

Дипфейки відео означають, що ви не можете довіряти всьому, що бачите. Тепер дипфейки аудіо можуть означати, що ви більше не можете довіряти своїм вухам. Чи справді президент оголосив війну Канаді? Це справді ваш тато по телефону і запитує пароль його електронної пошти?
Додайте до списку ще одну екзистенційну тривогу про те, як наша власна гордість може неминуче знищити нас. За часів Рейгана єдиними реальними технологічними ризиками була загроза ядерної, хімічної та біологічної війни.
Протягом наступних років у нас була можливість зациклюватися на сірій липучці нанотехнологій і глобальних пандеміях. Тепер у нас є глибокі фейки — люди втрачають контроль над своєю схожістю чи голосом.
Що таке аудіо Deepfake?
Більшість з нас бачили відео дипфейк, в якому алгоритми глибокого навчання використовуються для заміни однієї людини на чиєсь інше. Найкращі є дуже реалістичними, а тепер черга аудіо. Дипфейк аудіо – це коли «клонований» голос, який потенційно неможливо відрізнити від реального, використовується для створення синтетичного аудіо.
«Це як Photoshop для голосу», – сказав Зохайб Ахмед, генеральний директор компанії Схожий на ШІ, про технологію клонування голосу його компанії.
Однак погані роботи Photoshop легко розвінчати. Охоронна фірма, з якою ми спілкувалися, сказала, що люди зазвичай лише здогадуються, справжній аудіо-фейк чи підробка з точністю приблизно 57 відсотків — не краще, ніж підкидання монети.
Крім того, оскільки так багато голосових записів є низькоякісними телефонними дзвінками (або записаними в шумних місцях), аудіо-підробки можна зробити ще більш нерозрізненими. Чим гірша якість звуку, тим важче вловити ці ознаки того, що голос не справжній.
Але навіщо комусь потрібен Photoshop для голосів?
Переконливий приклад для синтетичного аудіо
Насправді існує величезний попит на синтетичне аудіо. За словами Ахмеда, «рентабельність інвестицій надходить дуже швидко».
Це особливо вірно, коли справа доходить до ігор. У минулому мовлення було єдиним компонентом у грі, який неможливо було створити на вимогу. Навіть в інтерактивних заголовках зі сценами кінематографічної якості, які відображаються в режимі реального часу, вербальні взаємодії з неігровими персонажами завжди по суті статичні.
Проте зараз технології наздогнали. Студії мають потенціал для клонування голосу актора та використання механізмів синтезу мовлення, щоб персонажі могли говорити будь-що в режимі реального часу.
Є також більш традиційні види використання в рекламі, техніці та підтримці клієнтів. Тут важливий голос, який звучить справді по-людськи та відповідає особисто й контекстуально без участі людини.
Компанії з клонування голосу також в захваті від медичних застосувань. Звісно, заміна голосу не є чимось новим у медицині — Стівен Гокінг використав синтезований роботом голос після втрати власного в 1985 році. Однак сучасне клонування голосу обіцяє щось ще краще.
У 2008 році компанія синтетичного голосу, CereProc, дав покійному кінокритику Роджеру Еберту свій голос після того, як рак забрав його. CereProc опублікував веб-сторінку, яка дозволяла людям вводити повідомлення, які потім будуть вимовлятися голосом колишнього президента Джорджа Буша.
«Еберт побачив це і подумав: «Ну, якби вони могли скопіювати голос Буша, вони мали б можливість копіювати мій», — сказав Метью Айлетт, головний науковий співробітник CereProc. Потім Еберт попросив компанію створити замінний голос, що вони зробили, обробивши велику бібліотеку голосових записів.
«Це був один із перших випадків, коли хтось робив це, і це був справжній успіх», – сказала Айлетт.
Протягом останніх років ряд компаній (в тому числі CereProc) працювали з Асоціація ALS на Проект Revoice надати синтетичні голоси тим, хто страждає на БАС.

