
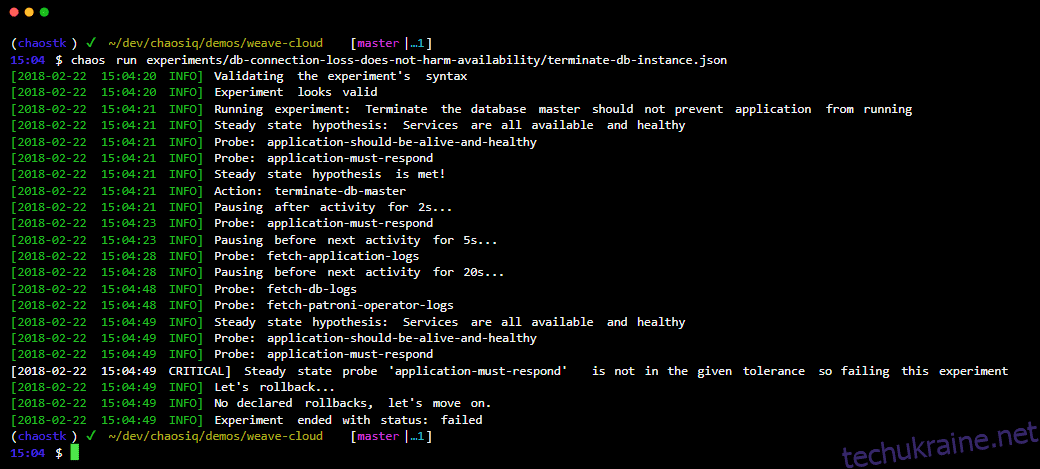
Давайте дізнаємося, як можна зберегти надійність виробництва за допомогою інструментів Chaos Engineering.
Інженерія хаосу — це дисципліна, у якій ви експериментуєте зі своєю системою чи програмою, щоб виявити її слабкі місця та збої в роботі. Це те, про що ви не думали, що може статися під час створення. Таким чином, ви навмисно спричините деякі збої у своїй системі, щоб показати її слабкі сторони, щоб виправити їх і зробити вашу систему та вашу програму більш стійкими.
Багато популярних організацій, як-от Netflix, LinkedIn і Facebook, розробляють хаос, щоб краще зрозуміти архітектуру своїх мікросервісів і розподілених систем. Це допомагає швидше знаходити нові проблеми, ніж реальні скарги користувачів, і вживати необхідних заходів для їх усунення. Саме так ці організації можуть обслуговувати мільйони користувачів, підвищувати їх продуктивність і заощаджувати мільйони доларів 🤑.
Переваги інженерії хаосу:
- Контролюйте втрати доходу, знаходячи критичні проблеми
- Зменшення системних або програмних збоїв
- Краща взаємодія з користувачем із меншими збоями та високою доступністю послуг
- Це допоможе вам дізнатися про систему та набути впевненості.
Наскільки ви впевнені в надійності свого виробництва? Це справді стійке до катастроф?
Давайте дізнаємось за допомогою наведених нижче популярних інструментів тестування хаосу.
Сітка Хаосу
Сітка Хаосу це рішення для управління хаосом, яке вводить помилки в кожен рівень системи Kubernetes. Це включає модулі, мережу, систему вводу-виводу та ядро. Chaos Mesh може автоматично вбивати модулі Kubernetes і імітувати затримки. Це може порушити зв’язок між модулями та імітувати помилки читання/запису. Він може планувати правила для експериментів і визначати їх обсяг. Ці експерименти вказуються за допомогою файлів YAML.
Chaos Mesh має інформаційну панель для перегляду аналітики експериментів. Він працює поверх Kubernetes і підтримує більшість хмарних платформ. Він є відкритим вихідним кодом і нещодавно був прийнятий як проект пісочниці CNCF. Використовуючи принципи розробки хаосу, ви можете додати Chaos Mesh до свого робочого процесу DevOps для створення стійких програм.
Особливості Chaos Engineering:
- Легко розгортається в кластерах Kubernetes без змін у логіці розгортання
- Для розгортання не потрібні унікальні залежності
- Визначає об’єкти хаосу за допомогою CustomResourceDefinitions (CRD)
- Надає інформаційну панель для відстеження всіх експериментів
Набір інструментів хаосу це простий інструмент із відкритим вихідним кодом для Chaos Engineering Experiment Automation.
