
MapReduce пропонує ефективний, швидший і економічно ефективний спосіб створення програм.
Ця модель використовує передові концепції, такі як паралельна обробка, локальність даних тощо, щоб надати багато переваг програмістам і організаціям.
Але на ринку так багато доступних моделей програмування та фреймворків, що вибрати стає важко.
А коли мова йде про великі дані, ви не можете просто вибрати щось. Ви повинні вибрати такі технології, які можуть обробляти великі блоки даних.
MapReduce є чудовим рішенням для цього.
У цій статті я розповім, що насправді таке MapReduce і чим він може бути корисний.
Давайте розпочнемо!
Що таке MapReduce?
MapReduce — це модель програмування або програмна основа в рамках Apache Hadoop. Він використовується для створення додатків, здатних обробляти масивні дані паралельно на тисячах вузлів (званих кластерами або сітками) з відмовостійкістю та надійністю.
Ця обробка даних відбувається в базі даних або файловій системі, де зберігаються дані. MapReduce може працювати з файловою системою Hadoop (HDFS) для доступу та керування великими обсягами даних.
Цей фреймворк був представлений у 2004 році Google і популяризується Apache Hadoop. Це рівень обробки або механізм у Hadoop, який запускає програми MapReduce, розроблені різними мовами, включаючи Java, C++, Python і Ruby.
Програми MapReduce у хмарних обчисленнях працюють паралельно, тому придатні для виконання аналізу даних у великих масштабах.
MapReduce має на меті розділити завдання на менші кілька завдань за допомогою функцій «map» і «reduce». Він відобразить кожне завдання, а потім зведе його до кількох еквівалентних завдань, що призведе до меншої потужності обробки та витрат на мережу кластера.
Приклад: припустимо, ви готуєте їжу для будинку, повного гостей. Отже, якщо ви спробуєте приготувати всі страви та виконати всі процеси самостійно, це стане неспокійним і трудомістким.
Але припустімо, що ви залучаєте кількох своїх друзів або колег (не гостей), щоб допомогти вам приготувати їжу, розподіляючи різні процеси іншій особі, яка може виконувати завдання одночасно. У цьому випадку ви приготуєте їжу швидше і легше, поки гості ще вдома.
MapReduce працює подібним чином із розподіленими завданнями та паралельною обробкою, щоб забезпечити швидший і простіший спосіб виконання певного завдання.
Apache Hadoop дозволяє програмістам використовувати MapReduce для виконання моделей на великих розподілених наборах даних і використовувати вдосконалені методи машинного навчання та статистичні методи для пошуку закономірностей, прогнозування, точкової кореляції тощо.
Особливості MapReduce
Деякі з основних функцій MapReduce:
- Інтерфейс користувача: ви отримаєте інтуїтивно зрозумілий інтерфейс користувача, який надає розумні відомості про кожен аспект фреймворку. Це допоможе вам легко налаштувати, застосувати та налаштувати свої завдання.

- Корисне навантаження: програми використовують інтерфейси Mapper і Reducer, щоб увімкнути функції карти та зменшення. Mapper зіставляє вхідні пари ключ-значення з проміжними парами ключ-значення. Редуктор використовується для зменшення проміжних пар ключ-значення, які мають спільний ключ, до інших менших значень. Він виконує три функції – сортування, перетасування та зменшення.
- Розділювач: керує розподілом проміжних ключів виводу карти.
- Репортер: це функція для звітування про прогрес, оновлення лічильників і встановлення повідомлень про статус.
- Лічильники: це глобальні лічильники, які визначає програма MapReduce.
- OutputCollector: ця функція збирає вихідні дані з Mapper або Reducer замість проміжних виходів.
- RecordWriter: записує вихідні дані або пари ключ-значення у вихідний файл.
- DistributedCache: ефективно розповсюджує більші файли, призначені лише для читання, які залежать від програми.
- Стиснення даних: автор програми може стискати як вихідні дані завдань, так і проміжні вихідні дані карти.
- Пропуск невдалих записів: ви можете пропустити кілька невдалих записів під час обробки вхідних даних карти. Цією функцією можна керувати за допомогою класу SkipBadRecords.
- Налагодження: Ви отримаєте можливість запускати визначені користувачем сценарії та вмикати налагодження. Якщо завдання в MapReduce не виконується, ви можете запустити свій сценарій налагодження та знайти проблеми.
