
Вилучення даних – це процес збору певних даних із веб-сторінок. Користувачі можуть отримувати текст, зображення, відео, огляди, продукти тощо. Ви можете видобувати дані для дослідження ринку, аналізу настроїв, аналізу конкуренції та сукупних даних.
Якщо ви маєте справу з невеликою кількістю даних, ви можете витягти дані вручну, скопіювавши певну інформацію з веб-сторінок у електронну таблицю чи формат документа на свій смак. Наприклад, якщо ви як клієнт шукаєте відгуки в Інтернеті, щоб допомогти вам прийняти рішення про покупку, ви можете видалити дані вручну.
З іншого боку, якщо ви маєте справу з великими наборами даних, вам потрібна автоматизована техніка вилучення даних. Ви можете створити власне рішення для вилучення даних або використовувати для таких завдань Proxy API або Scraping API.
Однак ці методи можуть бути менш ефективними, оскільки деякі сайти, на які ви націлюєте, можуть бути захищені системою капчі. Можливо, вам також доведеться керувати ботами та проксі. Такі завдання можуть зайняти багато часу та обмежити характер вмісту, який ви можете отримати.
Браузер для сканування: рішення
Ви можете подолати всі ці проблеми за допомогою Scraping Browser від Bright Data. Цей універсальний браузер допомагає збирати дані з веб-сайтів, які важко вилучити. Це браузер, який використовує графічний інтерфейс користувача (GUI) і керується Puppeteer або Playwright API, що робить його непомітним для ботів.
Браузер Scraping має вбудовані функції розблокування, які автоматично обробляють усі блоки від вашого імені. Браузер відкривається на серверах Bright Data, що означає, що вам не потрібна дорога власна інфраструктура для видалення даних для ваших масштабних проектів.
Особливості Bright Data Scraping Browser
- Автоматичне розблокування веб-сайту: вам не потрібно постійно оновлювати веб-переглядач, оскільки цей веб-переглядач автоматично налаштовується на перевірку CAPTCHA, нові блоки, відбитки пальців і повторні спроби. Scraping Browser імітує реального користувача.
- Велика мережа проксі-серверів: ви можете націлюватися на будь-яку країну, оскільки Scraping Browser має понад 72 мільйони IP-адрес. Ви можете орієнтуватися на міста чи навіть операторів і скористатися перевагами найкращих у своєму класі технологій.
- Масштабований: ви можете відкривати тисячі сеансів одночасно, оскільки цей браузер використовує інфраструктуру Bright Data для обробки всіх запитів.
- Сумісний із Puppeteer і Playwright: цей браузер дозволяє здійснювати виклики API та отримувати будь-яку кількість сеансів браузера за допомогою Puppeteer (Python) або Playwright (Node.js).
- Економія часу та ресурсів: замість того, щоб налаштовувати проксі-сервери, Scraping Browser піклується про все у фоновому режимі. Вам також не потрібно налаштовувати внутрішню інфраструктуру, оскільки цей інструмент піклується про все у фоновому режимі.
Як налаштувати Scraping Browser
- Перейдіть на веб-сайт Bright Data і натисніть на Scraping Browser на вкладці «Scraping Solutions».
- Створити аккаунт. Ви побачите два варіанти; «Почати безкоштовну пробну версію» та «Почати безкоштовно з Google». Давайте наразі виберемо «Почати безкоштовну пробну версію» та перейдемо до наступного кроку. Ви можете створити обліковий запис вручну або скористатися обліковим записом Google.
