

1 вересня 2020 року NVIDIA представила нову лінійку ігрових графічних процесорів: серію RTX 3000, засновану на архітектурі Ampere. Ми обговоримо, що нового, програмне забезпечення на базі штучного інтелекту, яке постачається з ним, і всі деталі, які роблять це покоління справді чудовим.
Зустрічайте графічні процесори серії RTX 3000

Головним оголошенням NVIDIA були нові блискучі графічні процесори, всі вони побудовані на спеціальному 8-нм виробничому процесі, і всі вони забезпечують значне прискорення як в розтерізації, так і в продуктивності трасування променів.
У нижньому кінці лінійки є RTX 3070, що коштує 499 доларів США. Це трохи дорожче для найдешевшої карти, представленої NVIDIA під час початкового анонсу, але це абсолютна крадіжка, як тільки ви дізнаєтеся, що вона перевершує існуючу RTX 2080 Ti, топ-карту, яка регулярно продається за 1400 доларів. Однак після оголошення NVIDIA ціни на сторонні розпродажі впали, і велика кількість з них була продана на eBay за ціною менше 600 доларів.
На момент оголошення немає твердих тестів, тому незрозуміло, чи карта дійсно об’єктивно «краща», ніж 2080 Ti, чи NVIDIA трохи змінює маркетинг. Тести, які проводилися, були на рівні 4K і, ймовірно, ввімкнено RTX, що може змусити розрив виглядати більшим, ніж у чисто растеризованих іграх, оскільки серія 3000 на базі Ampere буде працювати вдвічі краще при трасуванні променів, ніж Turing. Але, оскільки трасування променів зараз є чимось, що не сильно впливає на продуктивність, і підтримується в консолях останнього покоління, важливою перевагою є те, що вона працює так само швидко, як флагман останнього покоління, майже за третину ціни.
Також неясно, чи залишиться ціна такою. Розробки сторонніх розробників регулярно додають щонайменше 50 доларів до ціни, і, зважаючи на те, наскільки високим буде попит, не дивно, що в жовтні 2020 року його продають за 600 доларів.
Трохи вище цього є RTX 3080 за 699 доларів, що має бути вдвічі швидше, ніж RTX 2080, і приблизно на 25-30% швидше, ніж 3080.
Потім, у верхній частині, новий флагман RTX 3090, який комічно величезний. NVIDIA добре знає і називає це «BFGPU», що, за словами компанії, означає «Big Ferocious GPU».

NVIDIA не показала жодних прямих показників продуктивності, але компанія показала, що запускає ігри 8K зі швидкістю 60 кадрів в секунду, що вражає. Звичайно, NVIDIA майже напевно використовує DLSS, щоб досягти цієї позначки, але ігри 8K є іграми 8K.
Звичайно, згодом з’явиться 3060 та інші варіанти більш бюджетних карт, але вони зазвичай з’являються пізніше.
Щоб охолодити ці речі, NVIDIA знадобилася оновлена конструкція кулера. 3080 розрахований на 320 Вт, що є досить високим показником, тому NVIDIA вибрала конструкцію з подвійним вентилятором, але замість обох вентиляторів vwinf, розміщених у нижній частині, NVIDIA розмістила вентилятор у верхній частині, де зазвичай йде задня панель. Вентилятор спрямовує повітря вгору до кулера процесора та верхньої частини корпусу.

Судячи з того, наскільки поганий потік повітря в корпусі може вплинути на продуктивність, це цілком зрозуміло. Однак через це друкована плата дуже тісна, що, ймовірно, вплине на продажні ціни третіх сторін.
DLSS: перевага програмного забезпечення
Трасування променів – не єдина перевага цих нових карт. Насправді, все це трохи хак — серії RTX 2000 і 3000 не набагато кращі у виконанні фактичної трасування променів, порівняно зі старшими поколіннями карт. Трасування променів на повну сцену в програмному забезпеченні 3D, як-от Blender, зазвичай займає кілька секунд або навіть хвилин на кадр, тому брутфорсування менш ніж за 10 мілісекунд не може бути й мови.
Звичайно, існує спеціальне обладнання для виконання обчислень променів, яке називається ядрами RT, але в основному NVIDIA вибрала інший підхід. NVIDIA покращила алгоритми шумозаглушення, які дозволяють графічним процесорам відображати дуже дешевий одиничний прохід, який виглядає жахливо, і якимось чином — за допомогою магії ШІ — перетворювати це на те, на що геймер хоче подивитися. У поєднанні з традиційними методами, заснованими на растеризации, це створює приємний досвід, посилений ефектами трасування променів.