Архітектура MapReduce
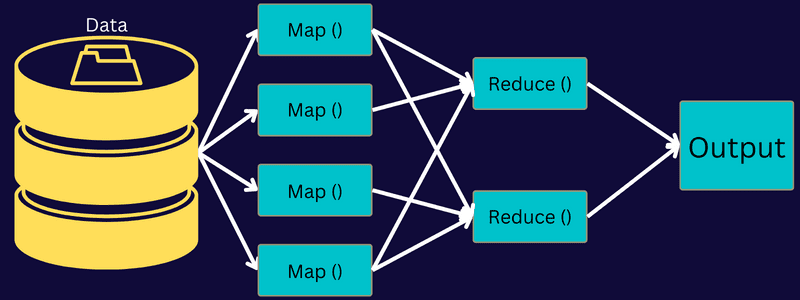
Давайте розберемося з архітектурою MapReduce, заглибившись у її компоненти:
- Робота: робота в MapReduce — це фактичне завдання, яке хоче виконати клієнт MapReduce. Він складається з кількох менших завдань, які об’єднуються в кінцеве завдання.
- Сервер історії завдань: це демон-процес для зберігання та збереження всіх історичних даних про програму чи завдання, наприклад журналів, створених після або до виконання завдання.
- Клієнт: клієнт (програма або API) передає завдання в MapReduce для виконання або обробки. У MapReduce один або декілька клієнтів можуть безперервно надсилати завдання до менеджера MapReduce для обробки.
- MapReduce Master: MapReduce Master ділить роботу на кілька менших частин, забезпечуючи одночасне виконання завдань.
- Частини завдання: підзавдання або частини завдання отримують шляхом поділу основного завдання. Вони опрацьовуються та об’єднуються, щоб створити остаточне завдання.
- Вхідні дані: це набір даних, який передається в MapReduce для обробки завдань.
- Вихідні дані: це кінцевий результат, отриманий після обробки завдання.
Отже, що насправді відбувається в цій архітектурі, клієнт надсилає завдання MasterReduce Master, який ділить його на менші рівні частини. Це дає змогу швидше обробляти завдання, оскільки менші завдання займають менше часу, ніж великі завдання.
Однак переконайтеся, що завдання не розділені на надто малі завдання, тому що, якщо ви це зробите, вам, можливо, доведеться зіткнутися з більшими накладними витратами на керування розподілами та витратити на це значну кількість часу.
Далі частини завдань стають доступними для продовження завдань Map і Reduce. Крім того, завдання Map і Reduce мають відповідну програму на основі сценарію використання, над яким працює команда. Програміст розробляє логічний код для виконання вимог.
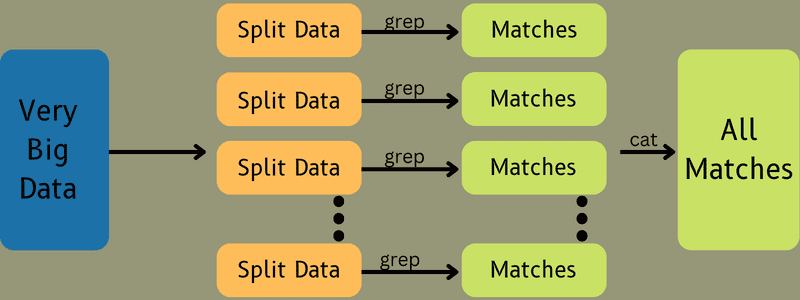
Після цього вхідні дані передаються в Завдання карти, щоб Карта могла швидко генерувати вихідні дані як пару ключ-значення. Замість того, щоб зберігати ці дані на HDFS, для зберігання даних використовується локальний диск, щоб виключити ймовірність реплікації.
Після виконання завдання ви можете викинути результат. Отже, реплікація стане надмірною, якщо ви зберігаєте вихідні дані на HDFS. Вихідні дані кожного завдання карти буде подано до завдання скорочення, а вихідні дані карти буде надано машині, на якій виконується завдання скорочення.
Далі вихідні дані будуть об’єднані та передані до функції зменшення, визначеної користувачем. Зрештою, скорочений вихід буде збережено на HDFS.
Крім того, процес може мати кілька завдань Map і Reduce для обробки даних залежно від кінцевої мети. Алгоритми Map і Reduce оптимізовані, щоб зберегти мінімальну складність часу або простору.
Оскільки MapReduce насамперед включає завдання Map і Reduce, доцільно дізнатися про них більше. Отже, давайте обговоримо етапи MapReduce, щоб отримати чітке уявлення про ці теми.
Фази MapReduce
Карта
На цьому етапі вхідні дані відображаються у вихідні або пари ключ-значення. Тут ключ може посилатися на ідентифікатор адреси, тоді як значення може бути фактичним значенням цієї адреси.