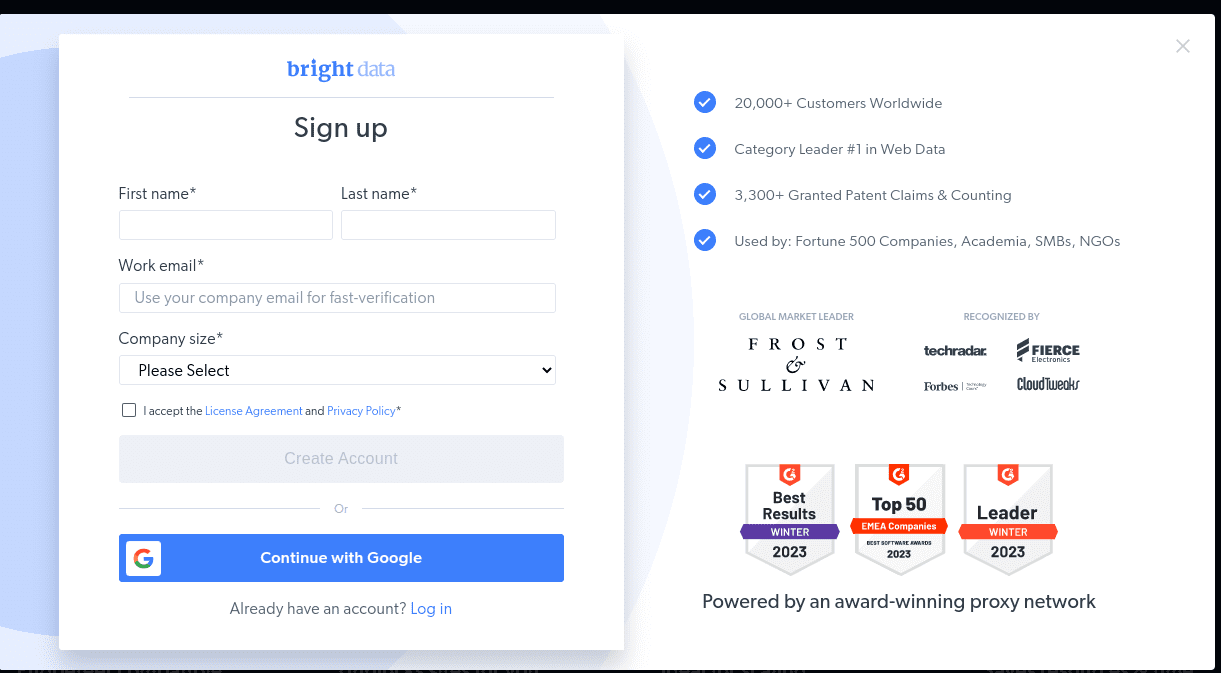
- Коли ваш обліковий запис буде створено, на інформаційній панелі буде представлено кілька параметрів. Виберіть «Проксі та інфраструктура копіювання».
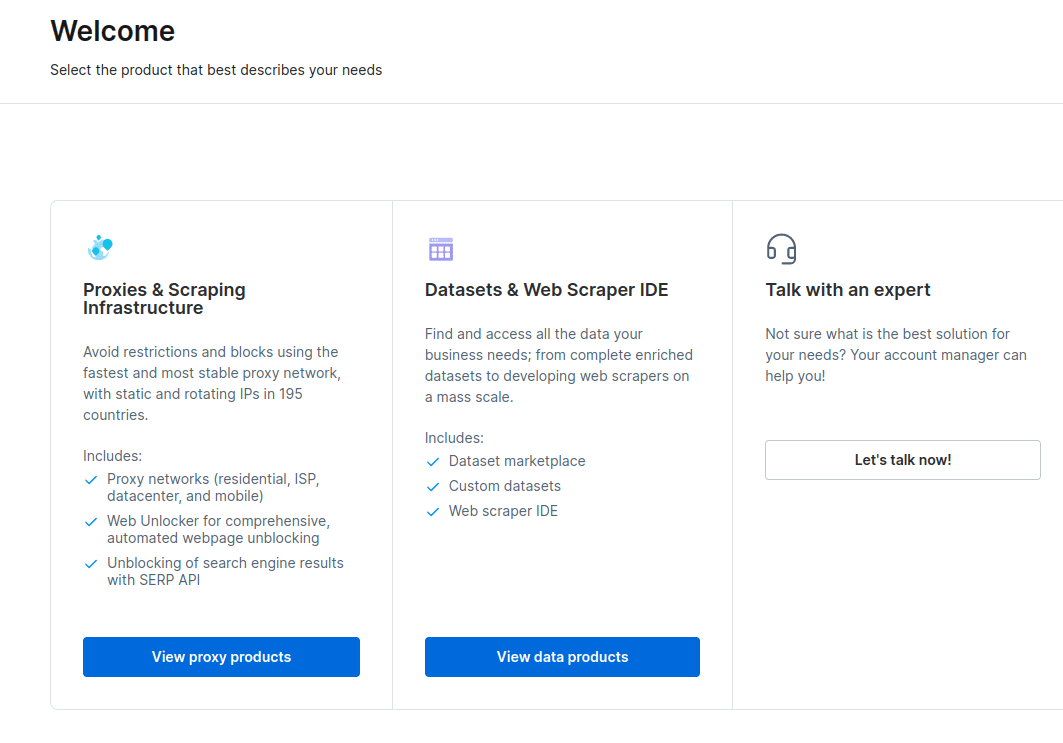
- У новому вікні, що відкриється, виберіть Scraping Browser і натисніть «Почати».
