
Обчислювальна техніка сьогодні досягла свого піку та продовжує зростати. За останні 3 десятиліття машини еволюціонували та вдосконалили цілий ряд, особливо з точки зору обчислювальної потужності та багатозадачності.
Ви навіть можете уявити, яким божевільним може бути підвищення продуктивності, якщо завдання розподіляються між кількома машинами та виконуються паралельно? Це називається розподіленим обчисленням. Це як командна робота для комп’ютерів.
Однак, можливо, вам буде цікаво, чому ми обговорюємо цю тему розподілених обчислень. Оскільки розподілені обчислення і Amazon EMR (Elastic MapReduce) дуже пов’язані. Тобто EMR від AWS використовує принципи розподілених обчислень для обробки та аналізу великих обсягів даних у хмарі.
Завдяки Amazon EMR тепер ви можете аналізувати й обробляти великі дані за допомогою розподіленої обробки даних за вашим вибором на примірниках S3.
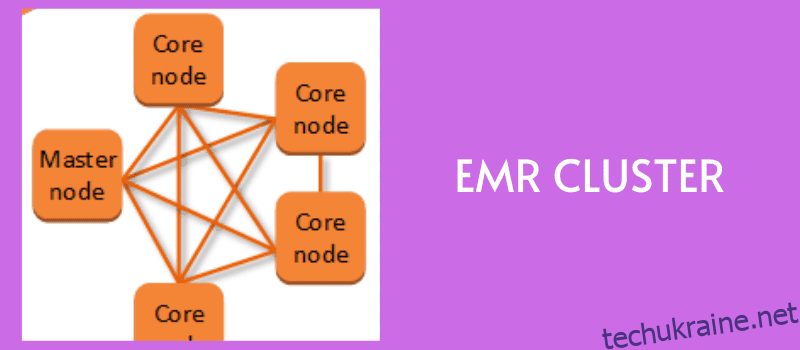
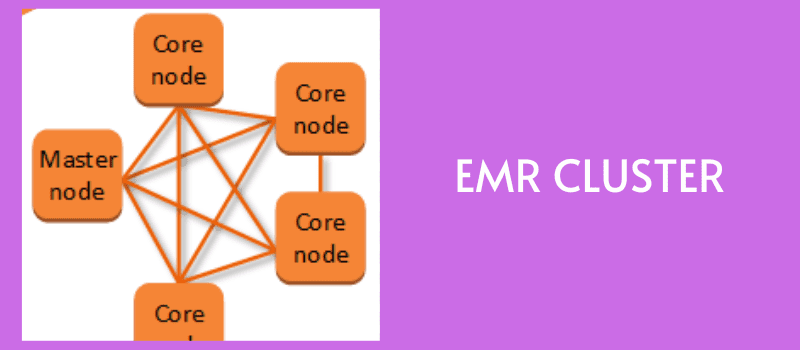
Як працює Amazon EMR?
Джерело: aws.amazon.com
По-перше, введіть дані в будь-яке сховище даних, наприклад Amazon S3, DynamoDB або інші платформи зберігання AWS, оскільки всі вони добре інтегруються з EMR.
Тепер вам знадобиться структура великих даних для обробки та аналізу цих даних. З різними платформами великих даних на вибір, такими як Apache Spark, Hadoop, Hive і Presto, ви можете вибрати той, який відповідає вашим вимогам, і завантажити його у вибране сховище даних.
Для паралельної обробки та аналізу даних створюється кластер EMR екземплярів EC2. Ви можете налаштувати кількість вузлів та інші деталі для створення кластера.
Ваше основне сховище розподіляє дані та інфраструктури між цими вузлами, де фрагменти даних обробляються окремо, а результати об’єднуються.
Після отримання результатів ви можете припинити роботу кластера, щоб звільнити всі виділені ресурси.