Однак, щоб зробити це швидко, NVIDIA додала специфічні для штучного інтелекту ядра обробки, які називаються тензорними ядрами. Вони обробляють всю математику, необхідну для запуску моделей машинного навчання, і роблять це дуже швидко. Вони загальні зміна гри для штучного інтелекту в просторі хмарного сервера, оскільки AI широко використовується багатьма компаніями.
Крім шумозаглушення, основне використання ядер Tensor для геймерів називається DLSS, або супервибірка глибокого навчання. Він бере кадр низької якості та покращує його до повної рідної якості. Це, по суті, означає, що ви можете грати з частотою кадрів на рівні 1080p, дивлячись на зображення 4K.
Це також значно покращує ефективність трасування променів —тести від PCMag покажіть RTX 2080 Super Running Control у надякісній якості, з усіма налаштуваннями трасування променів, налаштованими на максимум. У 4K він бореться лише з 19 кадрами в секунду, але з увімкненим DLSS він отримує набагато кращі 54 кадри в секунду. DLSS — це безкоштовна продуктивність для NVIDIA, що стала можливою завдяки ядрам Tensor на Turing і Ampere. Будь-яка гра, яка підтримує його та обмежена GPU, може отримати серйозне прискорення лише через програмне забезпечення.
DLSS не є новим, і було оголошено як функція, коли серія RTX 2000 була запущена два роки тому. У той час його підтримувало дуже мало ігор, оскільки від NVIDIA потрібно було навчати та налаштовувати модель машинного навчання для кожної окремої гри.
Однак за цей час NVIDIA повністю переписала його, назвавши нову версію DLSS 2.0. Це API загального призначення, що означає, що будь-який розробник може реалізувати його, і його вже підхопили більшість основних випусків. Замість того, щоб працювати над одним кадром, він приймає векторні дані з попереднього кадру, як і TAA. Результат набагато чіткіший, ніж DLSS 1.0, а в деяких випадках насправді виглядає краще і чіткіше, ніж навіть рідна роздільна здатність, тому немає особливих причин не вмикати його.
Є одна загвоздка — під час повного перемикання сцен, як у роликах, DLSS 2.0 має відображати перший кадр із 50% якістю, очікуючи на дані вектора руху. Це може призвести до незначного зниження якості на кілька мілісекунд. Але 99% всього, що ви дивитеся, буде відтворено належним чином, і більшість людей не помічає цього на практиці.
Архітектура Ampere: створена для AI
Ампер швидкий. Серйозно швидкий, особливо при обчисленнях AI. Ядро RT в 1,7 рази швидше, ніж у Тьюринга, а нове ядро Tensor в 2,7 рази швидше, ніж у Тьюринга. Поєднання обох є справжнім стрибком поколінь у продуктивності трасування променів.