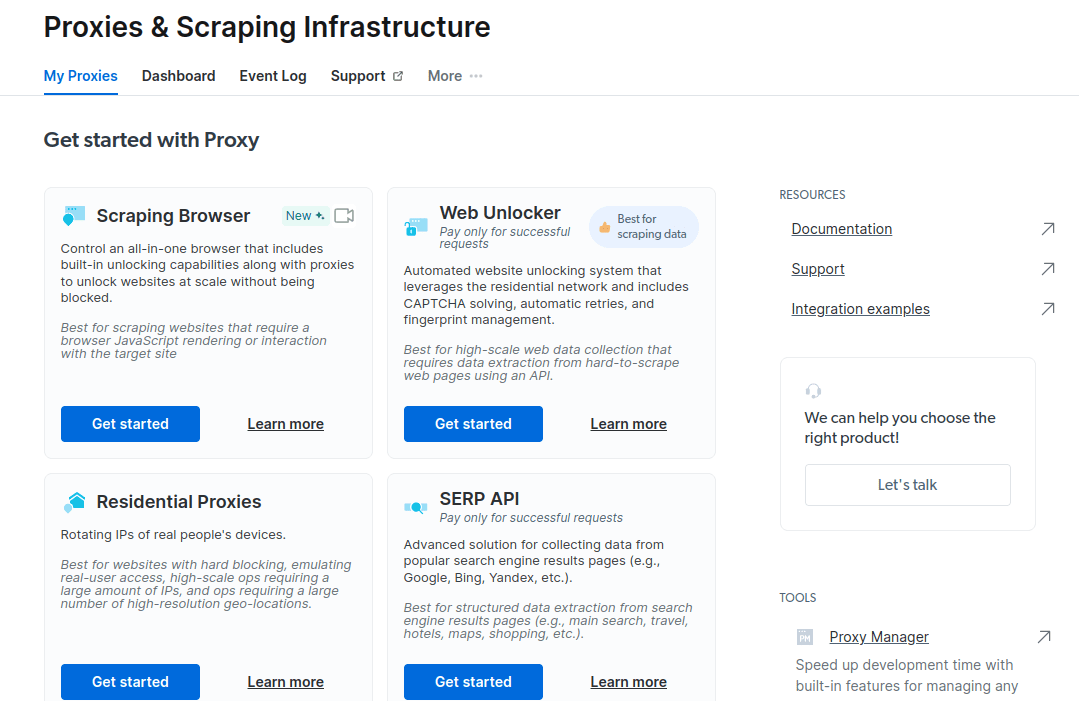
- Збережіть і активуйте свої конфігурації.