Як працює синтетичне аудіо
Клонування голосу зараз настає, і безліч компаній розробляють інструменти. Схожий на ШІ і Опис є онлайн-демо, кожен може спробувати безкоштовно. Ви просто записуєте фрази, які з’являються на екрані, і всього за кілька хвилин створюється модель вашого голосу.
Ви можете подякувати штучному інтелекту, зокрема алгоритмам глибокого навчання, за те, що він може зіставити записане мовлення з текстом, щоб зрозуміти компоненти фонем, які складають ваш голос. Потім він використовує отримані мовні будівельні блоки, щоб наблизити слова, які він не чув від вас.
Основна технологія існувала деякий час, але, як зазначила Айлетт, вона потребувала допомоги.
«Копіювання голосу було трохи схоже на приготування тіста», — сказав він. «Це було важко зробити, і вам доводилося налаштовувати це вручну різними способами, щоб змусити його працювати».
Розробникам потрібна була величезна кількість записаних голосових даних, щоб отримати задовільні результати. Потім, кілька років тому, відкрилися шлюзи. Критичними виявилися дослідження в області комп’ютерного зору. Вчені розробили генеративні змагальні мережі (GAN), які вперше могли екстраполювати та робити прогнози на основі наявних даних.
«Замість того, щоб комп’ютер бачив картинку коня і казав «це кінь», моя модель тепер могла б перетворити коня на зебру», – сказала Ейлетт. «Отже, вибух синтезу мовлення зараз відбувається завдяки академічній роботі з комп’ютерного зору».
Одним з найбільших нововведень у клонуванні голосу стало загальне зменшення кількості необроблених даних, необхідних для створення голосу. У минулому системам потрібні були десятки або навіть сотні годин аудіо. Тепер, однак, компетентні голоси можна генерувати лише за кілька хвилин контенту.
Екзистенційний страх нічому не довіряти
Ця технологія, поряд з ядерною енергетикою, нанотехнологіями, 3D-друком і CRISPR, водночас захоплює і жахає. Адже в новинах вже були випадки, коли людей обманюють голосовими клонами. У 2019 році компанія з Великобританії заявила, що так обдурений аудіо Deepfake телефонний дзвінок з метою передачі грошей злочинцям.
Вам також не потрібно ходити далеко, щоб знайти дивно переконливі аудіо підробки. канал YouTube Вокальний синтез показує, як добре відомі люди говорять те, чого вони ніколи не говорили, наприклад Джордж Буш читає «In Da Club» 50 Cent. Це на місці.
В інших місцях на YouTube можна почути зграю екс-президентів, в т.ч Обама, Клінтон і Рейган читають реп NWA. Музика та фонові звуки допомагають замаскувати деяку очевидну роботу роботів, але навіть у цьому недосконалому стані потенціал очевидний.
Ми експериментували з інструментами Схожий на ШІ і Опис і створив клон голосу. Descript використовує механізм клонування голосу, який спочатку називався Lyrebird і був особливо вражаючим. Ми були шоковані якістю. Чути власний голос те, що ти знаєш, що ніколи не говорив, нервує.
У промові, безперечно, є роботизована якість, але при невимушеному прослуховуванні у більшості людей не буде підстав вважати, що це підробка.
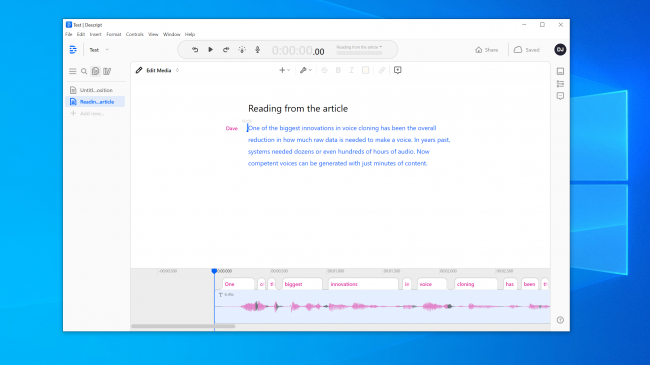
Ми покладали ще більші надії на Resemble AI. Він дає вам інструменти для створення розмови з кількома голосами та змінювати виразність, емоції та темп діалогу. Однак ми не думали, що голосова модель передає основні якості голосу, який ми використовували. Насправді, навряд чи це було когось обдурити.