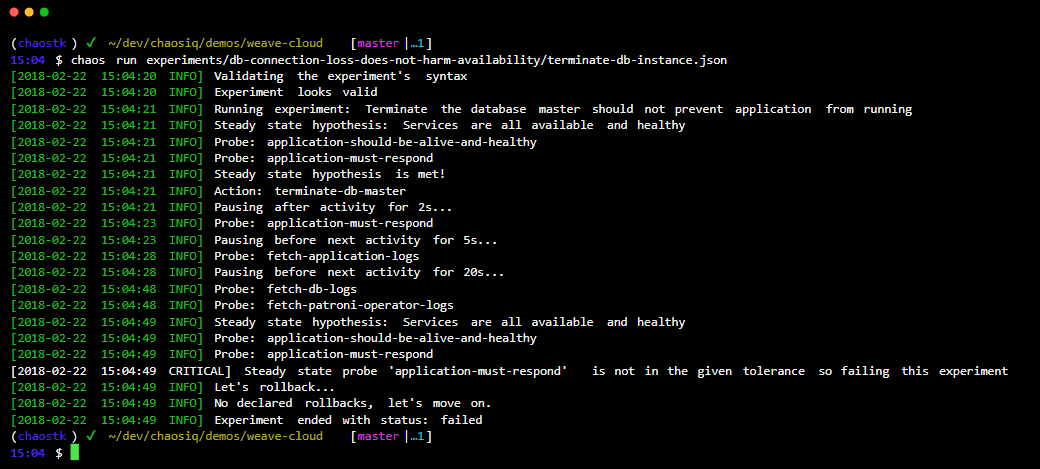
Ви інтегруєте Chaos ToolKit зі своєю системою за допомогою набору драйверів або плагінів, які він підтримує AWS, Google Cloud, Slack, Prometheus тощо.
Особливості Chaos ToolKit:
- Надає декларативний відкритий API для створення експериментів хаосу незалежно від постачальника чи технології
- Може бути легко вбудований у конвеєри CICD для автоматизації
- Надає комерційну та корпоративну підтримку також через ChaosIQ
ChaosKube
Як можна здогадатися з назви, це для Kubernetes.
Чаоскубе це інструмент хаосу з відкритим кодом, який періодично вбиває випадкові модулі в кластері Kubernetes. Це допоможе вам зрозуміти, як ваша система відреагує, коли капсула вийде з ладу. За замовчуванням він знищує модуль у будь-якому просторі імен кожні 10 хвилин. Ви можете фільтрувати цільові модулі в Chaoskube за допомогою просторів імен, міток, анотацій тощо. Його можна легко встановити за допомогою Chaoskube.

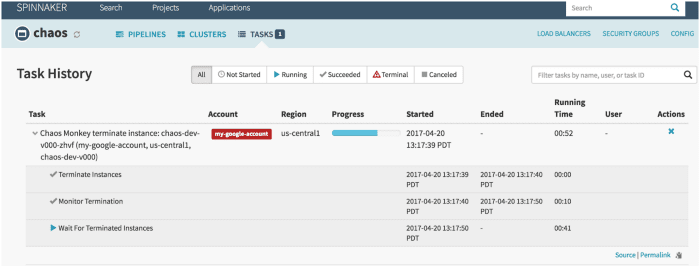
Мавпа Хаосу
Мавпа Хаосу це інструмент, який використовується для перевірки стійкості хмарних систем шляхом навмисного створення збоїв у цих системах, щоб зрозуміти їхню реакцію. Netflix створив його, щоб перевірити стійкість і можливість відновлення інфраструктури AWS. Його назвали Chaos Monkey, тому що він створює руйнування, як дика та озброєна мавпа, щоб перевірити невдачі.
Крім того, саме Chaos Monkey породила нову інженерну практику Chaos Engineering. Він був створений за принципом, що краще зазнавати невдач кілька разів, щоб уникнути будь-якої значної невдачі раптово.
