Веб-скрейпінг: потужний інструмент для збору даних
Веб-скрейпінг є ефективним методом вилучення великих обсягів інформації з
інтернету. Він стає особливо корисним у ситуаціях, коли веб-ресурси не
надають дані у структурованому вигляді через API (інтерфейси прикладного
програмування).
Розглянемо приклад: ви розробляєте додаток для порівняння цін на товари в
інтернет-магазинах. Як би ви підійшли до цього завдання? Один з підходів –
ручний моніторинг цін на всіх вебсайтах і фіксація результатів. Проте, цей
метод є неефективним, враховуючи тисячі товарів на платформах електронної
комерції, що вимагатиме багато часу для збору даних.
Оптимальний розв’язок – застосування веб-скрейпінгу. Це процес автоматизованого
видобування даних з веб-сторінок та веб-сайтів за допомогою спеціалізованого
програмного забезпечення.
Програмні скрипти, відомі як веб-скрепери, отримують доступ до веб-ресурсів і
видобувають необхідні дані. Отримані дані, зазвичай представлені у
неструктурованому форматі, згодом аналізуються і зберігаються у зручній для
користувача структурованій формі.
Веб-скрейпінг є надзвичайно цінним для вилучення даних, оскільки він забезпечує
доступ до великих обсягів інформації та автоматизує процеси. Завдяки цьому,
можливо налаштувати запуск скриптів веб-скрейпінгу за розкладом або у відповідь
на певні події. Крім того, веб-скрейпінг дозволяє отримувати оновлення в
режимі реального часу та спрощує проведення маркетингових досліджень.

Безліч підприємств та організацій покладаються на веб-скрейпінг для збору
даних з метою їх подальшого аналізу. Компанії, що спеціалізуються на
кадрових ресурсах, електронній комерції, фінансах, нерухомості, туризмі,
соціальних мережах та дослідженнях, активно використовують веб-скрейпінг для
отримання необхідної інформації.
Навіть пошукова система Google використовує веб-скрейпінг для індексації
веб-сайтів, що дозволяє надавати користувачам релевантні результати пошуку.
Важливо пам’ятати про обережність при використанні веб-скрейпінгу. Хоча
видобування загальнодоступних даних не є протизаконним, деякі веб-ресурси
забороняють цей процес. Це може бути зумовлено захистом конфіденційної
інформації користувачів, прямими заборонами в умовах використання, або
захистом інтелектуальної власності.
Крім того, деякі веб-сайти обмежують веб-скрейпінг, оскільки це може перевантажити
сервер і призвести до збільшення витрат на пропускну здатність, особливо при
масштабному використанні.
Для перевірки можливості збору даних з веб-сайту, додайте robots.txt до його
адреси. Файл robots.txt вказує роботам, які частини веб-ресурсу можна
сканувати. Наприклад, для перевірки можливості сканування Google, перейдіть
на сторінку google.com/robots.txt.
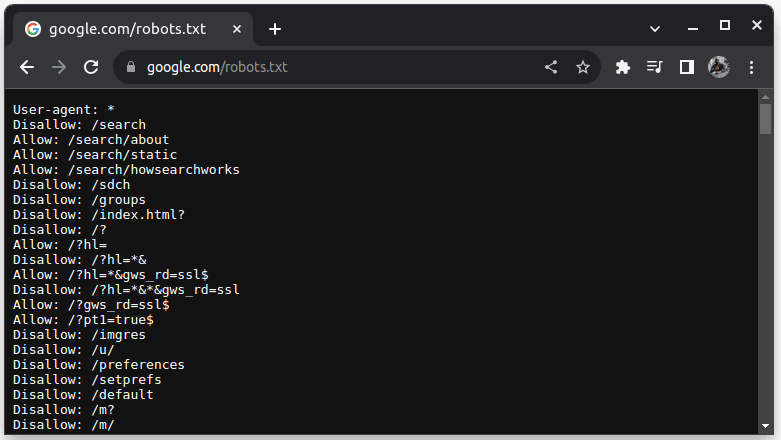
“User-agent: *” позначає всіх ботів, програмні скрипти та сканери. “Disallow”
повідомляє ботам про заборону доступу до певних URL-адрес, наприклад /search.
“Allow” вказує дозволені для доступу каталоги.
Прикладом веб-сайту, який забороняє веб-скрейпінг, є LinkedIn. Для перевірки
можливості сканування LinkedIn, перейдіть на сторінку
linkedin.com/robots.txt.