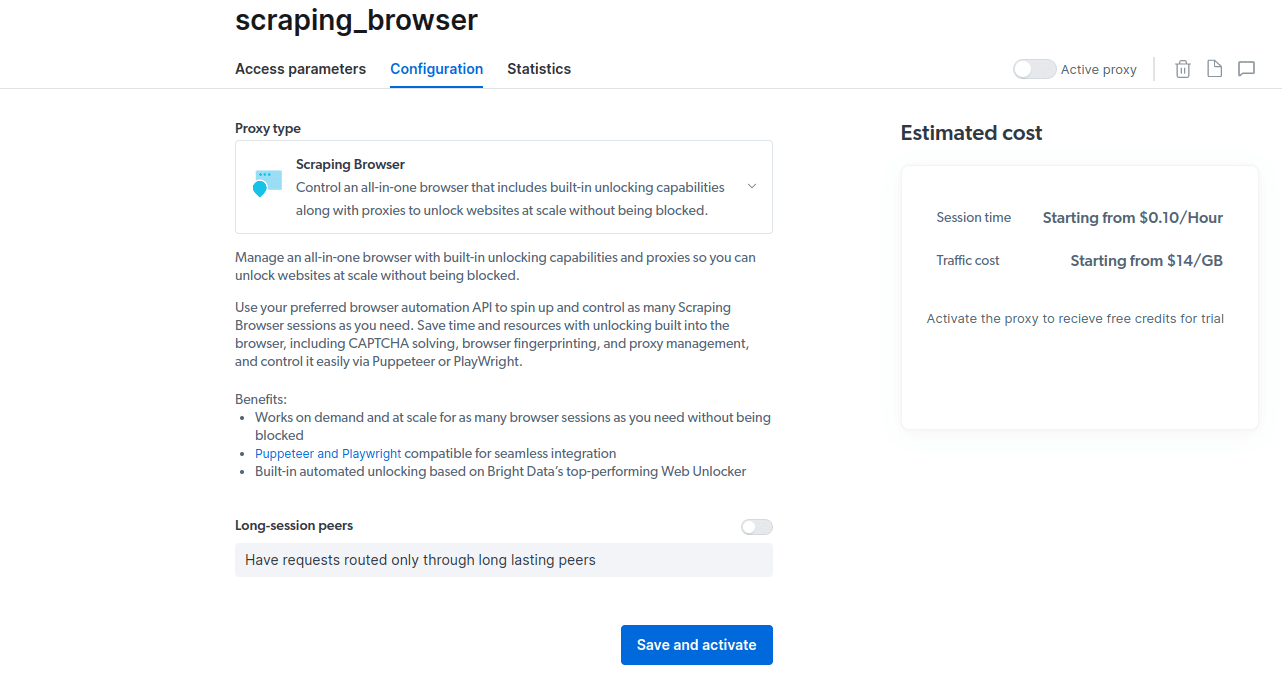
- Активуйте безкоштовну пробну версію. Перший варіант дає вам кредит у розмірі 5 доларів США, який ви можете використати для використання проксі. Натисніть на першу опцію, щоб спробувати цей продукт. Однак, якщо ви активний користувач, ви можете вибрати другий варіант, який надає вам 50 доларів США безкоштовно, якщо ви завантажите свій обліковий запис на 50 доларів США або більше.
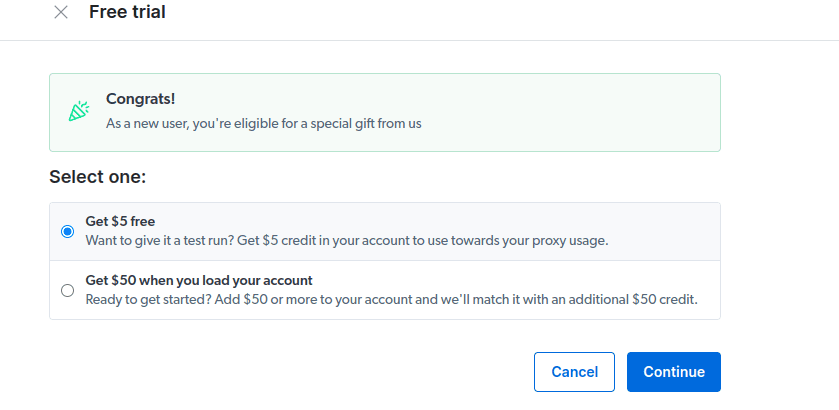
- Введіть свою платіжну інформацію. Не хвилюйтеся, оскільки платформа нічого не стягуватиме. Платіжна інформація лише підтверджує, що ви новий користувач і не шукаєте безкоштовних подарунків, створюючи кілька облікових записів.
