У цій статті ми розглянемо та детально опишемо декілька з найефективніших бібліотек Python, які є незамінними для фахівців з обробки даних та команд, що займаються машинним навчанням.
Python здобув широке визнання як оптимальна мова програмування в цих двох областях, зокрема завдяки багатому набору бібліотек, які він пропонує.
Ця популярність зумовлена наявністю спеціалізованих бібліотек Python, що забезпечують широкий спектр функцій, таких як обробка введення/виведення даних, аналіз даних та інші операції з обробки інформації, які є важливими для науковців та експертів у галузі машинного навчання під час роботи з даними.
Що таке бібліотеки Python?
Бібліотека Python – це комплексна збірка вже готових модулів, що включають скомпільований код, зокрема класи та методи. Це дозволяє розробникам використовувати існуючий функціонал, уникнувши необхідності писати код з нуля.
Значення Python для науки про дані та машинного навчання
Python пропонує передові бібліотеки, що є дуже цінними для фахівців з машинного навчання та Data Science.
Його лаконічний синтаксис спрощує реалізацію складних алгоритмів машинного навчання. Крім того, легкість у використанні зменшує час навчання та спрощує розуміння.
Python підтримує швидку розробку прототипів і ефективне тестування програмних рішень.
Активна спільнота Python є великою перевагою для фахівців з обробки даних, оскільки дозволяє їм оперативно знаходити відповіді на свої запитання.
Наскільки корисні бібліотеки Python?
Бібліотеки Python є потужним інструментом для розробки програм та моделей у галузі машинного навчання та науки про дані.
Ці бібліотеки значно спрощують роботу розробників, дозволяючи їм повторно використовувати наявний код. Замість розробки власного коду, ви можете імпортувати потрібну бібліотеку, що вже реалізує необхідні функції.
Огляд бібліотек Python, що застосовуються в машинному навчанні та науці про дані
Експерти Data Science рекомендують певний набір бібліотек Python, з якими повинен бути знайомий кожен, хто цікавиться цією областю. Залежно від їхнього призначення, спеціалісти з машинного навчання та науки про дані використовують різні бібліотеки Python, які можна поділити на категорії: бібліотеки для розгортання моделей, видобутку та аналізу даних, обробки даних та візуалізації.
В цій статті ми розглянемо деякі з бібліотек Python, які найчастіше застосовуються в науці про дані та машинному навчанні.
Тож, давайте розглянемо їх докладніше.
Numpy
Бібліотека Numpy, розроблена на основі високоефективного коду C, є основним інструментом для фахівців з обробки даних, завдяки її потужним можливостям у виконанні математичних та наукових обчислень.
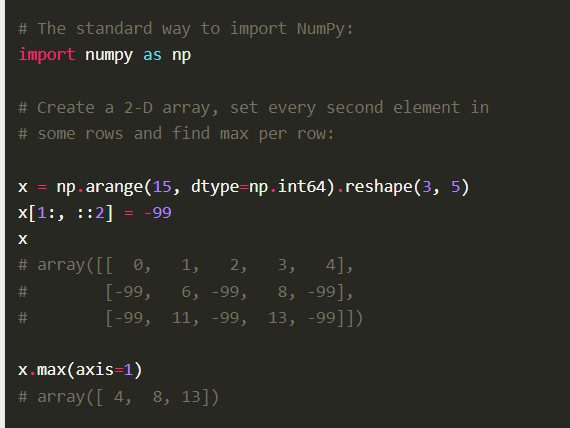
Ключові особливості:
- Numpy пропонує високорівневий синтаксис, що робить його доступним для програмістів з різним досвідом.
- Завдяки оптимізованому коду C, бібліотека забезпечує високу продуктивність обчислень.
- Включає в себе інструменти для числових обчислень, зокрема перетворення Фур’є, лінійну алгебру та генератори випадкових чисел.
- Має відкритий вихідний код, що дозволяє іншим розробникам робити свій внесок у її розвиток.
Numpy також надає розширені функції, такі як векторизація математичних операцій, індексація та підтримка масивів і матриць.
Pandas
Pandas є популярною бібліотекою для машинного навчання, що надає високорівневі структури даних та інструменти для ефективного аналізу великих наборів даних. Завдяки лаконічному набору команд, ця бібліотека дозволяє виконувати складні операції з даними.