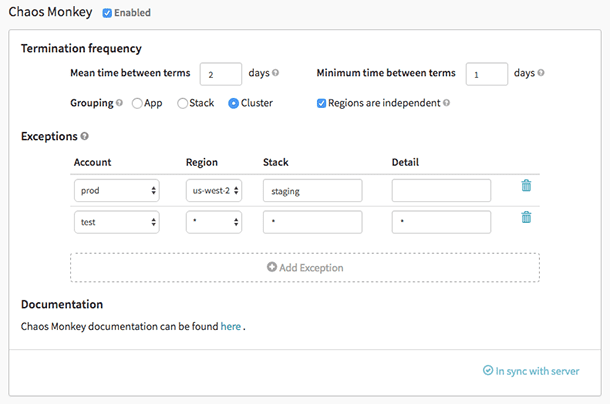
Особливості Chaos Monkey:
- Це допомагає підготуватися до випадкових збоїв екземплярів.
- Заохочує резервування для несподіваних збоїв
- Використовує Spinnaker для забезпечення сумісності між хмарами
- Надає настроюваний розклад для імітації збоїв
- Інтегровано з govendor щоб додати будь-які нові залежності до chaos monkey
Сіммі
Сіммі — це інструмент хаосу для введення помилок, який інтегрується з проектом стійкості Polly для .NET. Це дозволяє вам створювати політики впровадження хаосу через Polly, де ви виконуєте свої коди. Він пропонує різні політики, такі як політика винятків для впровадження винятків у систему, політика поведінки для впровадження будь-якої нової поведінки тощо. Ці політики призначені для випадкового впровадження поведінки.
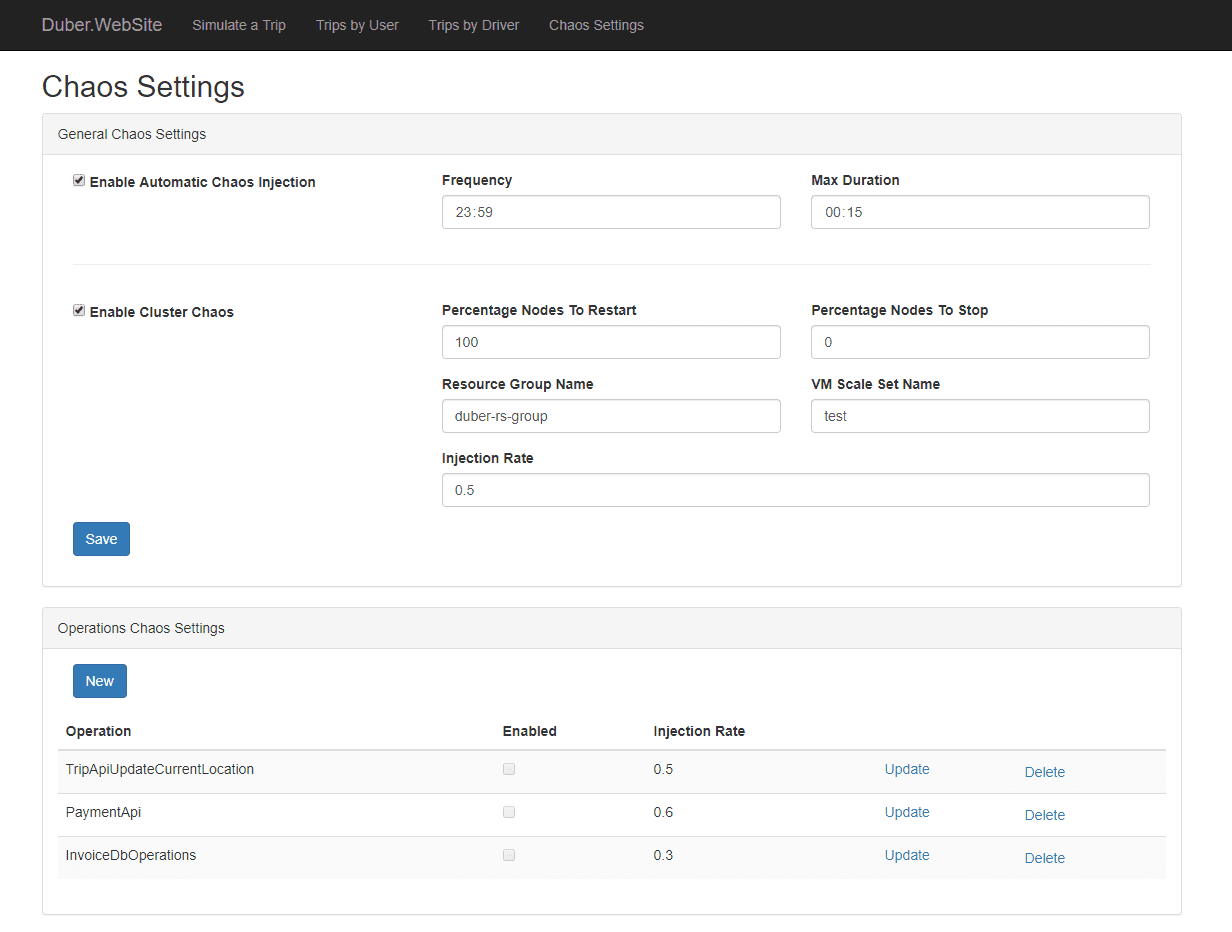
Особливості Simmy:
- Надає політику Мавпи або політику Хаосу для внесення хаосу
- Легко перевірити будь-які помилки залежностей
- Він допомагає швидко повернутися до робочої моделі та контролює радіус вибуху.