Переваги Amazon EMR
Компанії, малі чи великі, завжди розглядають можливість прийняття економічно ефективних рішень. Тоді чому б не доступний Amazon EMR? Коли це може спростити запуск різноманітних фреймворків великих даних на AWS, забезпечуючи зручний спосіб обробки та аналізу ваших даних, заощаджуючи гроші.
✅ Еластичність: ви можете здогадатися про її природу за допомогою терміна «Elastic MapReduce». Термін говорить: Amazon EMR дозволяє легко змінювати розміри кластерів вручну або автоматично відповідно до вимог. Наприклад, зараз вам може знадобитися 200 екземплярів для обробки ваших запитів, а через годину чи дві це число може збільшитися до 600 інстанцій. Отже, Amazon EMR є найкращим, коли вам потрібна лише масштабованість, щоб адаптуватися до швидких змін попиту.
✅ Сховища даних: будь то Amazon S3, розподілена файлова система Hadoop, Amazon DynamoDB або інші сховища даних AWS, Amazon EMR легко інтегрується з ними.
✅ Інструменти обробки даних: Amazon EMR підтримує різні фреймворки великих даних, зокрема Apache Spark, Hive, Hadoop і Presto. Крім того, ви можете запускати алгоритми та інструменти глибокого та машинного навчання на цьому фреймворку.
✅ Економічно: на відміну від інших комерційних продуктів, Amazon EMR дозволяє вам платити лише за ті ресурси, які ви використовуєте на погодинній основі. Крім того, ви можете вибрати різні моделі ціноутворення, які відповідають вашому бюджету.
✅ Налаштування кластера: фреймворк дозволяє налаштувати кожен екземпляр вашого кластера. Крім того, ви можете поєднати структуру великих даних із ідеальним типом кластера. Наприклад, екземпляри на базі Apache Spark і Graviton2 є смертоносною комбінацією для оптимізації продуктивності в EMR.
✅ Контроль доступу: ви можете використовувати інструменти AWS Identity and Access Management (IAM), щоб контролювати дозволи в EMR. Наприклад, ви можете дозволити певним користувачам редагувати кластер, тоді як інші можуть лише переглядати кластер.
✅ Інтеграція: інтеграція EMR з усіма іншими службами AWS є бездоганною. Завдяки цьому ви можете отримати потужність віртуальних серверів, надійну безпеку, розширювану ємність і можливості аналітики в EMR.
Приклади використання Amazon EMR
#1. Машинне навчання

Аналізуйте дані за допомогою машинного та глибокого навчання в Amazon EMR. Наприклад, запуск різних алгоритмів на даних, пов’язаних із здоров’ям, для відстеження багатьох показників здоров’я, таких як індекс маси тіла, частота серцевих скорочень, артеріальний тиск, відсоток жиру тощо, є вирішальним для розробки фітнес-трекера. Усе це можна зробити на примірниках EMR швидше та ефективніше.
#2. Виконайте великі перетворення
Роздрібні продавці зазвичай збирають велику кількість цифрових даних, щоб проаналізувати поведінку клієнтів і покращити бізнес. Крім того, Amazon EMR буде ефективним у збиранні великих даних і виконанні великих перетворень за допомогою Spark.
#3. Видобуток даних

Ви хочете звернутися до набору даних, обробка якого займає багато часу? Amazon EMR призначений виключно для інтелектуального аналізу даних і прогнозної аналітики складних наборів даних, особливо у випадках неструктурованих даних. Крім того, його кластерна архітектура чудово підходить для паралельної обробки.
#4. Цілі дослідження
Проведіть дослідження за допомогою цієї економічно вигідної та ефективної системи Amazon EMR. Завдяки його масштабованості ви рідко бачите проблеми з продуктивністю під час запуску великих наборів даних на EMR. Таким чином, цей фреймворк добре адаптований для дослідження великих даних і аналітичних лабораторій.
#5. Потокове передавання в реальному часі
Ще однією важливою перевагою Amazon EMR є підтримка потокового передавання в реальному часі. Створюйте масштабовані канали потокових даних у реальному часі для онлайн-ігор, потокового відео, моніторингу трафіку та торгівлі акціями за допомогою Apache Kafka та Apache Flink на Amazon EMR.
