
Веб-збирання — це ідея вилучення інформації з веб-сайту та використання її для конкретного випадку використання.
Припустімо, ви намагаєтеся видобути таблицю з веб-сторінки, перетворити її на файл JSON і використовувати файл JSON для створення деяких внутрішніх інструментів. За допомогою веб-збирання ви можете отримувати потрібні дані, націлюючись на певні елементи веб-сторінки. Веб-збирання за допомогою Python є дуже популярним вибором, оскільки Python надає кілька бібліотек, як-от BeautifulSoup або Scrapy, для ефективного вилучення даних.
Вміння ефективно видобувати дані також дуже важливо для розробника чи дослідника даних. Ця стаття допоможе вам зрозуміти, як ефективно очищати веб-сайт і отримати необхідний вміст для маніпулювання ним відповідно до ваших потреб. У цьому посібнику ми будемо використовувати пакет BeautifulSoup. Це модний пакет для збирання даних у Python.
Навіщо використовувати Python для веб-збирання?
Python є першим вибором для багатьох розробників під час створення веб-скребків. Є багато причин, чому Python є першим вибором, але для цієї статті давайте обговоримо три основні причини, чому Python використовується для збирання даних.
Підтримка бібліотеки та спільноти: є кілька чудових бібліотек, як-от BeautifulSoup, Scrapy, Selenium тощо, які надають чудові функції для ефективного сканування веб-сторінок. Він створив чудову екосистему для веб-скрапінгу, а також оскільки багато розробників у всьому світі вже використовують Python, ви можете швидко отримати допомогу, коли ви застрягли.
Автоматизація: Python відомий своїми можливостями автоматизації. Якщо ви намагаєтеся створити складний інструмент, який покладається на скрапінг, потрібне більше, ніж веб-скрапінг. Наприклад, якщо ви хочете створити інструмент, який відстежує ціни на товари в онлайн-магазині, вам потрібно буде додати деяку можливість автоматизації, щоб він міг щоденно відстежувати ціни та додавати їх до вашої бази даних. Python дає вам можливість легко автоматизувати такі процеси.
Візуалізація даних: веб-скрейпінг широко використовується спеціалістами з обробки даних. Науковцям з даних часто доводиться отримувати дані з веб-сторінок. Завдяки таким бібліотекам, як Pandas, Python спрощує візуалізацію даних із вихідних даних.
Бібліотеки для веб-скрейпінгу в Python
У Python доступно кілька бібліотек для спрощення веб-збирання. Давайте обговоримо тут три найпопулярніші бібліотеки.
#1. BeautifulSoup
Одна з найпопулярніших бібліотек для веб-збирання. BeautifulSoup допомагає розробникам чистити веб-сторінки з 2004 року. Він надає прості методи для навігації, пошуку та зміни дерева аналізу. Beautifulsoup також виконує кодування вхідних і вихідних даних. Він доглянутий і має чудову спільноту.
#2. Скрепі
Ще один популярний фреймворк для вилучення даних. Scrapy має понад 43 000 зірок на GitHub. Його також можна використовувати для збирання даних з API. Він також має кілька цікавих вбудованих засобів підтримки, як-от надсилання електронних листів.
#3. Селен
Selenium — це не здебільшого бібліотека веб-збирання. Натомість це пакет автоматизації браузера. Але ми можемо легко розширити його функції для копіювання веб-сторінок. Він використовує протокол WebDriver для керування різними браузерами. Селен існує на ринку вже майже 20 років. Але за допомогою Selenium ви можете легко автоматизувати та знімати дані з веб-сторінок.
Проблеми з Python Web Scraping
Під час спроби отримати дані з веб-сайтів можна зіткнутися з багатьма проблемами. Існують такі проблеми, як повільні мережі, інструменти для захисту від сканування, блокування на основі IP-адреси, блокування captcha тощо. Ці проблеми можуть спричинити значні проблеми під час спроби сканувати веб-сайт.
Але ви можете ефективно обійти труднощі, дотримуючись деяких способів. Наприклад, у більшості випадків IP-адреса блокується веб-сайтом, коли за певний проміжок часу надсилається більше певної кількості запитів. Щоб уникнути блокування IP-адреси, вам потрібно закодувати свій скрепер, щоб він охолоджувався після надсилання запитів.

Розробники також прагнуть поставити пастки-приманки для скребків. Ці пастки зазвичай невидимі голим людським оком, але їх можна пролізти за допомогою скребка. Якщо ви збираєте веб-сайт, який розміщує таку пастку-приманку, вам потрібно буде відповідним чином закодувати свій скребок.
Captcha є ще однією серйозною проблемою скребків. Більшість сучасних веб-сайтів використовують captcha для захисту доступу ботів до своїх сторінок. У такому випадку вам може знадобитися розв’язувач captcha.
Скрапінг веб-сайту за допомогою Python
Як ми вже обговорювали, ми будемо використовувати BeautifulSoup, щоб скасувати веб-сайт. У цьому підручнику ми збиратимемо історичні дані Ethereum із Coingecko та збережемо дані таблиці як файл JSON. Переходимо до побудови скребка.