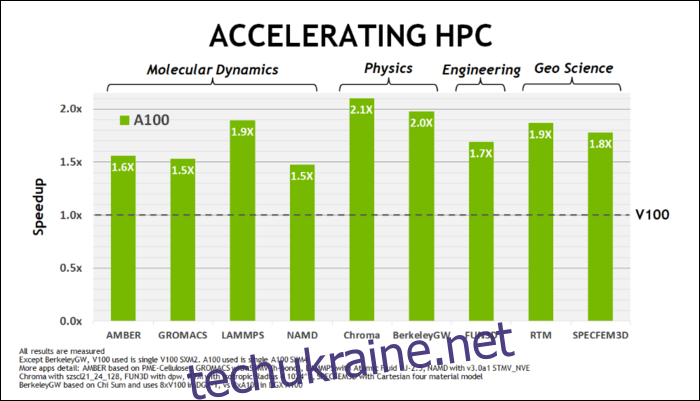
Раніше цього травня, NVIDIA випустила графічний процесор Ampere A100, графічний процесор для центрів обробки даних, розроблений для роботи зі штучним інтелектом. З його допомогою вони детально розповіли про те, що робить Ampere набагато швидшим. Для центрів обробки даних і високопродуктивних обчислювальних навантажень Ampere загалом приблизно в 1,7 рази швидше, ніж Turing. Для навчання ШІ це в 6 разів швидше.
З Ampere NVIDIA використовує новий формат чисел, призначений для заміни промислового стандарту «Floating-Point 32» або FP32 у деяких робочих навантаженнях. Під капотом кожне число, яке обробляє ваш комп’ютер, займає певну кількість бітів у пам’яті, будь то 8 біт, 16 біт, 32, 64 або навіть більше. Більші числа важче обробляти, тому, якщо ви можете використовувати менший розмір, у вас буде менше хрустів.
FP32 зберігає 32-бітове десяткове число і використовує 8 біт для діапазону числа (наскільки великим або маленьким воно може бути) і 23 біти для точності. NVIDIA стверджує, що ці 23 точні біти не зовсім необхідні для багатьох робочих навантажень AI, і ви можете отримати подібні результати та набагато кращу продуктивність лише з 10 з них. Зменшення розміру до 19 біт замість 32 має велику різницю в багатьох обчисленнях.
Цей новий формат називається Tensor Float 32, а тензорні ядра в A100 оптимізовані для роботи з форматом дивного розміру. Це, крім того, що кубик скорочується та збільшується кількість ядер, вони отримують величезне 6-кратне прискорення під час навчання ШІ.

Крім нового формату чисел, Ampere спостерігає значне підвищення продуктивності в конкретних обчисленнях, таких як FP32 і FP64. Це не означає прямого збільшення FPS для неспеціаліста, але вони є частиною того, що робить його майже втричі швидшим загалом під час операцій Tensor.

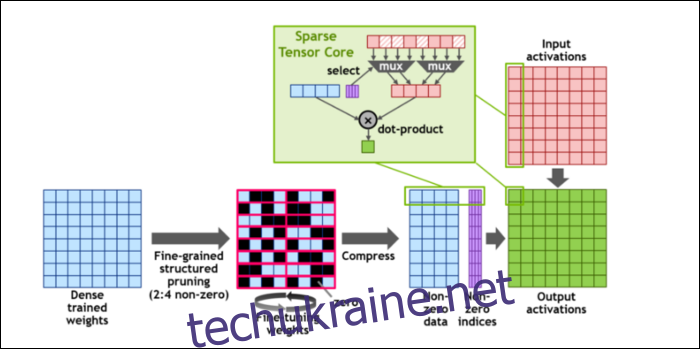
Потім, щоб ще більше прискорити обчислення, вони ввели концепцію дрібнозерниста структурована розрідженість, що є дуже химерним словом для досить простої концепції. Нейронні мережі працюють з великими списками чисел, які називаються вагами, які впливають на кінцевий результат. Чим більше чисел буде хрустнути, тим повільніше це буде.
Однак не всі ці цифри насправді корисні. Деякі з них буквально рівні нулю, і їх можна викинути, що призводить до значного прискорення, коли ви можете нарахувати більше чисел одночасно. Розрідженість по суті стискає числа, що вимагає менше зусиль для обчислень. Нове “Sparse Tensor Core” створено для роботи зі стиснутими даними.
Незважаючи на зміни, NVIDIA стверджує, що це взагалі не повинно вплинути на точність навчених моделей.
Для обчислень Sparse INT8, одного з найменших числових форматів, максимальна продуктивність одного GPU A100 становить понад 1,25 Петафлопс, що є вражаюче високим показником. Звісно, це лише під час визначення одного конкретного числа, але це вражає.