- Він готовий до виробництва.
- Він також може визначати збої на основі зовнішніх факторів (наприклад, збої через глобальну конфігурацію)
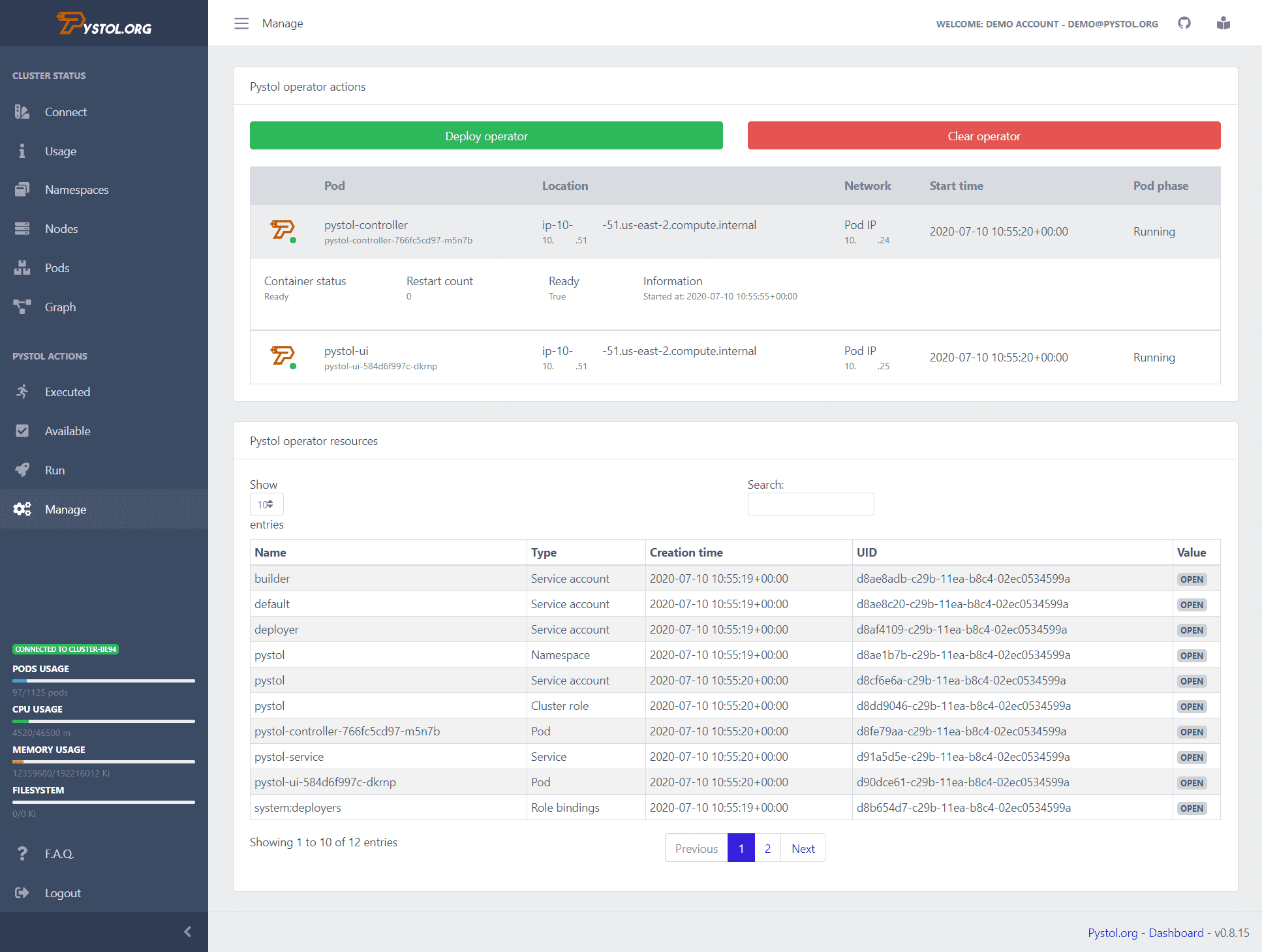
пістолет
пістолет це інструмент, який використовується для введення помилкових ін’єкцій у рідні хмарні середовища. Він спостерігає за подіями в ETCD через операторів Kubernetes. Коли виконується дія ін’єкції помилки, оператори створюють модулі та запускають деякі колекції Ansible. Отже, розробникам не потрібно писати власні дії для виконання.
Pystol надає готові дії для перевірки системи. Проте, якщо розробник хоче створити нову дію, це можна зробити за допомогою GoLang і Python.