Першим кроком є встановлення BeautifulSoup і Requests. Для цього підручника я буду використовувати Pipenv. Pipenv — це менеджер віртуального середовища для Python. Ви також можете використовувати Venv, якщо хочете, але я віддаю перевагу Pipenv. Обговорення Pipenv виходить за рамки цього посібника. Але якщо ви хочете дізнатися, як можна використовувати Pipenv, дотримуйтеся цього посібника. Або, якщо ви хочете зрозуміти віртуальні середовища Python, дотримуйтеся цього посібника.
Запустіть оболонку Pipenv у каталозі проекту, виконавши команду оболонки pipenv. Він запустить підоболонку у вашому віртуальному середовищі. Тепер, щоб встановити BeautifulSoup, виконайте таку команду:
pipenv install beautifulsoup4
А для встановлення запитів виконайте команду, подібну до наведеної вище:
pipenv install requests
Після завершення інсталяції імпортуйте необхідні пакети в головний файл. Створіть файл під назвою main.py та імпортуйте пакети, як показано нижче:
from bs4 import BeautifulSoup import requests import json
Наступний крок — отримати вміст сторінки історичних даних і проаналізувати його за допомогою аналізатора HTML, доступного в BeautifulSoup.
r = requests.get('https://www.coingecko.com/en/coins/ethereum/historical_data#panel')
soup = BeautifulSoup(r.content, 'html.parser')
У наведеному вище коді доступ до сторінки здійснюється за допомогою методу get, доступного в бібліотеці запитів. Проаналізований вміст потім зберігається в змінній під назвою soup.
Початкова частина вишкрібання починається зараз. По-перше, вам потрібно буде правильно визначити таблицю в DOM. Якщо ви відкриєте цю сторінку та перевірите її за допомогою інструментів розробника, доступних у браузері, ви побачите, що таблиця містить такі класи table table-striped text-sm text-lg-normal.
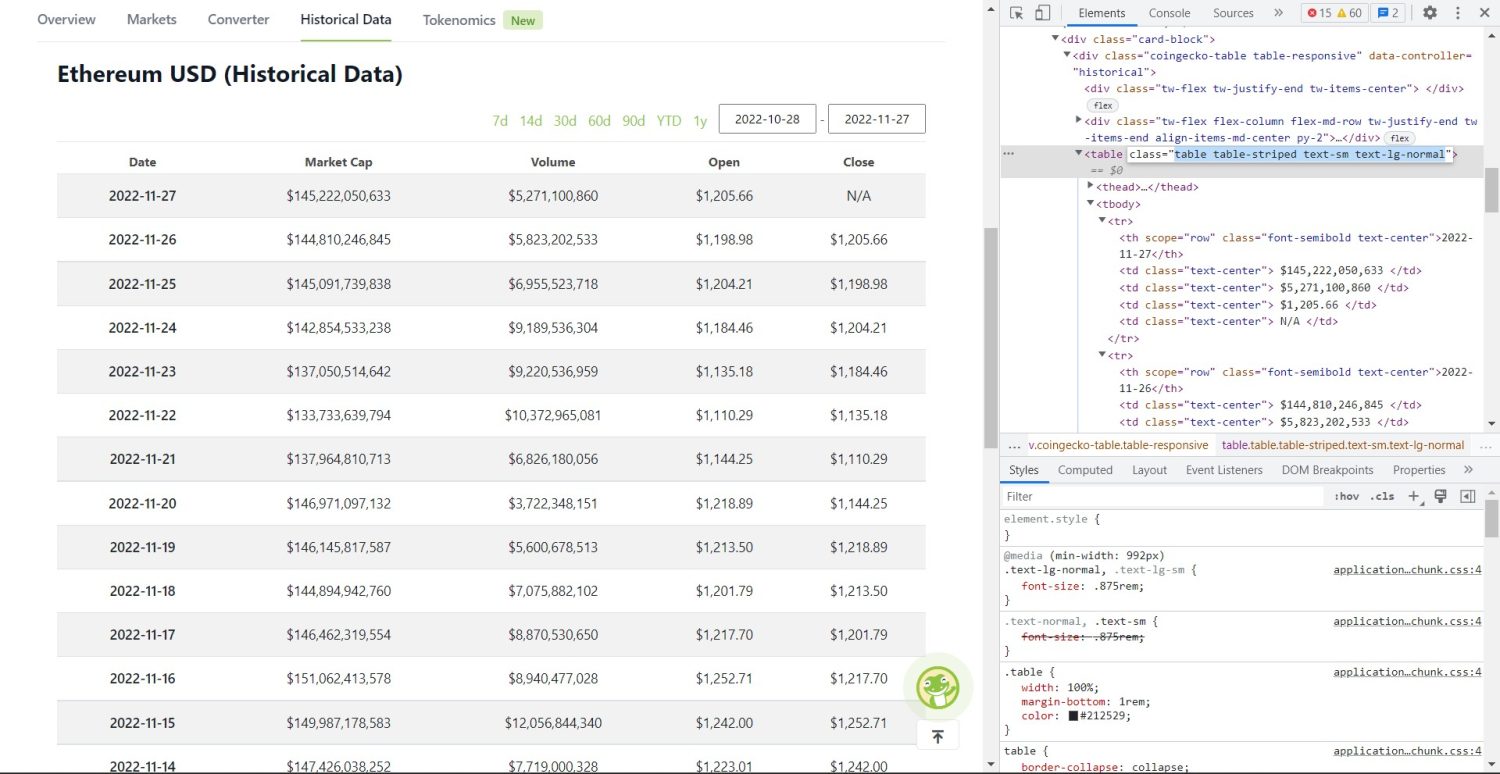 Таблиця історичних даних Coingecko Ethereum
Таблиця історичних даних Coingecko Ethereum
Щоб правильно націлити цю таблицю, ви можете використовувати метод find.