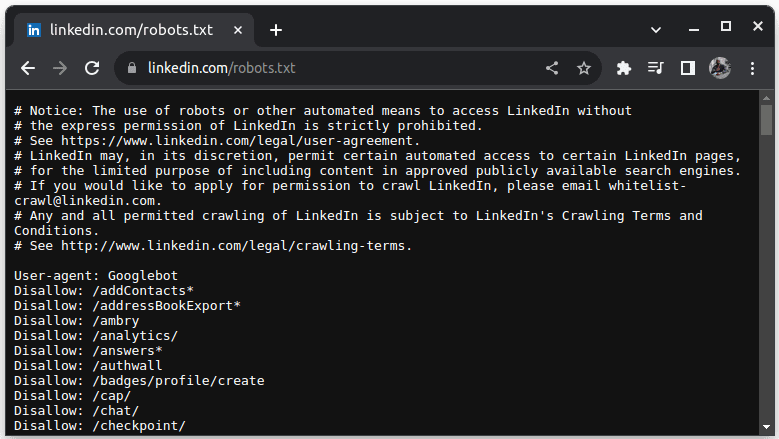
Як бачимо, збір даних з LinkedIn без дозволу заборонено. Завжди перевіряйте
можливість веб-скрейпінгу, щоб уникнути юридичних проблем.
Чому Java підходить для веб-скрейпінгу?
Хоча веб-скрепери можна розробляти на різних мовах програмування, Java є
особливо вдалим вибором з кількох причин. По-перше, Java має велику
екосистему та активну спільноту, а також надає різноманітні бібліотеки для
веб-скрейпінгу, такі як JSoup, WebMagic та HTMLUnit, що спрощує процес
розробки.

Java також пропонує бібліотеки для парсингу HTML, що полегшує вилучення даних
з HTML-документів, а також мережеві бібліотеки, такі як HttpURLConnection, для
надсилання запитів до різних URL-адрес веб-сайтів.
Потужна підтримка паралелізму та багатопоточності в Java корисна для
веб-скрейпінгу, оскільки дозволяє обробляти завдання паралельно,
виконуючи кілька запитів одночасно. Завдяки високій масштабованості Java, ви
можете ефективно обробляти веб-сайти великого масштабу за допомогою
веб-скрепера на Java.
Крос-платформна сумісність Java також є перевагою, оскільки дозволяє розробляти
веб-скрепер і запускати його в будь-якій системі з сумісною віртуальною
машиною Java. Таким чином, ви можете створити веб-скрепер в одній
операційній системі та використовувати його в іншій без необхідності змін.
Java також можна використовувати з безголовими браузерами, такими як Headless
Chrome, HTML Unit, Headless Firefox та PhantomJs. Безголовий браузер – це
браузер без графічного інтерфейсу користувача. Ці браузери можуть
імітувати взаємодію з користувачем та є корисними при скануванні веб-сайтів,
які потребують такої взаємодії.
Крім того, Java є популярною мовою програмування, яка підтримується та легко
інтегрується з різними інструментами, такими як бази даних та інфраструктури
обробки даних. Це гарантує підтримку Java в інструментах, необхідних для
збору, обробки та зберігання даних.
Далі розглянемо, як використовувати Java для веб-скрейпінгу.
Java для веб-скрейпінгу: необхідні умови
Для використання Java у веб-скрейпінгу, необхідно виконати наступні
передумови:
1. Java – повинна бути встановлена Java, бажано останньої версії з довгостроковою
підтримкою. Якщо Java не встановлена, ознайомтеся з інструкціями щодо
інсталяції Java на вашому комп’ютері.
2. Інтегроване середовище розробки (IDE) – на вашому комп’ютері має бути
встановлено IDE. У цьому посібнику ми будемо використовувати IntelliJ IDEA,
але ви можете використовувати будь-яку IDE.
3. Maven – використовуватиметься для управління залежностями та встановлення
бібліотеки веб-скрейпінгу.