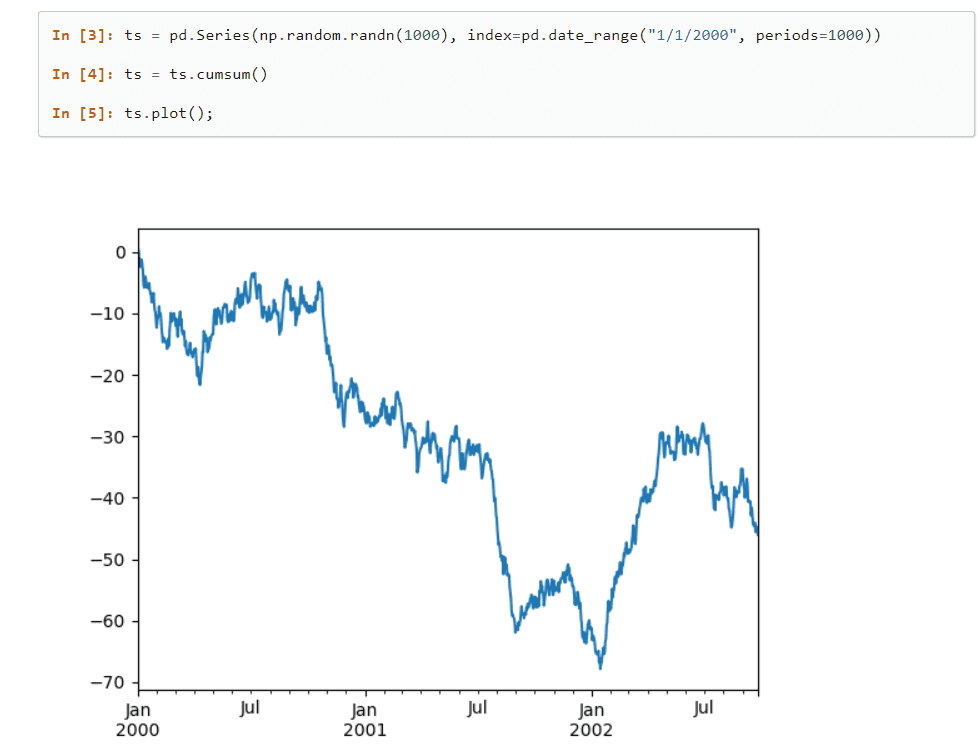
Бібліотека Pandas включає в себе численні вбудовані методи для групування, індексування, вилучення, розділення, реструктуризації та фільтрації даних перед їхнім поданням у одновимірні та багатовимірні таблиці.
Основні переваги бібліотеки Pandas:
- Pandas спрощує роботу з табличними даними, автоматично вирівнюючи та індексуючи їх.
- Підтримує швидке завантаження та збереження даних у різних форматах, таких як JSON та CSV.
Pandas відрізняється високою ефективністю аналізу даних та великою гнучкістю.
Matplotlib
Matplotlib – це бібліотека Python для створення двовимірної графіки, яка дозволяє працювати з даними з різних джерел. Створені візуалізації є статичними, анімованими та інтерактивними, що забезпечує ефективний аналіз та створення діаграм. Також користувач може налаштовувати зовнішній вигляд графіків.
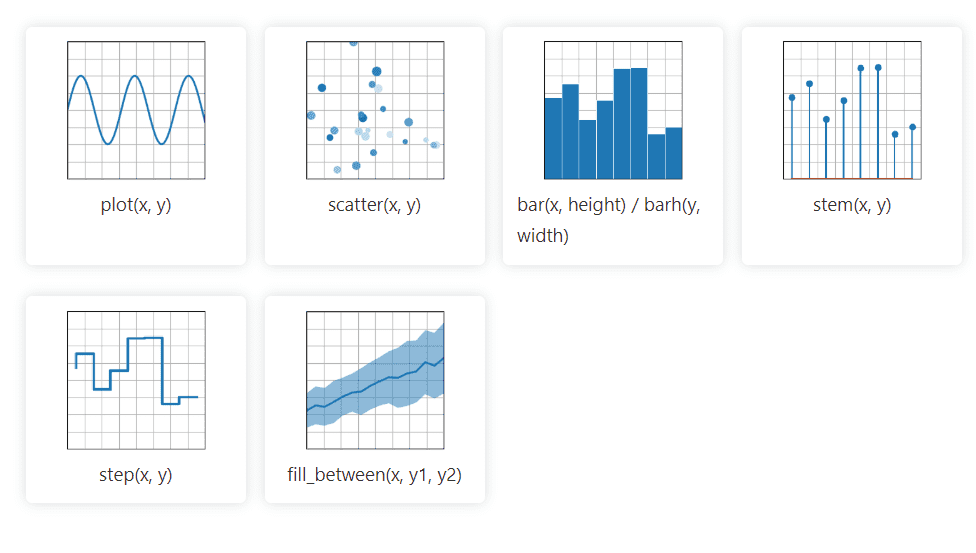
Документація Matplotlib є у відкритому доступі і пропонує великий набір інструментів для її впровадження.