table = soup.find('table', attrs={'class': 'table table-striped text-sm text-lg-normal'})
table_data = table.find_all('tr')
table_headings = []
for th in table_data[0].find_all('th'):
table_headings.append(th.text)
У наведеному вище коді спочатку таблиця знаходиться за допомогою методу soup.find, а потім за допомогою методу find_all виконується пошук усіх елементів tr всередині таблиці. Ці елементи tr зберігаються в змінній під назвою table_data. Таблиця має декілька елементів для заголовка. Нова змінна під назвою table_headings ініціалізується для збереження заголовків у списку.
Потім для першого рядка таблиці запускається цикл for. У цьому рядку шукаються всі елементи з th, а їх текстове значення додається до списку table_headings. Текст виділяється текстовим методом. Якщо ви надрукуєте змінну table_headings зараз, ви зможете побачити такі результати:
['Date', 'Market Cap', 'Volume', 'Open', 'Close']
Наступним кроком є очищення решти елементів, створення словника для кожного рядка, а потім додавання рядків у список.
for tr in table_data:
th = tr.find_all('th')
td = tr.find_all('td')
data = {}
for i in range(len(td)):
data.update({table_headings[0]: th[0].text})
data.update({table_headings[i+1]: td[i].text.replace('n', '')})
if data.__len__() > 0:
table_details.append(data)
Це суттєва частина коду. Для кожного tr у змінній table_data спочатку виконується пошук елементів th. Елементи – дата, показана в таблиці. Ці елементи th зберігаються всередині змінної th. Подібним чином усі елементи td зберігаються у змінній td.
Ініціалізуються порожні дані словника. Після ініціалізації ми проходимо цикл по діапазону елементів td. Для кожного рядка спочатку ми оновлюємо перше поле словника першим елементом th. Код table_headings[0]: тис[0].text призначає пару ключ-значення дати та першого елемента.
Після ініціалізації першого елемента інші елементи призначаються за допомогою data.update({table_headings[i+1]: тд[i].text.replace(‘n’, ”)}). Тут спочатку текст елементів td витягується за допомогою методу text, а потім усі n замінюються за допомогою методу replace. Потім значення присвоюється i+1-му елементу списку table_headings, оскільки i-й елемент уже призначено.
Потім, якщо довжина словника даних перевищує нуль, ми додаємо словник до списку table_details. Ви можете надрукувати список table_details для перевірки. Але ми запишемо значення у файл JSON. Давайте подивимося на код для цього,
with open('table.json', 'w') as f:
json.dump(table_details, f, indent=2)
print('Data saved to json file...')
Тут ми використовуємо метод json.dump для запису значень у файл JSON під назвою table.json. Після завершення запису ми друкуємо дані, збережені у файл json… на консолі.
Тепер запустіть файл за допомогою такої команди,
python run main.py
Через деякий час ви зможете побачити на консолі текст Дані, збережені у файл JSON…. Ви також побачите новий файл під назвою table.json у каталозі робочих файлів. Файл виглядатиме подібно до наступного файлу JSON:
[
{
"Date": "2022-11-27",
"Market Cap": "$145,222,050,633",
"Volume": "$5,271,100,860",
"Open": "$1,205.66",
"Close": "N/A"
},
{
"Date": "2022-11-26",
"Market Cap": "$144,810,246,845",
"Volume": "$5,823,202,533",
"Open": "$1,198.98",
"Close": "$1,205.66"
},
{
"Date": "2022-11-25",
"Market Cap": "$145,091,739,838",
"Volume": "$6,955,523,718",
"Open": "$1,204.21",
"Close": "$1,198.98"
},
// ...
// ...
]
Ви успішно реалізували веб-скребок за допомогою Python. Щоб переглянути повний код, ви можете відвідати це сховище GitHub.
Висновок
У цій статті обговорювалося, як можна реалізувати просте сканування Python. Ми обговорювали, як можна використовувати BeautifulSoup для швидкого збирання даних із веб-сайту. Ми також обговорили інші доступні бібліотеки та чому Python є першим вибором для багатьох розробників для копіювання веб-сайтів.
Ви також можете переглянути ці фреймворки веб-збирання.