Він забезпечує інформаційну панель безперервної інтеграції, щоб надати зведений огляд усіх робочих операцій. Ви можете запустити Pystol локально або розгорнути його в контейнері, використовуючи образ докера. Pystol надає два інтерфейси, один — веб-інтерфейс, а інший — через CLI. Очевидно, веб-інтерфейс є кращим варіантом.
Муксі
Муксі є проксі-сервером для перевірки ваших шаблонів стійкості та відмовостійкості до збоїв розподіленої системи в реальному світі. Він може втручатися в транспортний рівень (рівень 4), рівень сеансу TCP (рівень 5) і рівень протоколу HTTP (рівень 7).
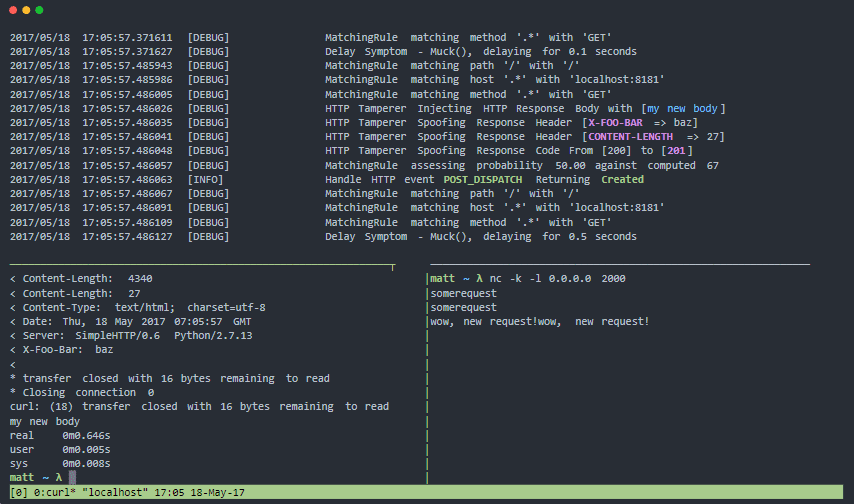
Особливості Muxy:
- Модульна архітектура, яка легко розширюється
- Має офіційний докер-контейнер
- Легко встановити, не потрібні залежності.