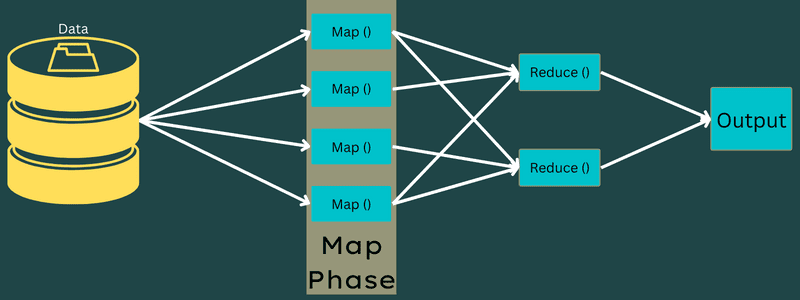
На цьому етапі є лише одне, але два завдання – розбиття та відображення. Розділ означає підчастини або частини роботи, відокремлені від основної роботи. Вони також називаються вхідними розділеннями. Отже, розділення вхідних даних можна назвати блоком вхідних даних, який споживає карта.
Далі виконується завдання картографування. Це вважається першою фазою під час виконання програми зменшення карти. Тут дані, що містяться в кожному розділенні, будуть передані функції карти для обробки та генерації виходу.
Функція – Map() виконується в сховищі пам’яті над вхідними парами ключ-значення, генеруючи проміжну пару ключ-значення. Ця нова пара ключ-значення працюватиме як вхідна інформація для функції Reduce() або Reducer.
Зменшити
Проміжні пари ключ-значення, отримані на етапі зіставлення, працюють як вхідні дані для функції Reduce або Reducer. Подібно до етапу картографування, тут беруть участь два завдання – перетасувати та зменшити.
Отже, отримані пари ключ-значення сортуються та перемішуються для передачі в Reducer. Далі Reducer групує або агрегує дані відповідно до своєї пари ключ-значення на основі алгоритму Reducer, який написав розробник.
Тут значення з фази перетасування об’єднуються для повернення вихідного значення. Ця фаза підсумовує весь набір даних.
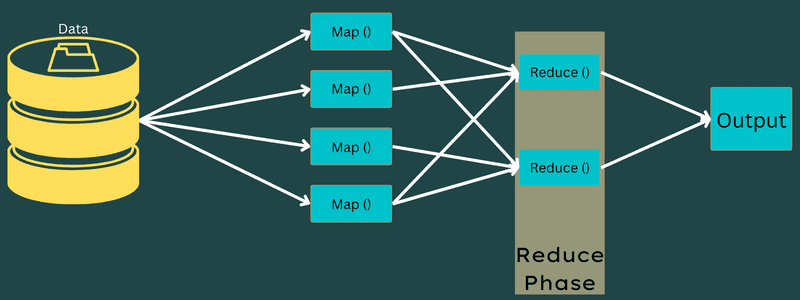
Тепер повний процес виконання завдань Map and Reduce контролюється деякими сутностями. Це:
- Job Tracker: Простіше кажучи, Job Tracker діє як майстер, який відповідає за повне виконання наданого завдання. Засіб відстеження завдань керує всіма завданнями та ресурсами в кластері. Крім того, засіб відстеження завдань планує кожну карту, додану в Відстеження завдань, яка працює на певному вузлі даних.
- Кілька трекерів завдань: Простіше кажучи, кілька трекерів завдань працюють як підлеглі, виконуючи завдання згідно з інструкціями Job Tracker. Трекер завдань розгортається на кожному вузлі окремо в кластері, що виконує завдання Map і Reduce.
Це працює, оскільки завдання буде розділено на кілька завдань, які виконуватимуться на різних вузлах даних кластера. Job Tracker відповідає за координацію завдання, плануючи завдання та запускаючи їх на кількох вузлах даних. Далі засіб відстеження завдань, розташований на кожному вузлі даних, виконує частини завдання та стежить за кожним завданням.
Крім того, засоби відстеження завдань надсилають звіти про хід у систему відстеження завдань. Крім того, Task Tracker періодично надсилає сигнал «серцебиття» Job Tracker і сповіщає їх про стан системи. У разі будь-якої помилки засіб відстеження завдань здатний перепланувати завдання на інший пристрій відстеження завдань.
Фаза виводу: коли ви досягнете цієї фази, ви матимете остаточні пари ключ-значення, згенеровані з Reducer. Ви можете використовувати засіб форматування виводу, щоб перекласти пари ключ-значення та записати їх у файл за допомогою програми запису.
Навіщо використовувати MapReduce?
Ось деякі з переваг MapReduce, пояснюючи причини, чому ви повинні використовувати його у своїх програмах для великих даних:
Паралельна обробка
Ви можете розділити завдання на різні вузли, де кожен вузол одночасно обробляє частину цього завдання в MapReduce. Отже, поділ великих завдань на менші зменшує складність. Крім того, оскільки різні завдання виконуються паралельно на різних машинах, а не на одній машині, обробка даних займає значно менше часу.