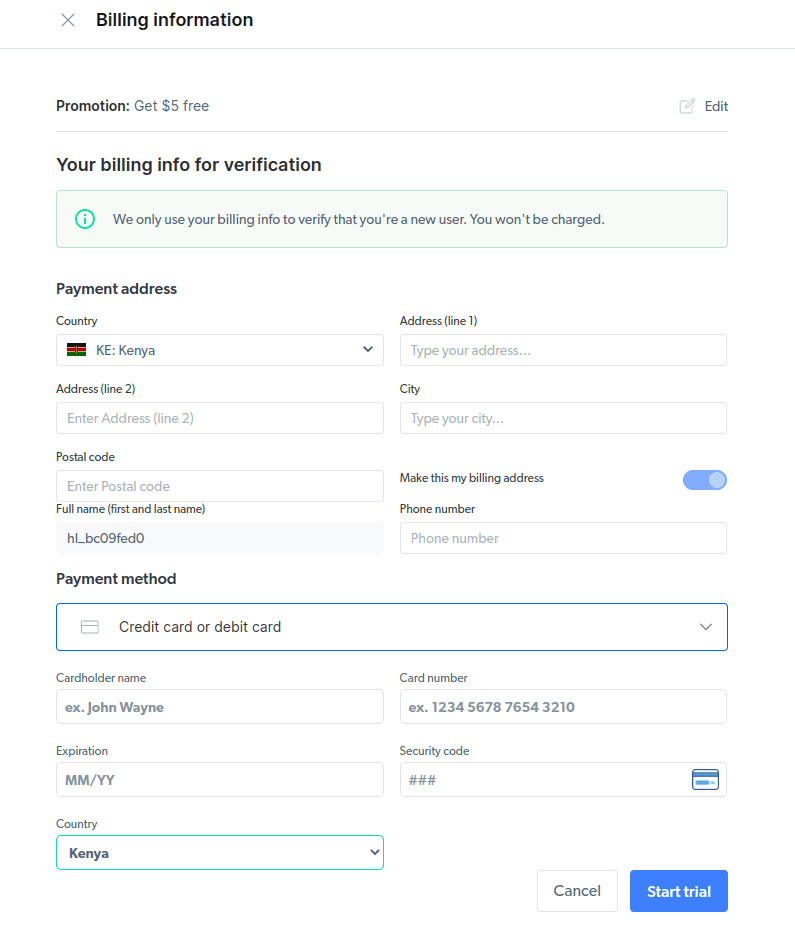
- Створіть новий проксі. Після збереження платіжних даних ви можете створити новий проксі-сервер. Клацніть піктограму «додати» та виберіть «Проксі-сервер» як «Тип проксі». Натисніть «Додати проксі» та перейдіть до наступного кроку.
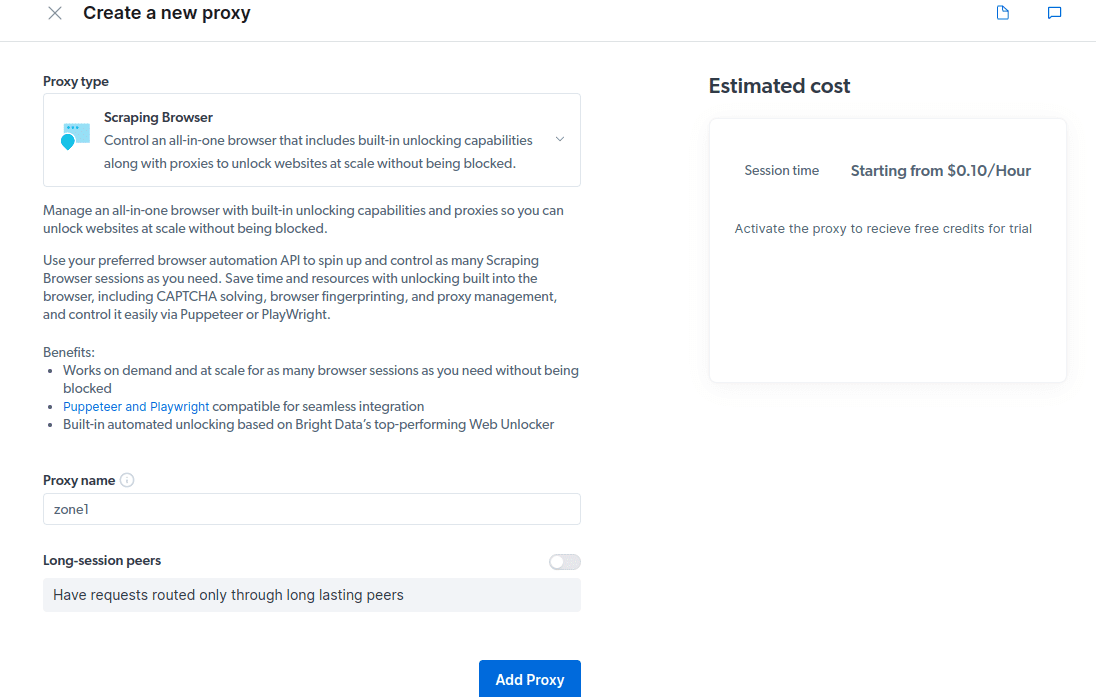
- Створіть нову «зону». З’явиться спливаюче вікно із запитом, чи хочете ви створити нову зону; натисніть «Так» і продовжуйте.