Чим EMR відрізняється від Amazon Glue і Redshift?
AWS EMR проти клею
Дві потужні служби AWS – Amazon EMR і Amazon Glue отримали лояльне зауваження щодо роботи з вашими даними.
Отримання даних із різних джерел, перетворення та завантаження їх у сховища даних відбувається швидко й ефективно за допомогою Amazon Glue, тоді як Amazon EMR допомагає обробляти ваші програми для великих даних за допомогою Hadoop, Spark, Hive тощо.
По суті, AWS Glue дозволяє збирати та готувати дані для аналізу, а Amazon EMR дозволяє їх обробляти.
ЕМВ проти червоного зсуву
Уявіть себе, як ви постійно переглядаєте свої дані та з легкістю запитуєте їх. Для цього ви часто використовуєте SQL. Крім того, Redshift пропонує оптимізовані служби онлайн-аналітичної обробки для легкого запиту великих обсягів даних за допомогою SQL.
Зберігаючи дані, ви матимете доступ до масштабованих, безпечних і доступних Amazon EMR, які використовують сторонні постачальники сховищ, як-от S3 і DynamoDB. На відміну від цього, Redshift має власний рівень даних, що дозволяє зберігати дані у форматі стовпців.
Підходи до оптимізації витрат Amazon EMR

#1. Поставтеся з відформатованими даними
Чим більше даних, тим більше часу потрібно для обробки. Крім того, подача необроблених даних безпосередньо в кластер робить його ще більш складним, забираючи більше часу, щоб знайти частину, яку ви збираєтеся обробити.
Отже, відформатовані дані постачаються з метаданими про стовпці, тип даних, розмір тощо, використовуючи які, ви можете заощадити час на пошуки та агрегації.
Крім того, зменште обсяг даних, використовуючи методи стиснення даних, оскільки порівняно легше обробляти менші набори даних.
#2. Використовуйте доступні послуги зберігання
Використання економічно ефективних послуг первинного зберігання скорочує ваші основні витрати на EMR. Amazon s3 — це простий і доступний сервіс зберігання для збереження вхідних і вихідних даних. Його розрахована модель стягує плату лише за фактично використаний обсяг пам’яті.
#3. Правильний розмір екземпляра
Використання відповідних екземплярів із потрібними розмірами може значно скоротити ваш бюджет, витрачений на EMR. Примірники EC2 зазвичай оплачуються за секунду, а ціна залежить від їх розміру, але незалежно від того, чи використовуєте ви кластер розміром 0,7x або 0,36x, вартість керування ними однакова. Таким чином, ефективне використання більших машин є рентабельним порівняно з використанням кількох маленьких машин.
#4. Точкові екземпляри
Точкові екземпляри — це чудовий варіант придбання невикористаних ресурсів EC2 зі знижками. Порівняно з екземплярами On-demand вони коштують дешевше, але не є постійними, оскільки їх можна вимагати назад, коли попит зростає. Отже, вони гнучкі для відмовостійкості, але не підходять для тривалих робіт.
#5. Автоматичне масштабування
Функція автоматичного масштабування — це все, що вам потрібно, щоб уникнути великих або менших кластерів. Це дає змогу вибрати потрібну кількість і тип екземплярів у вашому кластері залежно від робочого навантаження, оптимізуючи витрати.
Заключні слова
Немає кінця хмарі та технології великих даних, залишаючи вам безмежні інструменти та фреймворки для навчання та впровадження. Однією з таких єдиних платформ для використання як великих даних, так і хмари є Amazon EMR, оскільки вона спрощує запуск інфраструктури великих даних для обробки та аналізу великих даних.
Щоб допомогти вам розпочати роботу з EMR, ця стаття пояснює, що це таке, які переваги, його роботу, варіанти використання та економічні підходи.
Далі перегляньте все, що вам потрібно знати про AWS Athena.