Matplotlib також імпортує допоміжні класи для роботи з часовими рядами даних, такі як рік, місяць, день та тиждень.
Scikit-Learn
Scikit-learn є оптимальною бібліотекою для роботи зі складними даними та широко використовується фахівцями з машинного навчання. Вона взаємодіє з іншими бібліотеками, такими як NumPy, SciPy та Matplotlib. Бібліотека пропонує алгоритми керованого та некерованого навчання для використання у виробничих програмах.

Основні можливості бібліотеки Scikit-learn Python:
- Ідентифікація категорій об’єктів за допомогою таких алгоритмів, як SVM та випадковий ліс, у таких програмах, як розпізнавання зображень.
- Прогнозування безперервних значень атрибутів за допомогою регресії.
- Вилучення ознак.
- Зменшення розмірності даних.
- Об’єднання схожих об’єктів у групи.
Scikit-learn ефективна для вилучення ознак із текстових і графічних даних. Також можна перевірити точність моделей на нових, раніше невідомих даних. Великий набір алгоритмів дозволяє проводити аналіз даних та інші завдання машинного навчання.
SciPy
SciPy (науковий код Python) – це бібліотека для машинного навчання, що включає в себе модулі для математичних функцій та алгоритмів. Її алгоритми вирішують алгебраїчні рівняння, виконують інтерполяцію, оптимізацію, статистичний аналіз та інтегрування.
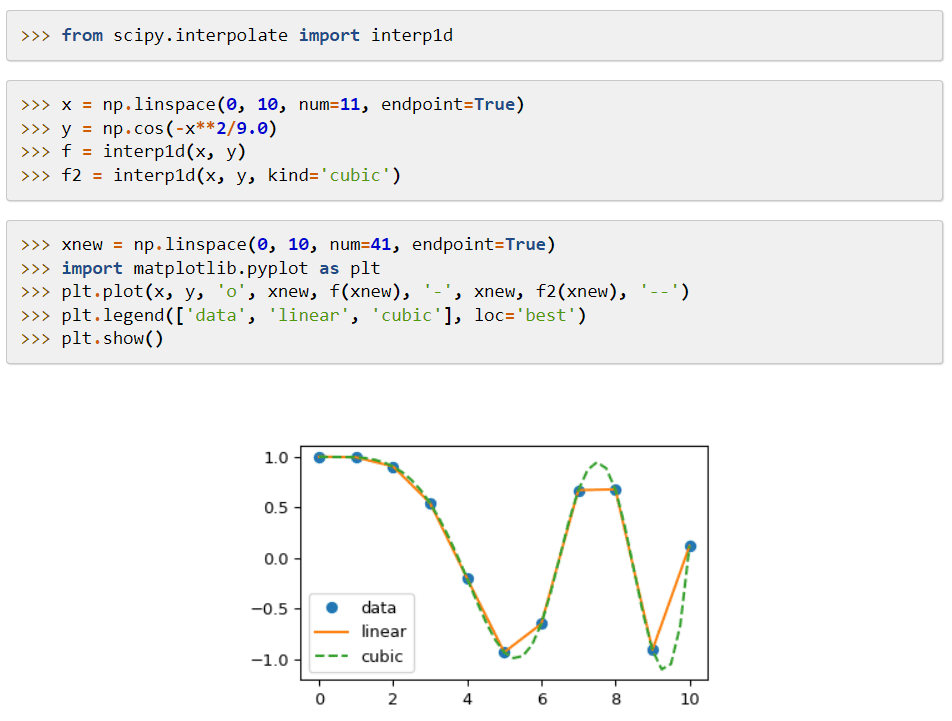
Основною перевагою є її розширення для NumPy, що додає інструменти для вирішення математичних завдань, а також структури даних, такі як розріджені матриці.
SciPy використовує команди та класи високого рівня для маніпулювання та візуалізації даних. Системи обробки даних та прототипи роблять її ще більш ефективним інструментом.
Крім того, високорівневий синтаксис SciPy є зручним для програмістів з будь-яким рівнем досвіду.