Якщо у вас не встановлений Maven, ви можете встановити його через термінал
командою:
sudo apt install maven
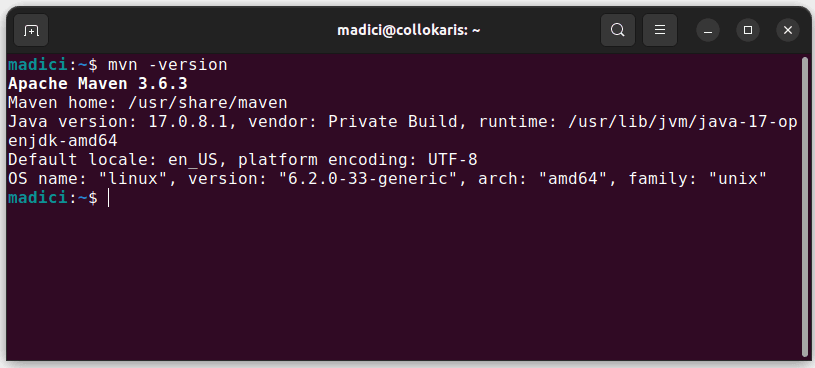
Це встановить Maven з офіційного репозиторію. Перевірте встановлення,
виконавши:
mvn -version
При успішній інсталяції ви отримаєте результат:
Налаштування середовища
Для налаштування середовища:
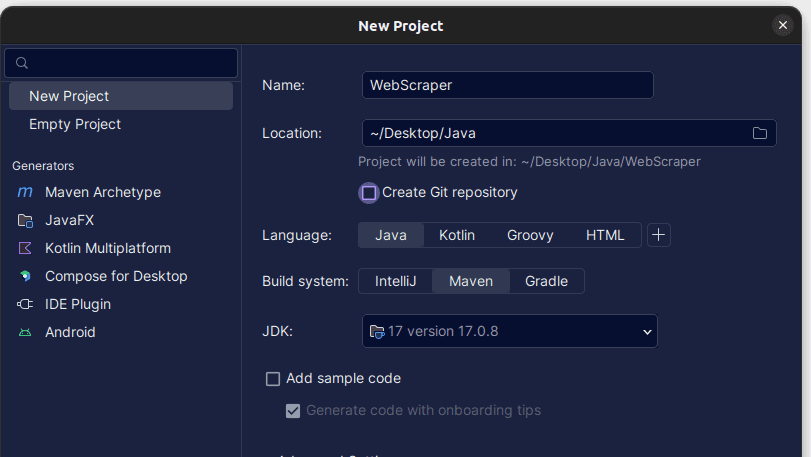
1. Відкрийте IntelliJ IDEA. На панелі меню зліва натисніть “Projects”, а потім
виберіть “New Project”.
2. У вікні “New Project”, що відкриється, заповніть необхідні поля, як
показано нижче. Встановіть “Java” для “Language” та “Maven” для “Build system”.
Ви можете назвати проект будь-як і вказати папку для його збереження.
Натисніть “Create”.
3. Після створення проєкту, у вас має бути файл pom.xml, як показано нижче.
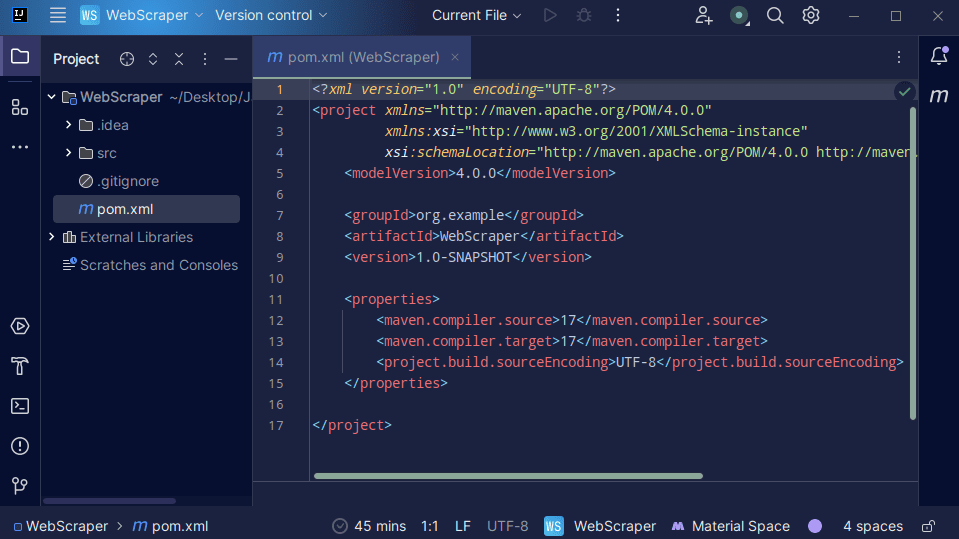
Файл pom.xml створюється Maven та містить інформацію про проєкт та деталі
конфігурації, що використовуються Maven для створення проєкту. Ми
використовуємо цей файл для визначення зовнішніх бібліотек.