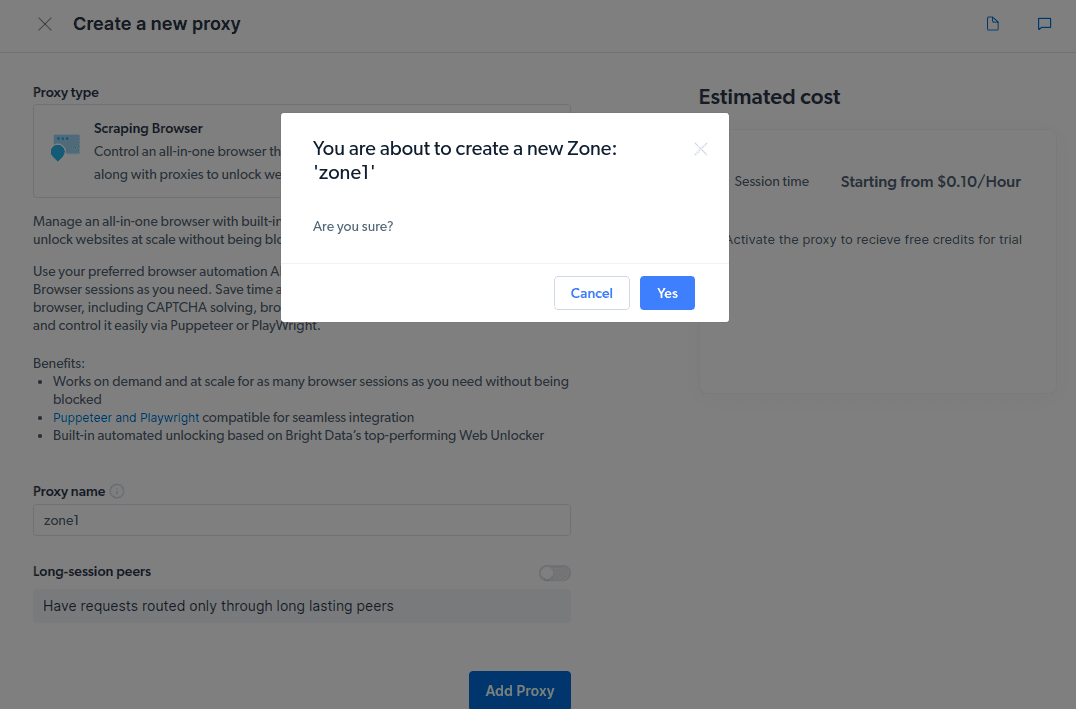
- Натисніть «Перевірити код і приклади інтеграції». Тепер ви отримаєте приклади інтеграції проксі-сервера, які можна використовувати для видалення даних із цільового веб-сайту. Ви можете використовувати Node.js або Python для отримання даних із цільового веб-сайту.
