
З роками використання Python для науки про дані неймовірно зросло та продовжує зростати щодня.
Наука про дані — це величезна галузь дослідження з великою кількістю підгалузей, серед яких аналіз даних, безперечно, є однією з найважливіших із усіх цих галузей, і незалежно від рівня навичок у науці про дані стає все важливішим розуміти чи мати хоча б базові знання про це.
Що таке аналіз даних?
Аналіз даних — це очищення та перетворення великої кількості неструктурованих або невпорядкованих даних з метою отримання ключових ідей та інформації про ці дані, яка допоможе приймати обґрунтовані рішення.
Існують різні інструменти, що використовуються для аналізу даних, Python, Microsoft Excel, Tableau, SaS тощо, але в цій статті ми зосередимося на тому, як аналіз даних виконується в Python. Точніше, як це робиться з бібліотекою python під назвою панди.
Що таке панди?
Pandas — це бібліотека Python з відкритим кодом, яка використовується для маніпулювання даними та суперечок. Він швидкий і високоефективний і має інструменти для завантаження кількох видів даних у пам’ять. Його можна використовувати для зміни форми, позначення фрагментів, індексування або навіть групування кількох форм даних.
Структури даних у Pandas
У Pandas є 3 структури даних, а саме;
Найкращий спосіб відрізнити ці три з них — побачити, що один містить кілька стосів іншого. Отже, DataFrame — це стек серій, а Panel — це стек DataFrames.
Ряд — це одновимірний масив
Стек із кількох серій створює 2-вимірний DataFrame
Стек із кількох DataFrames створює тривимірну панель
Структура даних, з якою ми б найчастіше працювали, — це 2-вимірний DataFrame, який також може бути засобом представлення за замовчуванням для деяких наборів даних, які ми можемо зустріти.
Аналіз даних у Pandas
Для цієї статті установка не потрібна. Ми будемо використовувати інструмент під назвою співробітництво створений Google. Це онлайн-середовище Python для аналізу даних, машинного навчання та ШІ. Це просто хмарний блокнот Jupyter, у якому попередньо встановлено майже всі пакети Python, які знадобляться вам як досліднику даних.
Тепер переходьте до https://colab.research.google.com/notebooks/intro.ipynb. Ви повинні побачити нижче.
На навігаційній панелі вгорі ліворуч клацніть опцію файлу та виберіть опцію «новий блокнот». Ви побачите нову сторінку блокнота Jupyter, завантажену у вашому браузері. Перше, що нам потрібно зробити, це імпортувати панд у наше робоче середовище. Ми можемо зробити це, запустивши наступний код;
import pandas as pd
У цій статті ми будемо використовувати набір даних про ціни на житло для нашого аналізу даних. Набір даних, який ми будемо використовувати, можна знайти тут. Перше, що ми хотіли б зробити, це завантажити цей набір даних у наше середовище.
Ми можемо зробити це за допомогою наступного коду в новій клітинці;
df = pd.read_csv('https://firebasestorage.googleapis.com/v0/b/ai6-portfolio-abeokuta.appspot.com/o/kc_house_data.csv?alt=media &token=6a5ab32c-3cac-42b3-b534-4dbd0e4bdbc0 ', sep=',')
.read_csv використовується, коли ми хочемо прочитати файл CSV і ми передали властивість sep, щоб показати, що файл CSV розділений комами.
Слід також зауважити, що наш завантажений файл CSV зберігається в змінній df.
Нам не потрібно використовувати функцію print() у Jupyter Notebook. Ми можемо просто ввести назву змінної в клітинку, і Jupyter Notebook роздрукує її для нас.
Ми можемо спробувати це, ввівши df у нову клітинку та запустивши її, вона роздрукує всі дані в нашому наборі даних як DataFrame для нас.