Для створення веб-скрепера ми будемо використовувати бібліотеку jsoup. Тому
додамо її як залежність у файл pom.xml, щоб Maven зробив її доступною для
проєкту.
4. Додайте залежність jsoup у файл pom.xml, скопіювавши наведений нижче код і
вставивши його у свій файл pom.xml.
<dependencies>
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.16.1</version>
</dependency>
</dependencies>
Результат має виглядати так:
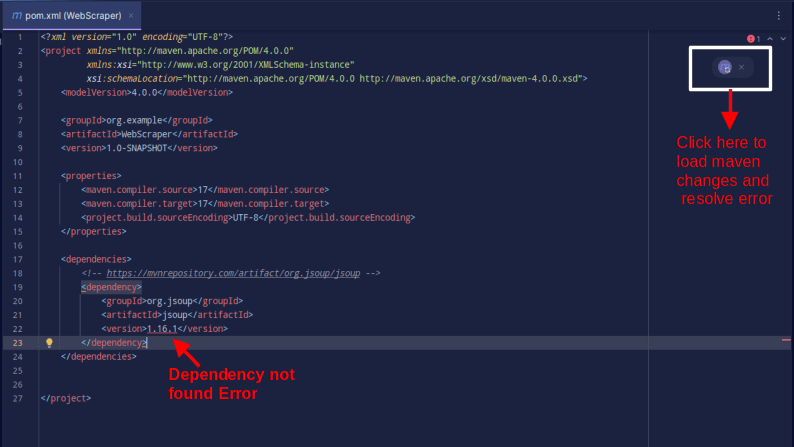
Якщо ви зіткнулися з помилкою про те, що залежність не знайдено, натисніть
відповідну іконку, щоб Maven завантажив внесені зміни, завантажив залежність і
усунув помилку.
На цьому ваше середовище повністю готове до роботи.
Веб-скрейпінг з використанням Java
Для веб-скрейпінгу ми будемо використовувати дані з веб-сайту
ScrapeThisSite, який пропонує пісочницю для практики веб-скрейпінгу без юридичних
проблем.
Для завантаження веб-сайту за допомогою Java:
1. На панелі меню зліва в IntelliJ відкрийте каталог src, а потім основний
каталог. Основний каталог містить каталог під назвою java. Клацніть його
правою кнопкою миші та виберіть “New”, а потім “Java Class”.
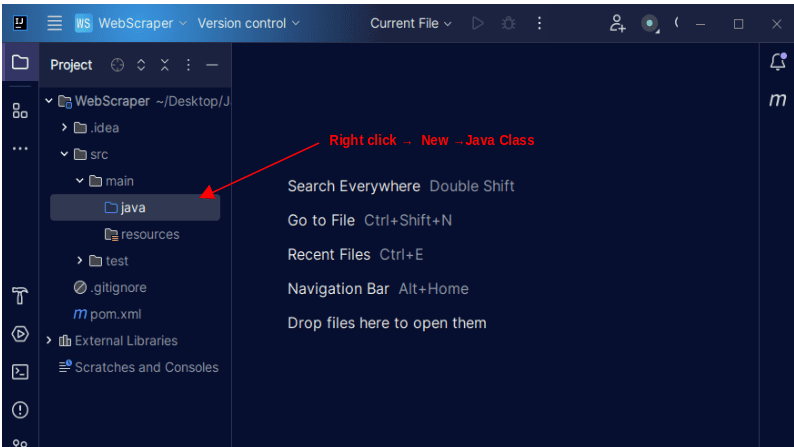
Назвіть клас, наприклад, WebScraper, та натисніть Enter для створення нового
класу Java.
Відкрийте створений файл Java.
2. Веб-скрейпінг передбачає вилучення даних з веб-сайтів. Тому потрібно
вказати URL-адресу, з якої потрібно отримати дані. Після зазначення
URL-адреси, потрібно підключитися до неї та зробити GET запит для
отримання вмісту HTML сторінки.