Єдиний недолік SciPy – це її вузька спеціалізація на числових об’єктах та алгоритмах, що не дозволяє використовувати її для графічного відображення даних.
PyTorch
PyTorch – це багатофункціональна бібліотека для машинного навчання, яка забезпечує ефективну реалізацію тензорних обчислень з прискоренням GPU, а також створення динамічних обчислювальних графів та автоматичне обчислення градієнтів. Вона створена на основі бібліотеки Torch, розробленої на C.

Ключові особливості:
- Забезпечує плавну розробку та масштабування завдяки хорошій підтримці основних хмарних платформ.
- Надійна екосистема інструментів та бібліотек підтримує розвиток комп’ютерного зору та інших сфер, таких як обробка природної мови (NLP).
- Забезпечує гнучкий перехід між режимами Eager та graph за допомогою Torch Script, у той час як TorchServe використовується для прискорення шляху до виробництва.
- Розподілений бекенд Torch забезпечує паралельне навчання та оптимізацію продуктивності в дослідженнях і виробництві.
PyTorch можна використовувати для розробки програм NLP.
Keras
Keras – це бібліотека Python для машинного навчання з відкритим кодом, яка використовується для експериментів з глибокими нейронними мережами.
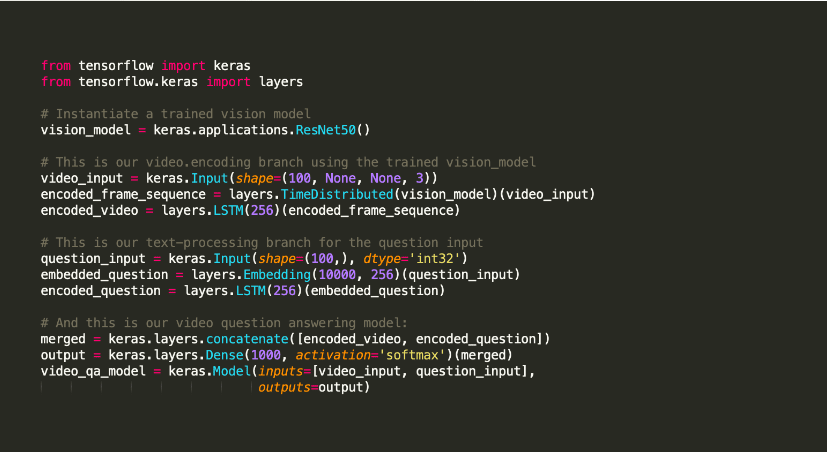
Вона відома своїми інструментами, що підтримують різні завдання, такі як компіляція моделі та візуалізація графіків. Keras використовує Tensorflow для своєї серверної частини, а також Theano або нейронні мережі, такі як CNTK. Ця інфраструктура допомагає Keras створювати обчислювальні графи для реалізації операцій.
Основні характеристики бібліотеки:
- Ефективна робота як на центральному процесорі, так і на графічному процесорі.
- Завдяки Python, налагодження Keras є простішим.
- Keras має модульну структуру, що робить її гнучкою та адаптованою.
- Можливість розгортання Keras у будь-якому середовищі, експортуючи її модулі в JavaScript для запуску в браузері.
Програми Keras включають такі будівельні блоки нейронної мережі, як шари та цілі, а також інші інструменти, що спрощують роботу з зображеннями та текстовими даними.
Seaborn
Seaborn є ще одним корисним інструментом для візуалізації статистичних даних.
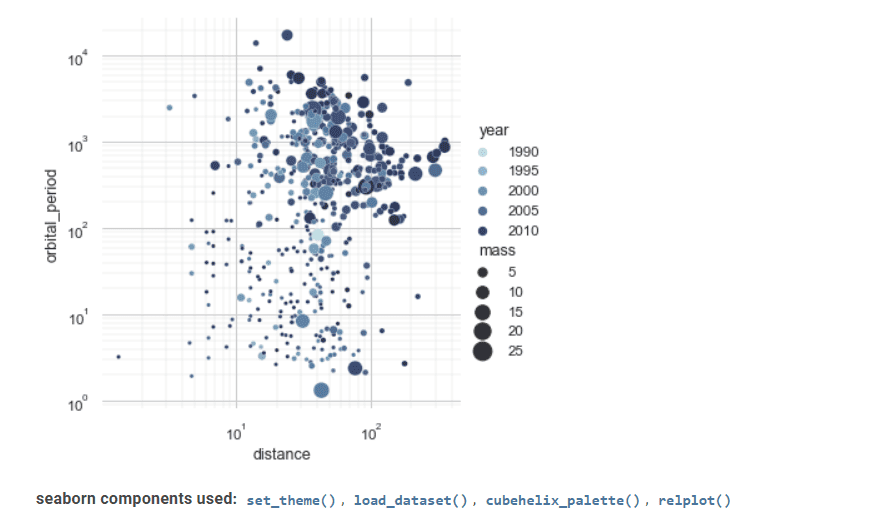
Її розширений інтерфейс дозволяє створювати привабливі та інформативні статистичні графіки.