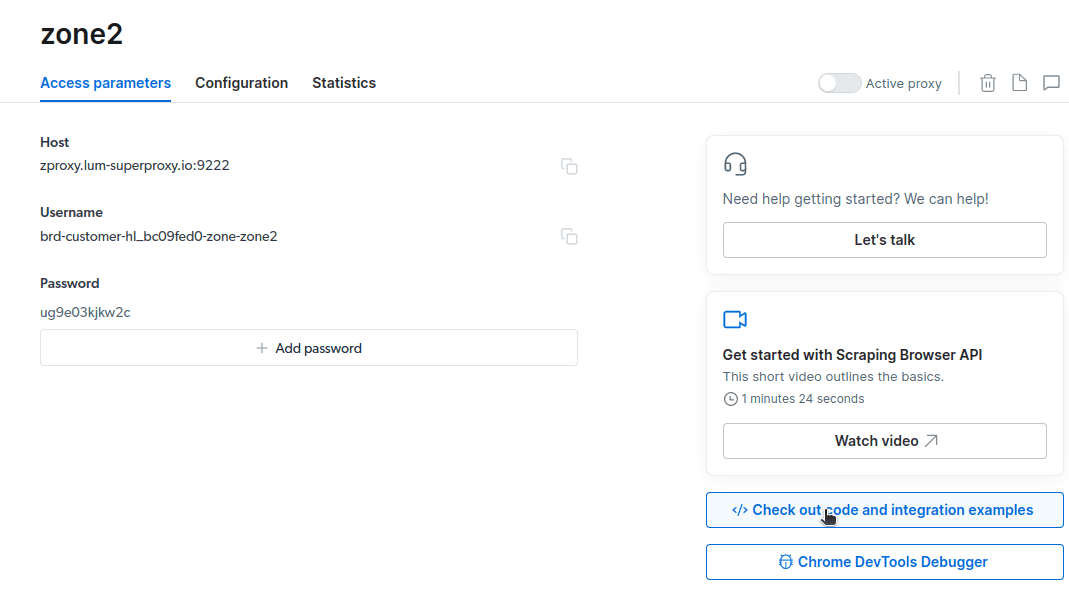
Тепер у вас є все необхідне для отримання даних із веб-сайту. Ми використаємо наш веб-сайт, techukraine.net.com, щоб продемонструвати, як працює Scraping Browser. Для цієї демонстрації ми будемо використовувати node.js. Ви можете слідувати, якщо у вас встановлено node.js.
Виконайте такі дії;
const puppeteer = require('puppeteer-core');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="USERNAME:PASSWORD";
async function run(){
let browser;
try {
browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2*60*1000);
await page.goto('https://example.com');
const html = await page.evaluate(() => document.documentElement.outerHTML);
console.log(html);
}
catch(e) {
console.error('run failed', e);
}
finally {
await browser?.close();
}
}
if (require.main==module)
run();
Я зміню свій код у рядку 10 таким чином:
await page.goto(‘https://techukraine.net.com/authors/‘);
Мій остаточний код тепер буде;
const puppeteer = require('puppeteer-core');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="brd-customer-hl_bc09fed0-zone-zone2:ug9e03kjkw2c";
async function run(){
let browser;
try {
browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2*60*1000);
await page.goto('https://techukraine.net.com/authors/');
const html = await page.evaluate(() => document.documentElement.outerHTML);
console.log(html);
}
catch(e) {
console.error('run failed', e);
}
finally {
await browser?.close();
}
}
if (require.main==module)
run();
node script.js
Щось подібне буде у вас на терміналі
Як експортувати дані
Ви можете використовувати кілька підходів для експорту даних, залежно від того, як ви збираєтеся їх використовувати. Сьогодні ми можемо експортувати дані у файл html, змінивши сценарій на створення нового файлу з назвою data.html замість того, щоб друкувати його на консолі.
Ви можете змінити вміст свого коду наступним чином;
const puppeteer = require('puppeteer-core');
const fs = require('fs');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="brd-customer-hl_bc09fed0-zone-zone2:ug9e03kjkw2c";
async function run() {
let browser;
try {
browser = await puppeteer.connect({ browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222` });
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2 * 60 * 1000);
await page.goto('https://techukraine.net.com/authors/');
const html = await page.evaluate(() => document.documentElement.outerHTML);
// Write HTML content to a file
fs.writeFileSync('data.html', html);
console.log('Data export complete.');
} catch (e) {
console.error('run failed', e);
} finally {
await browser?.close();
}
}
if (require.main == module) {