Код, який це робить, показано нижче:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import java.io.IOException;
public class WebScraper {
public static void main(String[] args) {
String url = "https://www.scrapethissite.com/pages/simple/";
try {
Document doc = Jsoup.connect(url).get();
System.out.println(doc);
} catch (IOException e) {
System.out.println("An IOException occurred. Please try again.");
}
}
}
Вихід:
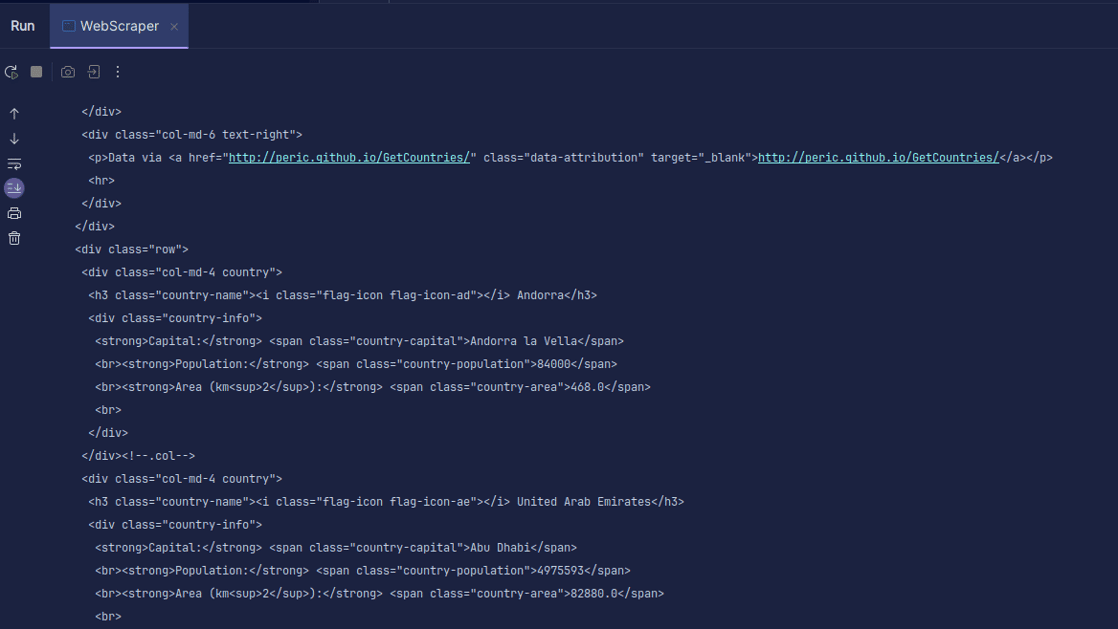
Як бачимо, повертається HTML сторінки. При скануванні URL-адреса може містити
помилку, а ресурс, який ви намагаєтеся отримати, може не існувати. Ось чому
важливо використовувати оператор try-catch.
Рядок:
Document doc = Jsoup.connect(url).get();
використовується для підключення до URL-адреси. Метод get() виконує GET запит
та отримує HTML сторінки. Результат зберігається в об’єкті JSOUP Document під
назвою doc. Зберігання результату в документі JSOUP дозволяє використовувати
JSOUP API для маніпулювання HTML.
3. Перейдіть на
ScrapeThisSite
та перевірте сторінку. У HTML ви повинні побачити наступну структуру:
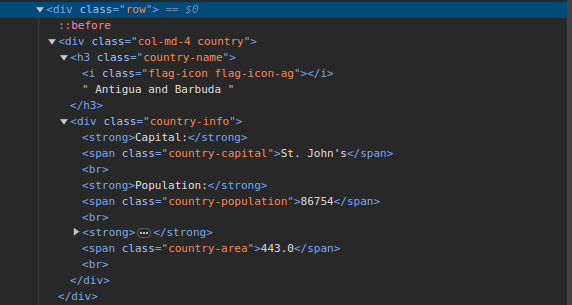
Зверніть увагу, що всі країни на сторінці зберігаються в однаковій структурі. Є
div з класом country, а в ньому h3 з класом country-name, що містить назву
країни.
Усередині основного div є ще один div з класом country-info, який містить
інформацію про столицю, населення та площу країни. Ми можемо використовувати
ці назви класів, щоб вибрати елементи HTML та отримати з них інформацію.
4. Витягніть потрібний вміст з HTML сторінки, використовуючи наступні рядки
коду:
Elements countries = doc.select(".country");
for (Element country : countries) {
String countryName = country.select(".country-name").text();
String capitalCity = country.select(".country-capital").text();
String population = country.select(".country-population").text();
System.out.println(countryName + " - " + capitalCity + " Population - " + population);
}
Ми використовуємо метод select() для вибору елементів з HTML сторінки, які
відповідають селектору CSS. В нашому випадку ми передаємо імена класів.
