

Чи готові ви вивчати розробку функцій для машинного навчання та науки про дані? Ви в правильному місці!
Розробка функцій є критично важливою навичкою для отримання цінної інформації з даних, і в цьому короткому посібнику я розіб’ю її на прості, доступні фрагменти. Отже, давайте зануримося в роботу та розпочнемо вашу подорож до опанування вилучення функцій!
Що таке розробка функцій?

Коли ви створюєте модель машинного навчання, пов’язану з бізнесом або експериментальною проблемою, ви надаєте навчальні дані в стовпцях і рядках. У галузі науки про дані та розробки ML стовпці відомі як атрибути або змінні.
Детальні дані або рядки під цими стовпцями називаються спостереженнями або екземплярами. Стовпці або атрибути є функціями в необробленому наборі даних.
Ці необроблені функції недостатні або оптимальні для навчання моделі ML. Щоб зменшити шум зібраних метаданих і максимізувати унікальні сигнали від функцій, вам потрібно трансформувати або конвертувати стовпці метаданих у функціональні функції за допомогою розробки функцій.
Приклад 1: Фінансове моделювання
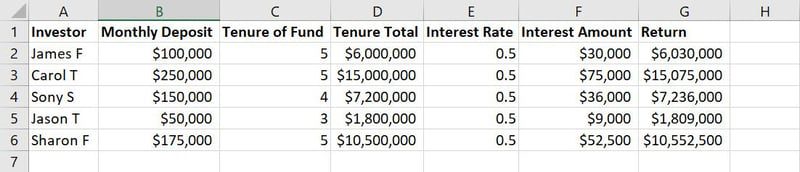 Необроблені дані для навчання моделі ML
Необроблені дані для навчання моделі ML
Наприклад, на наведеному вище зображенні прикладу набору даних стовпці від A до G є об’єктами. Значення або текстові рядки в кожному стовпці вздовж рядків, як-от імена, сума депозиту, роки депозиту, процентні ставки тощо, є спостереженнями.
У моделюванні ML ви повинні видаляти, додавати, комбінувати або перетворювати дані, щоб створити значущі функції та зменшити розмір загальної бази даних навчання моделі. Це розробка функцій.
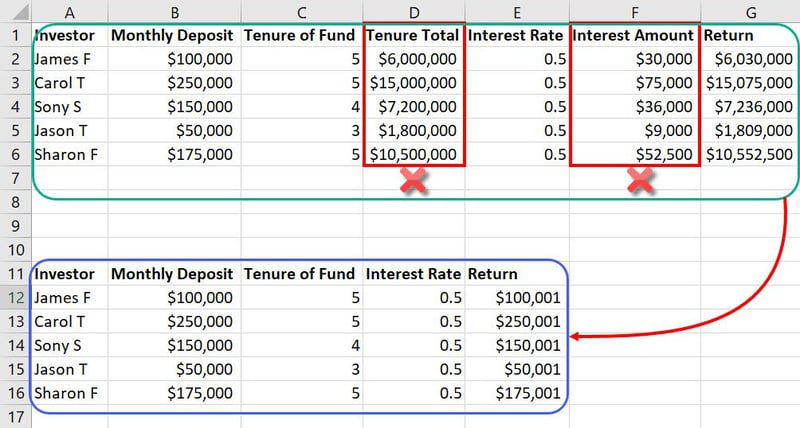 Приклад розробки функцій
Приклад розробки функцій
У тому ж наборі даних, згаданому раніше, такі функції, як Загальна сума володіння та Сума відсотків, є непотрібними вхідними даними. Вони просто займуть більше місця та заплутають модель ML. Отже, ви можете зменшити дві функції із загальної кількості семи.
Оскільки бази даних у моделях ML містять тисячі стовпців і мільйони рядків, зменшення двох функцій сильно впливає на проект.
Приклад 2: AI Music Playlist Maker
Іноді ви можете створити абсолютно нову функцію з кількох існуючих. Припустімо, ви створюєте модель AI, яка автоматично створить список відтворення музики та пісень відповідно до події, смаку, режиму тощо.
Тепер ви зібрали дані про пісні та музику з різних джерел і створили таку базу даних:
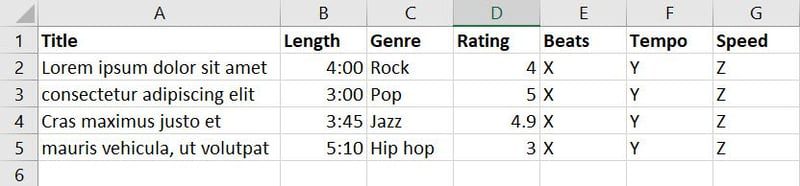
