даних для класифікації, кластеризації або вивчення правил асоціації.
Як правило, ці алгоритми інтелектуального аналізу даних класифікуються на дві різні категорії — контрольовані та неконтрольовані алгоритми навчання.
Контрольоване навчання
Контрольоване навчання – це поширений тип алгоритму навчання, який складається з таких алгоритмів, як опорні векторні машини, логістична та лінійна регресія та багатокласова класифікація. Цей тип алгоритму навчається на позначених даних, тобто його навчальний набір даних включає як звичайні вхідні дані, так і відповідні правильні вихідні або аномальні приклади для побудови прогнозної моделі.
Таким чином, його мета полягає в тому, щоб зробити вихідні прогнози для невидимих і нових даних на основі шаблонів набору даних навчання. Застосування алгоритмів навчання під наглядом включає розпізнавання зображень і мови, прогнозне моделювання та обробку природної мови (NLP).
Навчання без контролю
Неконтрольоване навчання не навчається на жодних позначених даних. Натомість він виявляє складні процеси та базові структури даних, не надаючи вказівок щодо алгоритму навчання та замість того, щоб робити конкретні прогнози.
Застосування алгоритмів неконтрольованого навчання включає виявлення аномалій, оцінку щільності та стиснення даних.
Тепер давайте розглянемо деякі популярні алгоритми виявлення аномалій на основі машинного навчання.
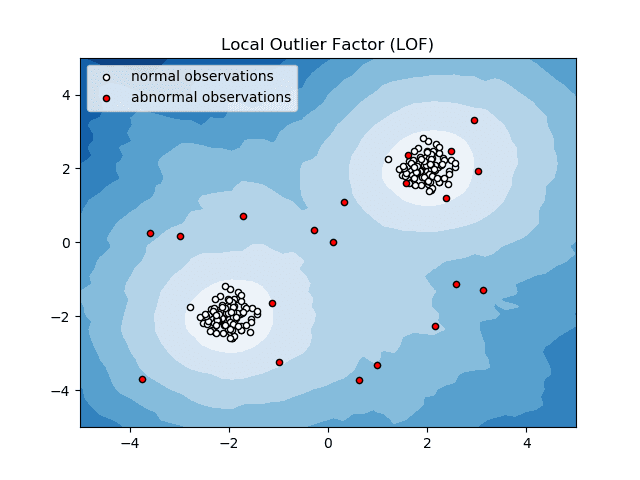
Фактор локального викиду (LOF)
Фактор локального викиду або LOF – це алгоритм виявлення аномалії, який враховує локальну щільність даних, щоб визначити, чи є точка даних аномалією.
 Джерело: scikit-learn.org
Джерело: scikit-learn.org
Він порівнює локальну щільність об’єкта з локальною щільністю його сусідів, щоб проаналізувати області з подібною щільністю та елементи з порівняно нижчою щільністю, ніж їхні сусіди, — що є нічим іншим, як аномаліями чи викидами.
Таким чином, кажучи простою мовою, щільність навколо вибраного або аномального елемента відрізняється від щільності навколо його сусідів. Отже, цей алгоритм також називають алгоритмом виявлення викидів на основі щільності.
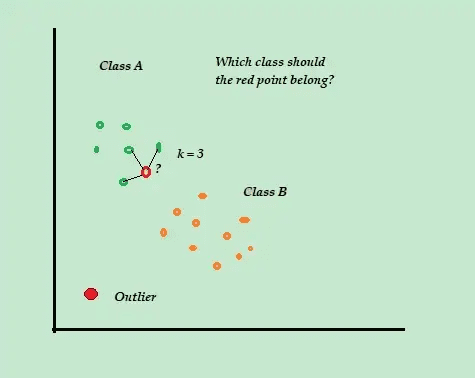
K-найближчий сусід (K-NN)
K-NN — це найпростіший алгоритм класифікації та контрольованого виявлення аномалій, який легко реалізувати, зберігає всі доступні приклади та дані та класифікує нові приклади на основі подібності в показниках відстані.