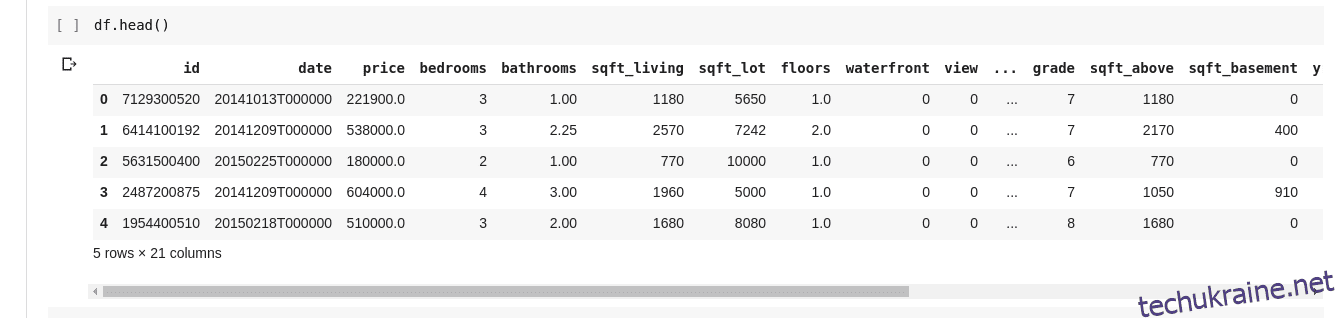
Але ми не завжди хочемо бачити всі дані, іноді ми хочемо бачити лише кілька перших даних і їхні назви стовпців. Ми можемо використовувати функцію df.head() для друку перших п’яти стовпців і df.tail() для друку останніх п’яти. Результат будь-якого з двох буде виглядати таким;
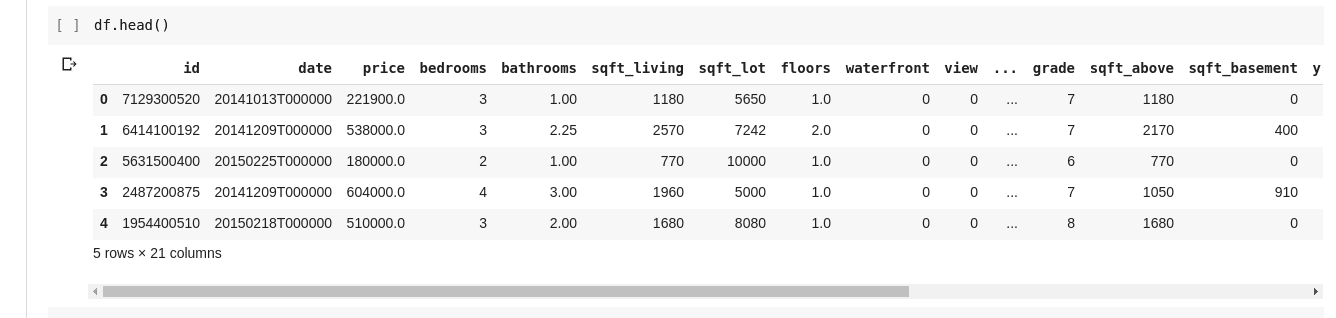
Ми хотіли б перевірити зв’язки між кількома рядками та стовпцями даних. Функція .describe() робить саме це за нас.
Запуск df.describe() дає наступний вихід;
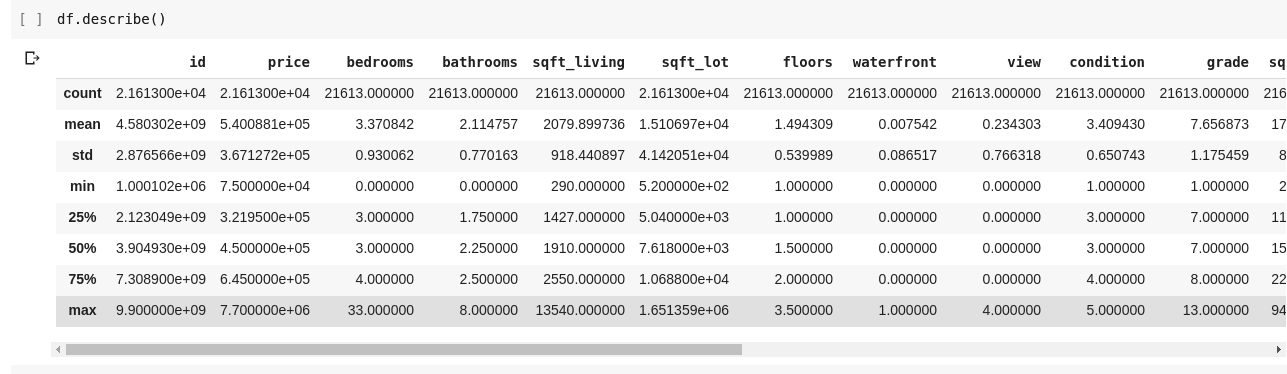
Ми відразу бачимо, що .describe() дає середнє значення, стандартне відхилення, мінімальне та максимальне значення та процентиль для кожного стовпця в DataFrame. Особливо це дуже корисно.