Plotly
Plotly — це тривимірний веб-інструмент візуалізації, що використовує бібліотеку Plotly JS. Він пропонує підтримку різних типів діаграм, таких як лінійні графіки, точкові діаграми та спарклайни.
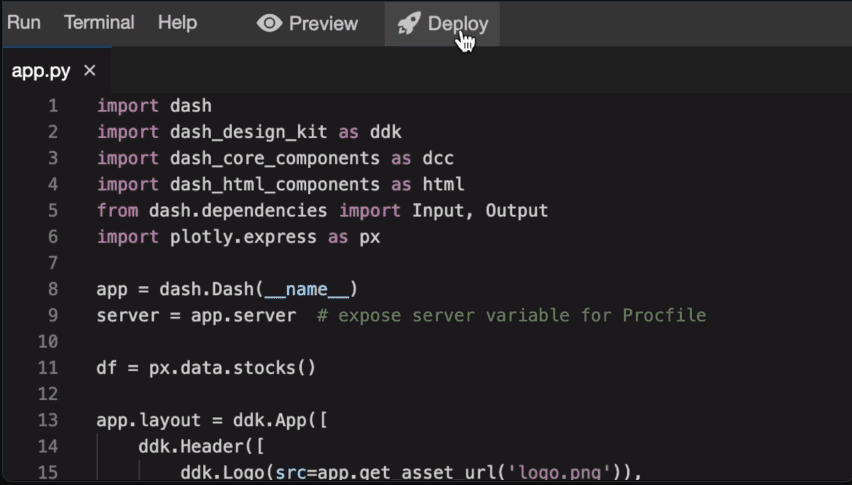
Plotly використовується для створення веб-візуалізацій даних в Jupyter notebook.
Plotly зручний для візуалізації, оскільки він дозволяє виявляти викиди чи аномалії на графіку за допомогою інструменту наведення курсора. Також є можливість налаштування графіків відповідно до потреб.
Недоліками Plotly є застаріла документація, що ускладнює її використання, а також велика кількість інструментів, які можуть бути складними для вивчення.
Особливості бібліотеки Plotly Python:
- Тривимірні діаграми з багатьма точками взаємодії.
- Простий синтаксис.
- Можливість збереження конфіденційності коду під час обміну результатами.
SimpleITK
SimpleITK — це бібліотека для аналізу зображень, яка надає інтерфейс до Insight Toolkit (ITK). Вона розроблена на C++ та має відкритий вихідний код.
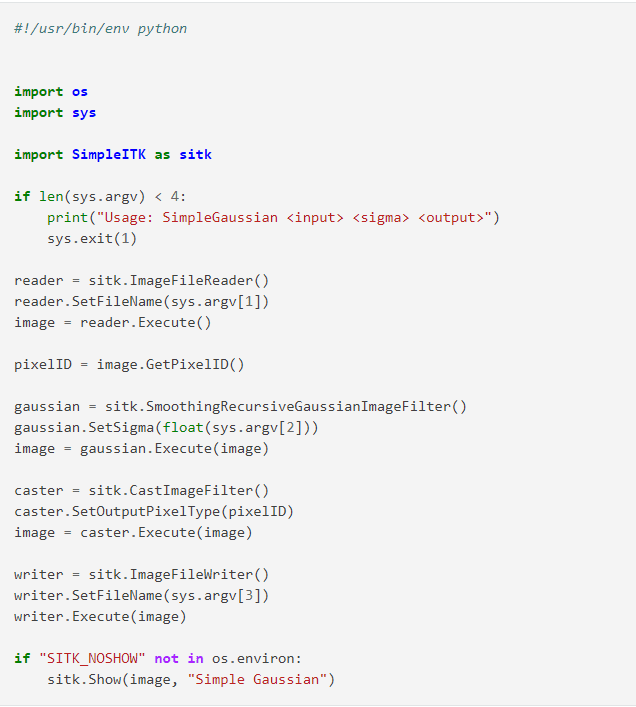
Особливості бібліотеки SimpleITK:
- Підтримка введення/виведення файлів зображень у 20 різних форматах, таких як JPG, PNG та DICOM.