run();
}
Тепер ви можете запустити код за допомогою цієї команди;
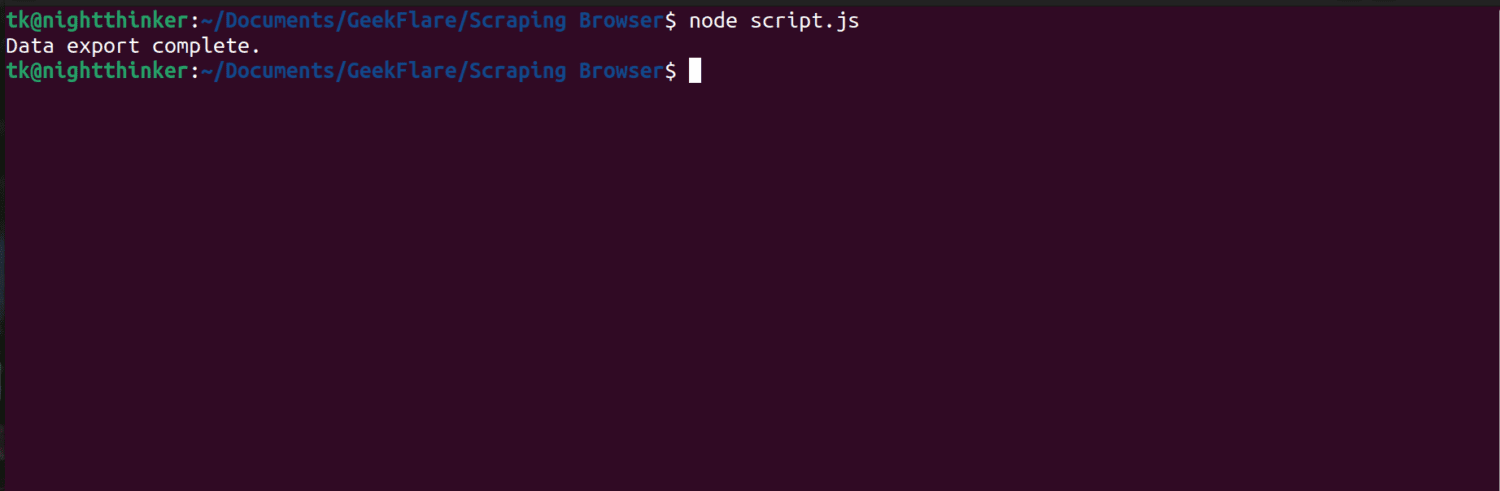
node script.js
Як ви можете бачити на наступному знімку екрана, термінал відображає повідомлення «експорт даних завершено».
Якщо ми перевіримо папку нашого проекту, ми побачимо файл під назвою data.html із тисячами рядків коду.
Я тільки пошкрябав поверхню того, як видобувати дані за допомогою браузера Scraping. За допомогою цього інструменту я можу навіть звузити список і видалити лише імена авторів та їхні описи.
Якщо ви хочете використовувати Scraping Browser, визначте набори даних, які потрібно витягти, і відповідно змініть код. Ви можете видобувати текст, зображення, відео, метадані та посилання залежно від веб-сайту, на який ви націлюєте, і структури файлу HTML.
поширені запитання
Чи законні вилучення даних і веб-збирання?
Збирання веб-сторінок є суперечливою темою: одні вважають, що це аморально, а інші вважають, що це нормально. Законність копіювання веб-сайтів залежатиме від природи вмісту, що збирається, і політики цільової веб-сторінки.
Як правило, копіювання персональних даних, таких як адреси та фінансові дані, вважається незаконним. Перш ніж брати дані, перевірте, чи сайт, на який ви націлюєте, має якісь вказівки. Завжди переконайтеся, що ви не видаляєте ті дані, які не є загальнодоступними.
Чи є Scraping Browser безкоштовним інструментом?
Ні. Scraping Browser є платною послугою. Якщо ви підпишетеся на безкоштовну пробну версію, інструмент надасть вам кредит у розмірі 5 доларів США. Платні пакети починаються від $15/ГБ + $0,1/год. Ви також можете вибрати опцію Pay As You Go, яка починається від 20 $/ГБ + 0,1 $/год.
Яка різниця між браузерами Scraping і безголовими браузерами?
Scraping Browser — це потужний браузер, тобто він має графічний інтерфейс користувача (GUI). З іншого боку, безголові браузери не мають графічного інтерфейсу. Безголові браузери, такі як Selenium, використовуються для автоматизації веб-збирання, але іноді вони обмежені, оскільки їм доводиться мати справу з CAPTCHA та виявленням ботів.
Підведенню
Як бачите, Scraping Browser спрощує вилучення даних із веб-сторінок. Браузер Scraping простий у використанні порівняно з такими інструментами, як Selenium. Навіть нерозробники можуть використовувати цей браузер із чудовим інтерфейсом користувача та гарною документацією. Інструмент має можливості розблокування, недоступні в інших інструментах утилізації, що робить його ефективним для всіх, хто хоче автоматизувати такі процеси.
Ви також можете дізнатися, як заборонити плагінам ChatGPT копіювати вміст вашого веб-сайту.