- Ідеально підходить для постійного тестування на стійкість
- Імітує проблеми з підключенням до мережі для розподілених систем і мобільних пристроїв
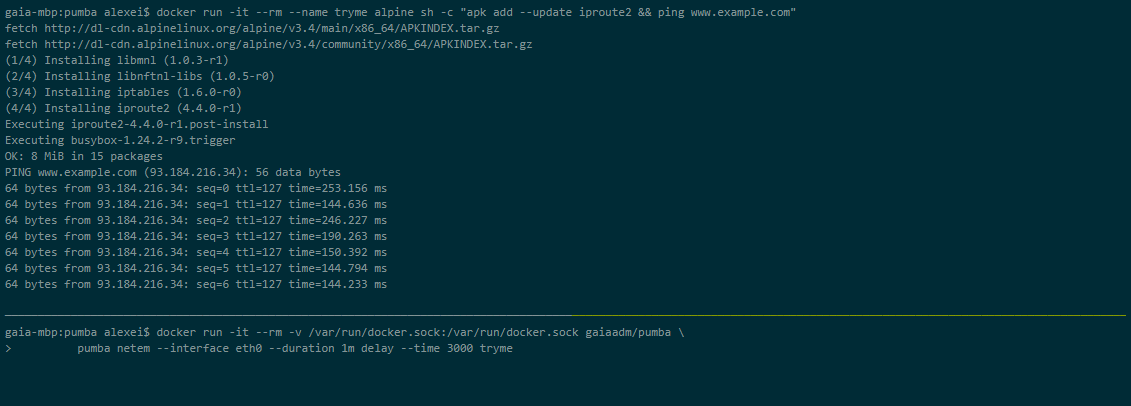
Пумба
Пумба це інструмент командного рядка, який виконує тестування хаосу для контейнерів докерів. За допомогою Pumba ви навмисно руйнуєте докер-контейнери програми, щоб побачити, як система відреагує. Ви також можете провести стрес-тестування ресурсів контейнера, таких як ЦП, пам’ять, файлова система, введення/виведення тощо.
Ви також можете запустити Pumba на кластері Kubernetes. Ви повинні використовувати DaemonSets, щоб розгорнути Pumba на вузлах Kubernetes. Ви можете використовувати кілька контейнерів Pumba для запуску кількох команд Pumba в одному DaemonSet.
ChaosBlade
ChaosBlade це інструмент із відкритим кодом для впровадження експериментів у системи від Alibaba. Він перевіряє всі збої, з якими зіткнулася Alibaba за останні десять років, і застосовує найкращі методи, щоб їх уникнути. Він дотримується принципів інженерії хаосу для перевірки відмовостійкості розподілених систем.
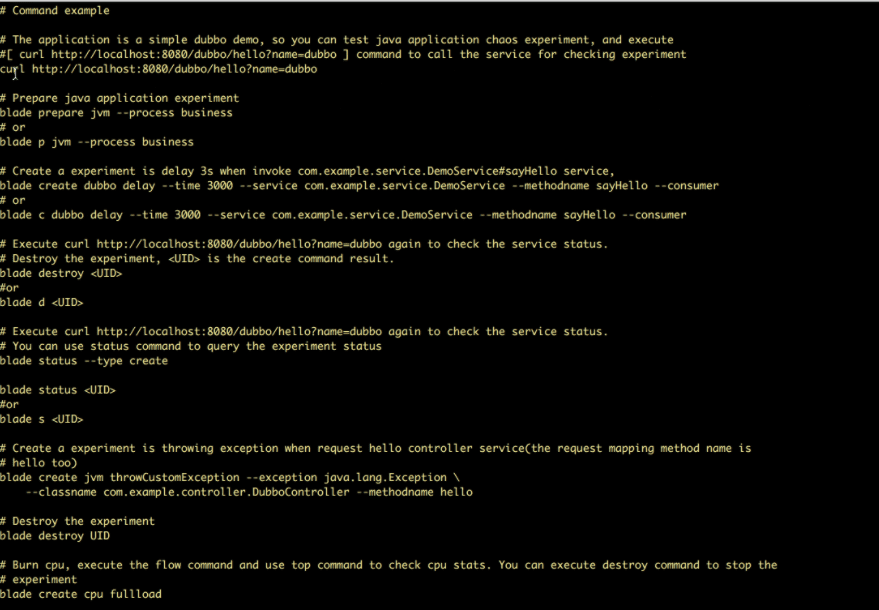
Особливості ChaosBlade:
- Надає експериментальні сценарії для кількох ресурсів, таких як ЦП, мережа, пам’ять, диск тощо.