 Джерело:warddatascience.com
Джерело:warddatascience.com
Цей алгоритм класифікації також називають ледачим учнем, оскільки він зберігає лише позначені навчальні дані, не роблячи нічого під час процесу навчання.
Коли надходить нова непомічена точка навчальних даних, алгоритм переглядає K-найближчі або найближчі навчальні точки даних, щоб використовувати їх для класифікації та визначення класу нової непоміченої точки даних.
Алгоритм K-NN використовує такі методи виявлення для визначення найближчих точок даних:
- Евклідова відстань для вимірювання відстані для безперервних даних.
- Відстань Хеммінга для вимірювання близькості або «близькості» двох текстових рядків для дискретних даних.
Наприклад, уявіть, що ваші навчальні набори даних складаються з двох міток класу, A і B. Якщо надходить нова точка даних, алгоритм обчислить відстань між новою точкою даних і кожною з точок даних у наборі даних і вибере точки які є максимальними за кількістю, найближчими до нової точки даних.
Отже, припустимо, що K=3 і 2 із 3 точок даних позначено як A, тоді нова точка даних позначена як клас A.
Таким чином, алгоритм K-NN найкраще працює в динамічних середовищах із вимогами частого оновлення даних.
Це популярний алгоритм виявлення аномалій і аналізу тексту, який застосовується у фінансах і бізнесі для виявлення шахрайських транзакцій і підвищення рівня виявлення шахрайства.
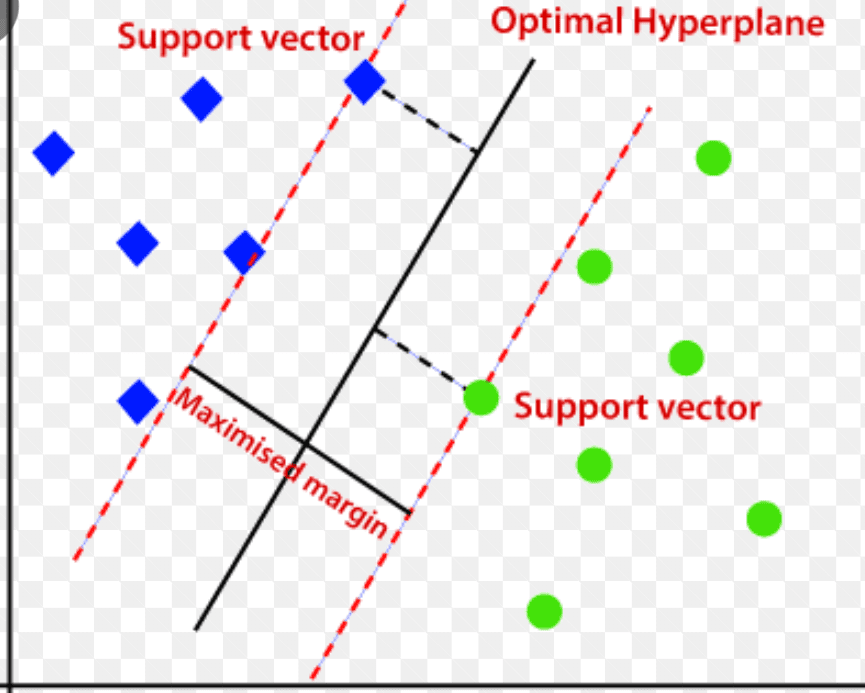
Машина підтримки векторів (SVM)
Машина опорних векторів – це керований алгоритм виявлення аномалій на основі машинного навчання, який переважно використовується в задачах регресії та класифікації.
Він використовує багатовимірну гіперплощину для розділення даних на дві групи (нові та нормальні). Таким чином, гіперплощина діє як межа прийняття рішень, яка розділяє нормальні дані спостережень і нові дані.
 Джерело: www.analyticsvidhya.com
Джерело: www.analyticsvidhya.com
Відстань між цими двома точками даних називають полями.
Оскільки метою є збільшення відстані між двома точками, SVM визначає найкращу або оптимальну гіперплощину з максимальним запасом, щоб забезпечити якомога більшу відстань між двома класами.