У наведеній вище базі даних є сім функцій. Однак, оскільки ваша мета — навчити модель ML вирішувати, яка пісня чи музика підходить для якої події, ви можете об’єднати такі функції, як «Жанр», «Рейтинг», «Біт», «Темп» і «Швидкість», у нову функцію під назвою «Застосовність».
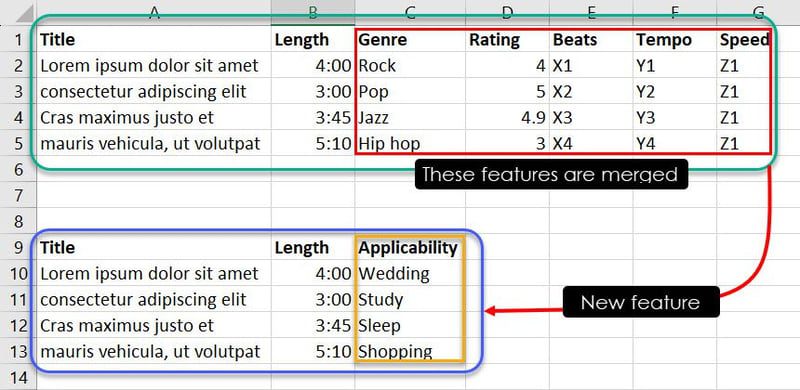
Тепер за допомогою досвіду чи ідентифікації шаблонів ви можете комбінувати певні екземпляри функцій, щоб визначити, яка пісня підходить для якої події. Наприклад, такі спостереження, як Jazz, 4.9, X3, Y3 і Z1, говорять моделі ML, що пісня Cras maximus justo et має бути в списку відтворення користувача, якщо він шукає пісню для сну.
Типи функцій у машинному навчанні
Категориальні ознаки
Це атрибути даних, які представляють різні категорії або мітки. Ви повинні використовувати цей тип для позначення якісних наборів даних.
#1. Порядкові категоріальні ознаки
Порядкові ознаки мають категорії зі змістовним порядком. Наприклад, такі рівні освіти, як середня школа, бакалавр, магістр тощо, мають чітке розмежування в стандартах, але кількісних відмінностей немає.
#2. Номінальні категоріальні ознаки
Номінальні ознаки — це категорії без будь-якого внутрішнього порядку. Прикладами можуть бути кольори, країни або види тварин. Також є лише якісні відмінності.
Особливості масиву
Цей тип ознак представляє дані, організовані в масиви або списки. Науковці даних і розробники ML часто використовують Array Features для обробки послідовностей або вбудовування категоріальних даних.
#1. Функції вбудовування масиву
Вбудовані масиви перетворюють категоричні дані в щільні вектори. Він зазвичай використовується в обробці природної мови та системах рекомендацій.
#2. Функції масиву списку
Масиви списків зберігають послідовності даних, наприклад списки елементів у порядку або історію дій.
Числові особливості
Ці функції навчання ML використовуються для виконання математичних операцій, оскільки ці функції представляють кількісні дані.
#1. Інтервальні числові ознаки
Інтервальні функції мають узгоджені інтервали між значеннями, але не мають справжньої нульової точки — наприклад, дані моніторингу температури. Тут нуль означає температуру замерзання, але атрибут все ще присутній.
#2. Числові характеристики співвідношення
Функції співвідношення мають узгоджені інтервали між значеннями та справжньою нульовою точкою. Приклади включають вік, зріст і дохід.
Важливість інженерії функцій у ML та Data Science
Далі ми розглянемо покроковий процес розробки функцій.
Процес розробки функцій крок за кроком