- Наявність фільтрів для сегментації зображень, таких як фільтри Otsu, набори рівнів та вододіли.
- Інтерпретація зображень як просторових об’єктів, а не масиву пікселів.
SimpleITK має простий інтерфейс, що доступний на різних мовах програмування, таких як R, C#, C++, Java та Python.
Statsmodel
Statsmodel застосовується для оцінки статистичних моделей, реалізації статистичних тестів та дослідження статистичних даних за допомогою класів та функцій.
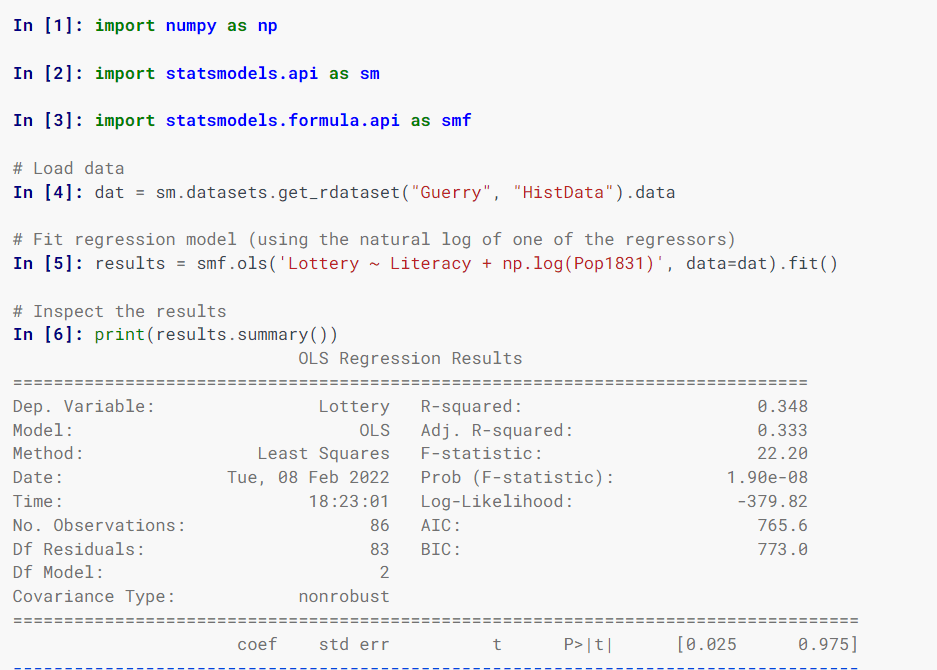
Для визначення моделей використовуються формули в стилі R, масиви NumPy та кадри даних Pandas.
Scrapy
Scrapy — це пакет з відкритим вихідним кодом, що є ефективним інструментом для отримання та сканування даних з веб-сайтів. Він асинхронний, що забезпечує його швидкість. Scrapy має добре продуману архітектуру та широкий набір функцій.
Встановлення Scrapy відрізняється залежно від операційної системи. Scrapy не працює з веб-сайтами, створеними на JS, і підтримує лише Python 2.7 або новіші версії.
Фахівці Data Science використовують Scrapy для аналізу даних та автоматизованого тестування.
Особливості Scrapy:
- Експорт даних у форматах JSON, CSV та XML з можливістю збереження на декількох серверах.
- Вбудовані функції для збору та вилучення даних із джерел HTML/XML.
- Наявність чітко визначеного API для розширення функціональності Scrapy.
Pillow
Pillow – це бібліотека Python для обробки зображень.
Вона додає до інтерпретатора Python функціонал для обробки зображень, підтримує різні формати файлів та пропонує якісні внутрішні представлення.
За допомогою Pillow можна легко отримати доступ до даних, що зберігаються у різних форматах файлів.
Висновок
На цьому завершується наш огляд найефективніших бібліотек Python для фахівців з обробки даних та експертів у галузі машинного навчання.
Як показано в цій статті, Python має потужний набір інструментів для машинного навчання та аналізу даних. Також існують інші бібліотеки Python, які можуть бути застосовані у різних сферах.
Можливо, вас зацікавить ознайомлення з кращими блокнотами для обробки даних.
Бажаємо успіхів у навчанні!