Що стосується виявлення аномалій, SVM обчислює маржу спостереження нової точки даних від гіперплощини, щоб класифікувати її.
Якщо маржа перевищує встановлений поріг, це класифікує нове спостереження як аномалію. У той же час, якщо запас менше порогового значення, спостереження класифікується як нормальне.
Таким чином, алгоритми SVM є високоефективними в обробці великорозмірних і складних наборів даних.
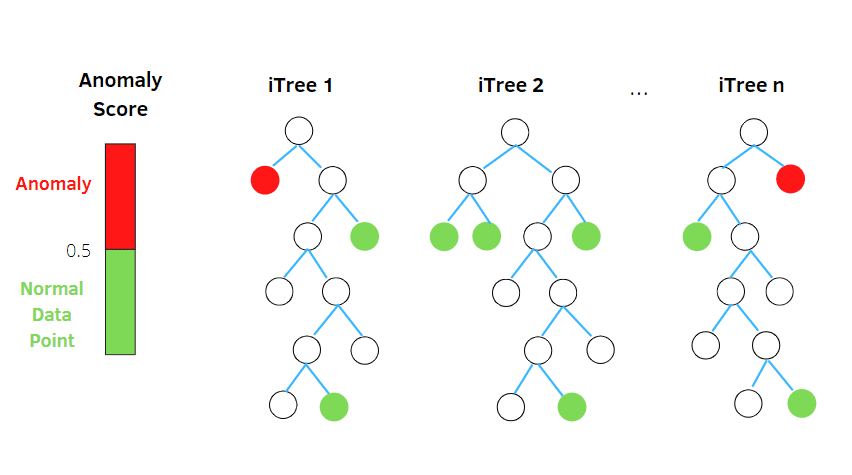
Ізольований ліс
Ізоляційний ліс — це алгоритм виявлення аномалій з машинним навчанням без нагляду, заснований на концепції класифікатора випадкового лісу.
 Джерело: betterprogramming.pub
Джерело: betterprogramming.pub
Цей алгоритм обробляє дані з випадковою підвибіркою в наборі даних у структурі дерева на основі випадкових атрибутів. Він створює кілька дерев рішень для ізоляції спостережень. І він вважає конкретне спостереження аномалією, якщо воно ізольовано на меншій кількості дерев на основі рівня забруднення.
Таким чином, простими словами, алгоритм ізоляційного лісу розбиває точки даних на різні дерева рішень, гарантуючи, що кожне спостереження буде ізольовано від іншого.
Аномалії зазвичай знаходяться далеко від кластера точок даних, що полегшує ідентифікацію аномалій порівняно зі звичайними точками даних.
Алгоритми ізольованого лісу можуть легко обробляти категоріальні та числові дані. Як наслідок, вони швидше навчаються та високоефективні у виявленні аномалій великого розміру та великих наборів даних.
Міжквартильний діапазон
Міжквартильний діапазон або IQR використовується для вимірювання статистичної варіабельності або статистичної дисперсії, щоб знайти аномальні точки в наборах даних шляхом їх розподілу на квартилі.