- Надає експериментальні сценарії для вузлів, мереж і модулів на платформі Kubernetes
- Надає прості у використанні команди CLI для виконання експериментів
Лакмус
Лакмус дотримується принципів інженерії хаосу в хмарі. Місія інструменту «лакмус» — надати повну структуру для пошуку слабких місць у ваших системах Kubernetes і запущених програмах у Kubernetes.
Він має оператор хаосу та CRD (CustomResourceDefinitions) навколо нього, що забезпечує можливість підключення та роботи. Це все про те, щоб помістити вашу логіку хаосу в образ докера, кинути його в лакмусову структуру та отримати їх оркестровку за допомогою CRD.

Особливості Litmus:
- Допомагає інженерам і розробникам Site Reliability знаходити слабкі місця в системі Kubernetes
- Надає готові до використання загальні експерименти
- Надає Chaos API для керування робочим процесом хаосу
- Litmus SDK підтримує Go, Python і Ansible для створення власних експериментів.
Гремлін
Гремлін допомагає інженерам створювати більш стійке програмне забезпечення. Він надає платформу для безпечного, безпечного та простого проведення експериментів з розробки хаосу.

Ви можете продумано впроваджувати помилки в хости чи контейнери за допомогою gremlin, незалежно від того, де вони знаходяться, чи то публічна хмара, чи ваш власний центр обробки даних.
Особливості Gremlin:
- Встановлює легкий агент на ваші хости або контейнери для впровадження помилок
- Забезпечує 10+ різних режимів атаки на інфраструктуру
- Гремліни стану дозволяють маніпулювати системним часом, вимикати чи перезапускати хости та вбивати процесори.
- Мережеві гремліни можуть вводити затримку, щоб спричинити втрату пакетів або втрати трафіку.
- Атаки на бібліотеку Alfi від Gremlin можна налаштовувати, запускати та зупиняти через веб-програму. API або CLI
- Дозволяє вам точно націлити радіус вибуху, який ви хочете атакувати
- Дозволяє зупинити всі атаки та повернути систему до стабільного стану
Steadybit
Steadybit націлений на завчасне скорочення часу простою та забезпечує видимість системних проблем. Ви можете запустити цей інструмент локально у своїй інфраструктурі або хмарі як послуга (SaaS).
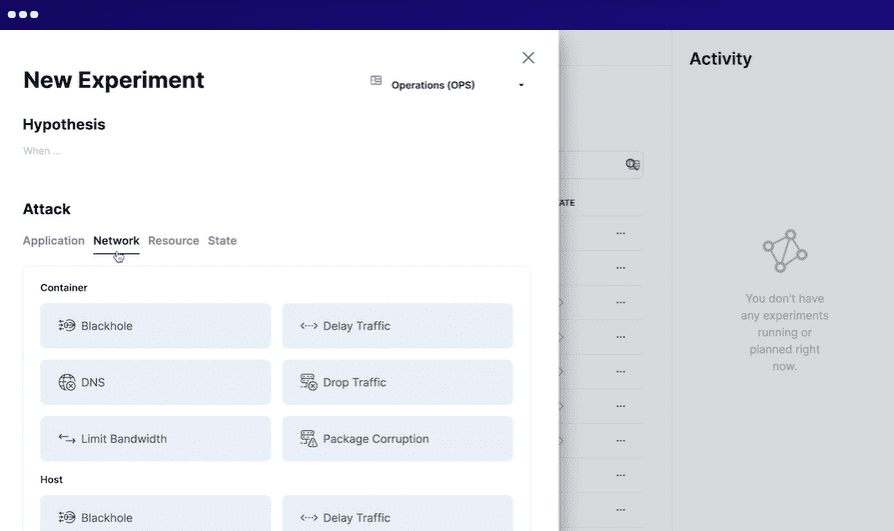
Щоб використовувати Steadybit, ви визначаєте ситуацію, симулюєте експерименти, виконуєте змодельовані експерименти на виробництві та автоматизуєте всі експерименти. Він запускає інтелектуальні агенти у вашій системі для виявлення потенційних проблем і слабких місць. Він легко інтегрується з кількома системами.
Висновок
Будьте досить сміливими, щоб застосувати принципи інженерії хаосу та перевірити своє виробництво за допомогою вищезгаданих інструментів. Ці інструменти допоможуть вам знайти численні невизначені слабкі місця у вашій системі та допоможуть зробити вашу систему більш стійкою.