Ми також можемо перевірити форму нашого 2D DataFrame, щоб дізнатися, скільки в ньому рядків і стовпців. Ми можемо зробити це за допомогою df.shape, який повертає кортеж у форматі (рядки, стовпці).
Ми також можемо перевірити назви всіх стовпців у нашому DataFrame за допомогою df.columns.
Що, якщо ми хочемо вибрати лише один стовпець і повернути всі дані в ньому? Це робиться подібно до розрізання словника. Введіть наступний код у нову клітинку та запустіть його
df['price ']
Наведений вище код повертає стовпець ціни, ми можемо піти далі, зберігши його в новій змінній як такій
price = df['price']
Тепер ми можемо виконувати будь-яку іншу дію, яку можна виконати над DataFrame, над нашою змінною ціни, оскільки це лише підмножина фактичного DataFrame. Ми можемо робити такі речі, як df.head(), df.shape тощо.
Ми також можемо вибрати кілька стовпців, передавши список імен стовпців у df як такий
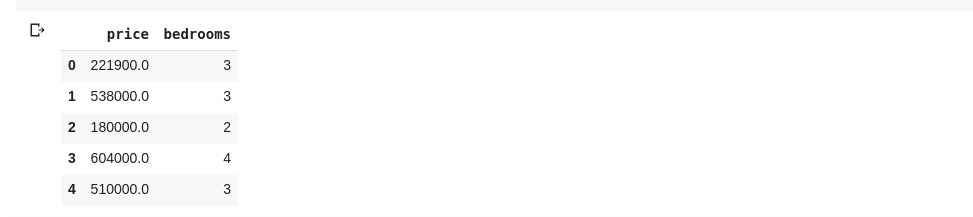
data = df[['price ', 'bedrooms']]
Вище вибрано стовпці з іменами «ціна» та «спальні». Якщо ми введемо data.head() у нову комірку, ми матимемо таке
Наведений вище спосіб розділення стовпців повертає всі елементи рядка в цьому стовпці. Що, якщо ми хочемо повернути підмножину рядків і підмножину стовпців із нашого набору даних? Це можна зробити за допомогою .iloc і індексується подібно до списків python. Тож ми можемо зробити щось подібне
df.iloc[50: , 3]
Повертає 3-й стовпець від 50-го рядка до кінця. Це досить акуратно і так само, як нарізка списків у python.
Тепер давайте займемося справді цікавими речами. У нашому наборі даних про ціни на житло є стовпець, який повідомляє нам ціну будинку, а інший стовпець повідомляє нам кількість спалень у цьому будинку. Ціна житла є постійною величиною, тому можливо, що у нас немає двох будинків з однаковою ціною. Але кількість спалень є дещо дискретною, тому ми можемо мати кілька будинків з двома, трьома, чотирма спальнями тощо.
Що, якщо ми хочемо отримати всі будинки з однаковою кількістю спалень і знайти середню ціну кожної окремої спальні? Це відносно легко зробити в пандах, це можна зробити як таке;
df.groupby('bedrooms ')['price '].mean()
Наведене вище спочатку групує DataFrame за наборами даних з ідентичним номером спальні за допомогою функції df.groupby(), потім ми кажемо йому надати нам лише стовпець спальні та використовуємо функцію .mean(), щоб знайти середнє значення кожного будинку в наборі даних. .