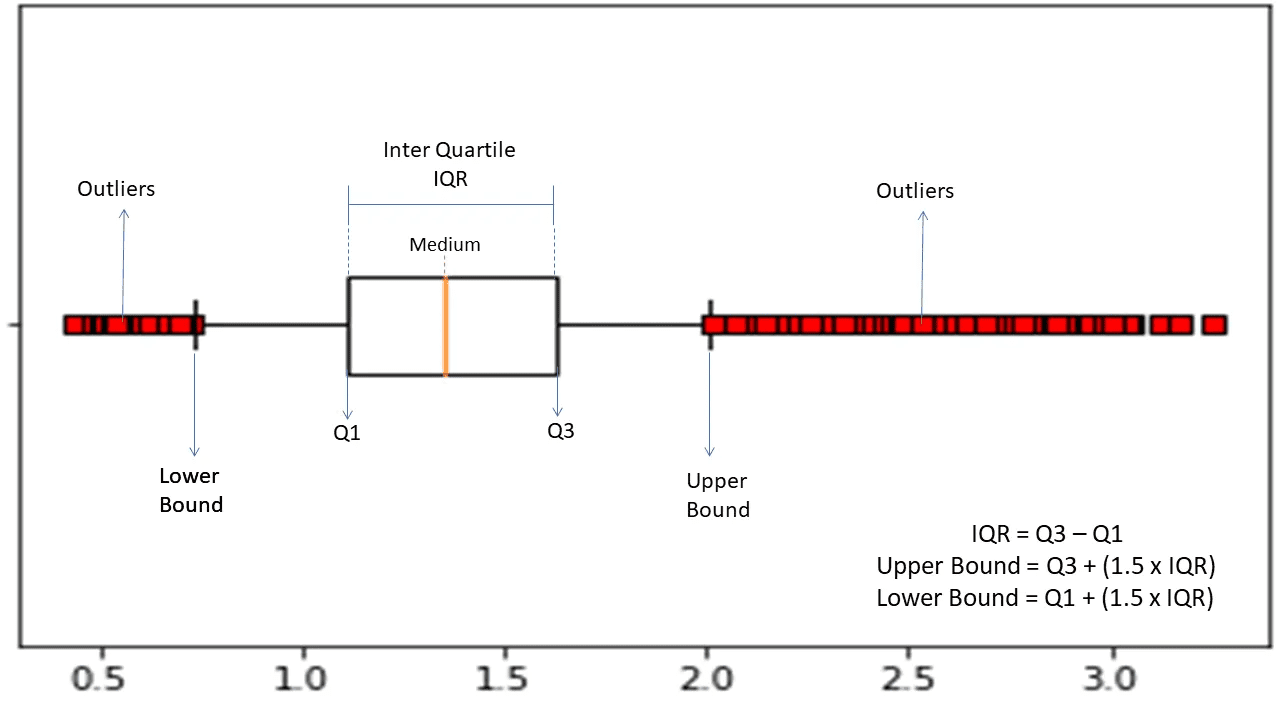 Джерело: morioh.com
Джерело: morioh.com
Алгоритм сортує дані в порядку зростання і розбиває набір на чотири рівні частини. Значеннями, що розділяють ці частини, є Q1, Q2 і Q3 — перший, другий і третій квартилі.
Ось процентиль розподілу цих квартилів:
- Q1 означає 25-й процентиль даних.
- Q2 означає 50-й процентиль даних.
- Q3 означає 75-й процентиль даних.
IQR – це різниця між третім (75-м) і першим (25-м) процентилем наборів даних, що становить 50% даних.
Використання IQR для виявлення аномалій вимагає від вас обчислити IQR вашого набору даних і визначити нижню та верхню межі даних для пошуку аномалій.
- Нижня межа: Q1 – 1,5 * IQR
- Верхня межа: Q3 + 1,5 * IQR
Як правило, спостереження, що виходять за межі цих меж, вважаються аномаліями.
Алгоритм IQR ефективний для наборів даних з нерівномірно розподіленими даними та де розподіл не зовсім зрозумілий.
Заключні слова
Ризики кібербезпеки та витоку даних, схоже, не зменшаться в найближчі роки — і очікується, що ця ризикована галузь буде розвиватися далі в 2023 році, і очікується, що лише кібератаки IoT подвоїться до 2025 року.
Крім того, до 2025 року кіберзлочини будуть коштувати глобальним компаніям і організаціям приблизно 10,3 трильйона доларів США щорічно.
Ось чому сьогодні потреба в методах виявлення аномалій стає все більш поширеною та необхідною для виявлення шахрайства та запобігання мережевим вторгненням.
Ця стаття допоможе вам зрозуміти, що таке аномалії в інтелектуальному аналізі даних, різні типи аномалій і способи запобігання мережевим вторгненням за допомогою методів виявлення аномалій на основі ML.
Далі ви можете дослідити все про матрицю плутанини в машинному навчанні.