Далі ми обговоримо методи розробки функцій.
Інженерні методи особливостей
#1. Аналіз основних компонентів (PCA)
PCA спрощує складні дані, знаходячи нові некорельовані функції. Вони називаються головними компонентами. Ви можете використовувати його для зменшення розмірності та покращення продуктивності моделі.
#2. Характеристики поліномів
Створення поліноміальних функцій означає додавання можливостей існуючих функцій для охоплення складних зв’язків у ваших даних. Це допомагає вашій моделі зрозуміти нелінійні моделі.
#3. Обробка викидів
Викиди – це незвичайні точки даних, які можуть вплинути на продуктивність ваших моделей. Щоб запобігти спотворенню результатів, ви повинні визначити викиди та керувати ними.
#4. Перетворення журналу
Логарифмічне перетворення може допомогти нормалізувати дані з перекошеним розподілом. Це зменшує вплив екстремальних значень, щоб зробити дані більш придатними для моделювання.
#5. t-розподілене стохастичне вбудовування сусідів (t-SNE)
t-SNE корисний для візуалізації даних великої розмірності. Це зменшує розмірність і робить кластери більш очевидними, зберігаючи структуру даних.
У цьому методі виділення ознак ви представляєте точки даних у вигляді точок у просторі меншої розмірності. Потім ви розміщуєте подібні точки даних у вихідному високовимірному просторі та моделюєтеся так, щоб вони були близькі одна до одної в нижньому вимірному представленні.
Він відрізняється від інших методів зменшення розмірності збереженням структури та відстані між точками даних.
#6. One-Hot кодування
Одночасне кодування перетворює категоріальні змінні у двійковий формат (0 або 1). Отже, ви отримуєте нові двійкові стовпці для кожної категорії. Одночасне кодування робить категориальні дані придатними для алгоритмів ML.
#7. Кодування підрахунків
Підрахункове кодування замінює категоричні значення кількістю разів, коли вони з’являються в наборі даних. Він може отримувати цінну інформацію з категоріальних змінних.
У цьому методі розробки ознак ви використовуєте частоту або кількість кожної категорії як нову числову функцію замість використання оригінальних міток категорії.
#8. Стандартизація функцій

Характеристики більших значень часто домінують над характеристиками малих значень. Таким чином, модель ML може легко стати упередженою. Стандартизація запобігає таким причинам упереджень у моделі машинного навчання.
Процес стандартизації зазвичай включає наступні дві поширені техніки:
- Стандартизація Z-показника: цей метод перетворює кожну ознаку таким чином, щоб вона мала середнє (середнє) значення 0 і стандартне відхилення 1. Тут ви віднімаєте середнє значення функції з кожної точки даних і ділите результат на стандартне відхилення.
- Мінімально-максимальне масштабування: мінімально-максимальне масштабування перетворює дані в певний діапазон, як правило, від 0 до 1. Ви можете досягти цього, віднявши мінімальне значення функції з кожної точки даних і поділивши його на діапазон.
#9. Нормалізація
За допомогою нормалізації числові функції масштабуються до загального діапазону, зазвичай від 0 до 1. Це зберігає відносні відмінності між значеннями та гарантує, що всі функції знаходяться в однакових умовах.

#1. Функціональні інструменти
Функціональні інструменти це платформа Python з відкритим кодом, яка автоматично створює функції з часових і реляційних наборів даних. Його можна використовувати з інструментами, які ви вже використовуєте для розробки конвеєрів ML.
Рішення використовує Deep Feature Synthesis для автоматизації проектування функцій. Він має бібліотеку низькорівневих функцій для створення функцій. Featuretools також має API, який також ідеально підходить для точної обробки часу.
#2. CatBoost
Якщо ви шукаєте бібліотеку з відкритим вихідним кодом, яка поєднує кілька дерев рішень для створення потужної прогнозної моделі, вибирайте CatBoost. Це рішення пропонує точні результати з параметрами за замовчуванням, тому вам не доведеться витрачати години на точне налаштування параметрів.
CatBoost також дозволяє використовувати нечислові коефіцієнти для покращення результатів тренувань. З ним ви також можете розраховувати на більш точні результати та швидкі прогнози.
#3. Feature-Engine
Feature-Engine це бібліотека Python із кількома трансформаторами та вибраними функціями, які можна використовувати для моделей ML. Перетворювачі, які він включає, можна використовувати для перетворення змінних, створення змінних, функцій дати й часу, попередньої обробки, категоріального кодування, обмеження або видалення викидів і імпутації відсутніх даних. Він здатний автоматично розпізнавати числові, категоріальні змінні та змінні дати й часу.
Інженерні навчальні ресурси
Онлайн-курси та віртуальні заняття