Локальність даних
У MapReduce ви можете перемістити блок обробки даних, а не навпаки.
Традиційними способами дані доставлялися в блок обробки для обробки. Однак зі швидким зростанням даних цей процес став створювати багато проблем. Деякі з них були вищими вартістю, більшими витратами часу, навантаженням на головний вузол, частими збоями та зниженням продуктивності мережі.
Але MapReduce допомагає подолати ці проблеми, дотримуючись зворотного підходу – підключаючи блок обробки до даних. Таким чином, дані розподіляються між різними вузлами, де кожен вузол може обробити частину збережених даних.
Як результат, це забезпечує економічну ефективність і скорочує час обробки, оскільки кожен вузол працює паралельно з відповідною частиною даних. Крім того, оскільки кожен вузол обробляє частину цих даних, жоден вузол не буде перевантажений.
Безпека

Модель MapReduce пропонує вищий рівень безпеки. Це допомагає захистити вашу програму від неавторизованих даних, одночасно підвищуючи безпеку кластера.
Масштабованість і гнучкість
MapReduce — це високомасштабована структура. Це дозволяє запускати програми з кількох машин, використовуючи дані обсягом тисячі терабайт. Він також пропонує гнучкість обробки даних, які можуть бути структурованими, напівструктурованими або неструктурованими та будь-якого формату чи розміру.
Простота
Ви можете писати програми MapReduce будь-якою мовою програмування, як-от Java, R, Perl, Python тощо. Таким чином, будь-кому легко вивчити та написати програми, забезпечуючи дотримання вимог щодо обробки даних.
Випадки використання MapReduce
- Повнотекстове індексування: MapReduce використовується для виконання повнотекстового індексування. Його Mapper може зіставляти кожне слово чи фразу в одному документі. А Reducer використовується для запису всіх зіставлених елементів в індекс.
- Розрахунок Pagerank: Google використовує MapReduce для обчислення Pagerank.
- Аналіз журналу: MapReduce може аналізувати файли журналу. Він може розбити великий файл журналу на різні частини або розділити, поки картограф шукає доступні веб-сторінки.
Якщо веб-сторінку буде помічено в журналі, у редуктор буде передано пару ключ-значення. Тут веб-сторінка буде ключем, а індекс «1» — значенням. Після передачі пари ключ-значення Reducer різні веб-сторінки будуть агреговані. Остаточним результатом є загальна кількість відвідувань для кожної веб-сторінки.

- Зворотний графік веб-посилань: фреймворк також знаходить використання у зворотному графіку веб-посилань. Тут Map() дає цільову URL-адресу та джерело та приймає дані з джерела або веб-сторінки.
Далі Reduce() збирає список кожної вихідної URL-адреси, пов’язаної з цільовою URL-адресою. Нарешті, він виводить джерела та ціль.
- Підрахунок слів: MapReduce використовується для підрахунку, скільки разів слово з’являється в певному документі.
- Глобальне потепління: організації, уряди та компанії можуть використовувати MapReduce для вирішення проблем глобального потепління.
Наприклад, ви можете дізнатися про підвищення температури океану через глобальне потепління. Для цього ви можете зібрати тисячі даних по всьому світу. Даними можуть бути висока температура, низька температура, широта, довгота, дата, час тощо. Це займе кілька карт і зменшить кількість завдань для обчислення виходу за допомогою MapReduce.
- Випробування ліків: традиційно науковці та математики працювали разом, щоб розробити новий препарат, який може боротися з хворобою. Завдяки поширенню алгоритмів і MapReduce ІТ-відділи в організаціях можуть легко вирішувати проблеми, які вирішували лише суперкомп’ютери, Ph.D. вчені тощо. Тепер ви можете перевірити ефективність препарату для групи пацієнтів.
- Інші програми: MapReduce може обробляти навіть великомасштабні дані, які інакше не помістяться в реляційну базу даних. Він також використовує інструменти науки про дані та дозволяє запускати їх на різних розподілених наборах даних, що раніше було можливо лише на одному комп’ютері.
Завдяки надійності та простоті MapReduce він знаходить застосування у військовій сфері, бізнесі, науці тощо.
Висновок
MapReduce може виявитися проривом у технології. Це не тільки швидший і простіший процес, але також економічний і менш трудомісткий. Враховуючи його переваги та все більше використання, він, ймовірно, стане свідком більшого впровадження в галузях і організаціях.
Ви також можете ознайомитися з найкращими ресурсами, щоб дізнатися про великі дані та Hadoop.