Перевіривши сторінку, ми побачили, що вся інформація про країну зберігається в
div з класом country.
Кожна країна має власний div з класом country, і він містить таку інформацію,
як назва країни, столиця та населення.
Тому ми спочатку вибираємо всі країни на сторінці за допомогою класу .country.
Потім ми зберігаємо це в змінній під назвою “countries” типу Elements, яка
працює як список. Потім ми використовуємо цикл for для проходу по країнах і
вилучення назви країни, столиці та населення.
Весь код нашого веб-скрепера виглядає так:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import org.jsoup.nodes.Element;
import java.io.IOException;
public class WebScraper {
public static void main(String[] args) {
String url = "https://www.scrapethissite.com/pages/simple/";
try {
Document doc = Jsoup.connect(url).get();
Elements countries = doc.select(".country");
for (Element country : countries) {
String countryName = country.select(".country-name").text();
String capitalCity = country.select(".country-capital").text();
String population = country.select(".country-population").text();
System.out.println(countryName + " - " + capitalCity + " - Population - " + population);
}
} catch (IOException e) {
System.out.println("An IOException occurred. Please try again.");
}
}
}
Вихід:
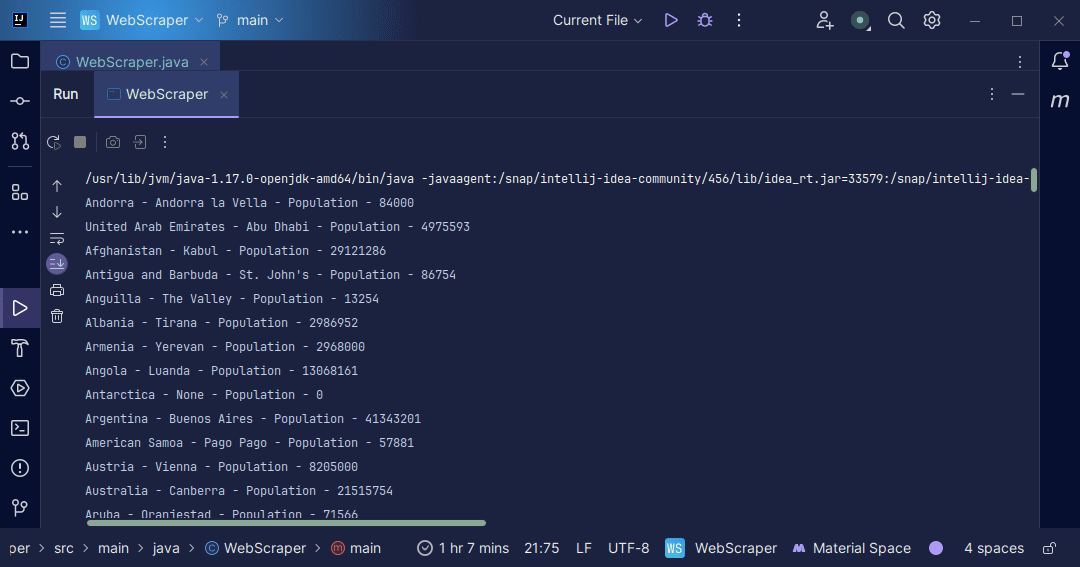
З інформацією, отриманою зі сторінки, ми можемо виконувати різноманітні дії,
наприклад роздруковувати її, як ми щойно зробили, або зберігати у файлі для
подальшої обробки даних.
Висновок
Веб-скрейпінг – це чудовий спосіб вилучати неструктуровані дані з веб-сайтів,
зберігати їх у структурованому вигляді та обробляти для отримання корисної
інформації. Проте, важливо пам’ятати про обережність при скануванні веб-сторінок,
оскільки деякі веб-сайти забороняють веб-скрейпінг.
Для безпечної практики використовуйте веб-сайти, які надають пісочниці. Також
завжди перевіряйте файл robots.txt кожного веб-сайту, щоб переконатися у
дозволі на збір даних.
При розробці веб-скрепера Java є чудовою мовою, оскільки пропонує бібліотеки,
які роблять цей процес простішим та ефективнішим. Розробка веб-скрепера
допоможе вам розвинути свої навички програмування. Тож спробуйте створити
власний веб-скрепер або змініть наявний для отримання різної інформації.
Бажаємо успіхів у кодуванні!
Ви також можете ознайомитися з деякими популярними хмарними рішеннями для
веб-скрейпінгу.