#1. Розробка функцій для машинного навчання на Python: Datacamp
Цей Datacamp курс із розроблення функцій для машинного навчання на Python дає змогу створювати нові функції, які покращують продуктивність моделі машинного навчання. Він навчить вас розробляти функції та обробляти дані для розробки складних програм ML.
#2. Розробка функцій для машинного навчання: Udemy
Від Розробка функцій для курсу машинного навчанняви дізнаєтесь про такі теми, як імпутація, кодування змінних, виділення ознак, дискретизація, функціональність дати й часу, викиди тощо. Учасники також навчаться працювати з перекошеними змінними та мати справу з нечастими, невидимими та рідкісними категоріями.
#3. Розробка функцій: Pluralsight
Це Плюральний погляд Шлях навчання складається з шести курсів. Ці курси допоможуть вам дізнатися про важливість розробки функцій у робочому процесі машинного навчання, способи застосування її методів і вилучення функцій із тексту та зображень.
#4. Вибір функцій для машинного навчання: Udemy
За допомогою цього Udemy на цьому курсі учасники можуть навчитися методам перемішування функцій, фільтрів, обгорток і вбудованих методів, рекурсивного видалення функцій і вичерпного пошуку. У ньому також обговорюються методи вибору функцій, зокрема ті, що використовують Python, Lasso та дерева рішень. Цей курс містить 5,5 годин відео на замовлення та 22 статті.
#5. Розробка функцій для машинного навчання: чудове навчання
Цей курс від Відмінне навчання познайомить вас із розробкою функцій, а також навчить вас про надмірну та недостатню вибірку. Крім того, це дозволить вам виконувати практичні вправи з налаштування моделі.
#6. Розробка функцій: Coursera
Приєднуйтесь до Coursera використовувати BigQuery ML, Keras і TensorFlow для розробки функцій. Цей курс середнього рівня також охоплює передові методи розробки функцій.
Книги в цифровій або твердій палітурці

#1. Розробка функцій для машинного навчання
Ця книга навчить вас перетворювати функції у формати для моделей машинного навчання.
Він також навчає вас інженерним принципам і практичному застосуванню за допомогою вправ.
#2. Розробка та вибір функцій
Прочитавши цю книгу, ви дізнаєтесь про методи розробки прогнозних моделей на різних етапах.
З нього ви можете навчитися прийомам пошуку найкращих представлень предикторів для моделювання.
#3. Розробка функцій стала легкою
Книга є посібником із підвищення можливостей прогнозування алгоритмів машинного навчання.
Він навчить вас розробляти та створювати ефективні функції для додатків на основі машинного навчання, пропонуючи глибокі дані.
#4. Особливий інженерний книжковий табір
Ця книга присвячена практичним тематичним дослідженням, щоб навчити вас методам розробки функцій для кращих результатів машинного навчання та оновленої обробки даних.
Прочитавши це, ви зможете отримати кращі результати, не витрачаючи багато часу на точне налаштування параметрів ML.
#5. Мистецтво розробки функцій
Ресурс є важливим елементом для будь-якого спеціаліста з обробки даних або інженера з машинного навчання.
У книзі використовується міждоменний підхід для обговорення графіків, текстів, часових рядів, зображень і тематичних досліджень.
Висновок
Таким чином, ви можете виконати розробку функцій. Тепер, коли ви знаєте визначення, поетапний процес, методи та навчальні ресурси, ви можете застосувати їх у своїх проектах МЛ і побачити успіх!
Далі перегляньте статтю про навчання з підкріпленням.