Що, якщо ми хочемо візуалізувати вищесказане? Ми хотіли б мати можливість перевірити, як змінюється середня ціна кожної окремої спальні? Нам просто потрібно зв’язати попередній код із функцією .plot() як такою;
df.groupby('bedrooms ')['price '].mean().plot()
Ми матимемо результат, який виглядає таким чином;
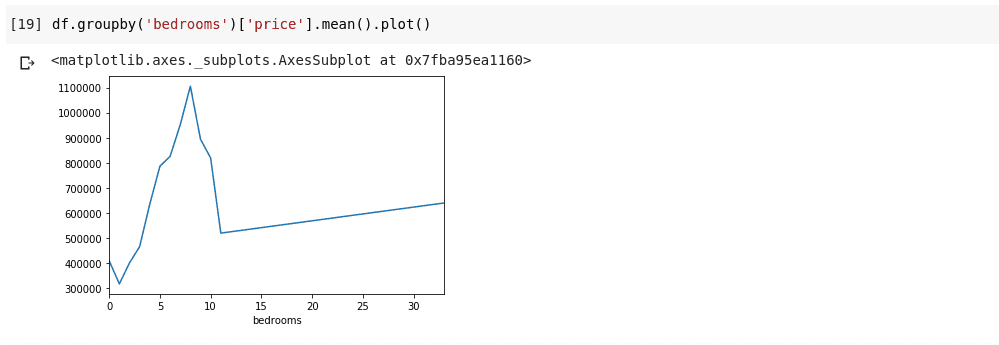
Наведене вище показує нам деякі тенденції в даних. На горизонтальній осі ми маємо певну кількість спалень (зауважте, що більше ніж один будинок може мати кількість спалень X). На вертикальній осі ми маємо середнє значення цін щодо відповідної кількості спалень на горизонталі вісь. Тепер ми можемо відразу помітити, що будинки з 5-10 спальнями коштують набагато дорожче, ніж будинки з 3 спальнями. Також стане очевидним, що будинки з 7 або 8 спальнями коштують набагато більше, ніж будинки з 15, 20 або навіть 30 кімнатами.
Інформація, подібна до наведеної вище, пояснює, чому аналіз даних дуже важливий. Ми можемо отримати корисну інформацію з даних, яку не відразу або зовсім неможливо помітити без аналізу.
Відсутні дані
Припустімо, що я беру участь в опитуванні, яке складається з низки запитань. Я ділюся посиланням на опитування з тисячами людей, щоб вони могли залишити свої відгуки. Моя кінцева мета полягає в тому, щоб провести аналіз цих даних, щоб я міг отримати деякі ключові ідеї з цих даних.
Тепер багато чого може піти не так, деякі геодезисти можуть відчувати себе некомфортно, відповідаючи на деякі з моїх запитань, і залишать поле порожнім. Багато людей могли б зробити те саме для кількох частин мого опитування. Це може не вважатися проблемою, але уявіть, якби я збирав числові дані під час свого опитування, і частина аналізу вимагала б від мене отримання суми, середнього значення або іншої арифметичної операції. Кілька відсутніх значень призведуть до великої кількості неточностей у моєму аналізі, мені потрібно знайти спосіб знайти та замінити ці відсутні значення деякими значеннями, які могли б їх замінити.
Pandas надає нам функцію для пошуку відсутніх значень у DataFrame під назвою isnull().
Функцію isnull() можна використовувати як таку;
df.isnull()
Це повертає DataFrame з логічними значеннями, які повідомляють нам, чи були дані, які спочатку присутні там, справді відсутніми чи помилково відсутніми. Результат виглядатиме таким чином;
Нам потрібен спосіб, щоб мати можливість замінити всі ці відсутні значення, найчастіше вибір відсутніх значень можна прийняти за нуль. Часом це можна вважати середнім значенням усіх інших даних або, можливо, середнім значенням навколишніх даних, залежно від дослідника даних і варіанту використання даних, що аналізуються.
Щоб заповнити всі відсутні значення у DataFrame, ми використовуємо функцію .fillna(), яка використовується як така;
df.fillna(0)
У наведеному вище ми заповнюємо всі порожні дані нульовим значенням. Це також може бути будь-яке інше число, яке ми вкажемо.
Важливість даних важко переоцінити, вони допомагають нам отримувати відповіді безпосередньо з самих даних!. Аналіз даних, за їх словами, є новою нафтою для цифрових економік.
Усі приклади можна знайти в цій статті тут.
Щоб дізнатися більше, перегляньте Онлайн-курс «Аналіз даних за допомогою Python і Pandas».