Представник Resemble AI сказав нам, що «більшість людей вражені результатами, якщо вони роблять це правильно». Ми створили голосову модель двічі з подібними результатами. Отже, очевидно, не завжди легко створити голосовий клон, який можна використовувати для здійснення цифрового пограбування.
Незважаючи на це, засновник Lyrebird (яка зараз є частиною Descript), Кундан Кумар, вважає, що ми вже подолали цей поріг.
«У невеликому відсотку випадків це вже є», – сказав Кумар. «Якщо я використовую синтетичний звук, щоб змінити кілька слів у промові, це вже настільки добре, що вам буде важко зрозуміти, що змінилося».
Ми також можемо припустити, що з часом ця технологія буде тільки покращуватися. Системам буде потрібно менше звуку для створення моделі, а швидші процесори зможуть побудувати модель в режимі реального часу. Розумніший AI навчиться додавати більш переконливий людський ритм і акцент на мовленні, не маючи прикладу для роботи.
Це означає, що ми можемо наближатися до широкого поширення клонування голосу без зусиль.
Етика скриньки Пандори
Більшість компаній, що працюють у цій сфері, здається, готові поводитися з технологією безпечним та відповідальним чином. Схожий ШІ, наприклад, має цілий розділ «Етика» на своєму веб-сайті, і такий уривок є обнадійливим:
«Ми працюємо з компаніями через суворий процес, щоб переконатися, що голос, який вони клонують, використовується ними, і маємо належну згоду з акторами озвучування».
Крім того, Кумар сказав, що Lyrebird з самого початку стурбований неправильним використанням. Тому зараз, як частина Descript, він дозволяє людям лише клонувати власний голос. Фактично, як Resemble, так і Descript вимагають, щоб люди записували свої зразки наживо, щоб запобігти клонування голосу без узгодження.
Тішить те, що основні комерційні гравці нав’язали деякі етичні принципи. Однак важливо пам’ятати, що ці компанії не є прихильниками цієї технології. Вже існує ряд інструментів з відкритим кодом, для яких немає правил. За словами Генрі Адждера, керівника відділу розвідки загроз Deeptrace, вам також не потрібні розширені знання з кодування, щоб зловживати ним.
«Багато прогресу в цьому просторі досягнуто завдяки спільній роботі в таких місцях, як GitHub, з використанням реалізацій з відкритим кодом раніше опублікованих наукових робіт», — сказав Айдер. «Це може використовувати кожен, хто володіє помірними знаннями в кодуванні».
Професіонали в галузі безпеки бачили все це раніше
Злочинці намагалися вкрасти гроші по телефону задовго до того, як стало можливим клонування голосу, а експерти з безпеки завжди були на зв’язку, щоб виявити та запобігти цьому. Охоронна компанія Pindrop намагається зупинити банківське шахрайство, перевіряючи, чи є абонент тим, за кого він видає себе з аудіо. Тільки в 2019 році Pindrop стверджує, що проаналізував 1,2 мільярда голосових взаємодій і запобіг спробам шахрайства близько 470 мільйонів доларів.
Перед клонуванням голосу шахраї випробували ряд інших прийомів. Найпростішим було просто подзвонити з іншого місця з особистою інформацією про марку.
«Наша акустична сигнатура дозволяє нам визначити, що дзвінок насправді надходить з телефону Skype в Нігерії через характеристики звуку», — сказав генеральний директор Pindrop Віджай Баласубраманіян. «Тоді ми можемо порівняти, що, знаючи, що клієнт використовує телефон AT&T в Атланті».
Деякі злочинці також зробили кар’єру, використовуючи фонові звуки, щоб відкинути банківських представників.
«Є шахрай, якого ми називали «Курочка», у якого на задньому плані завжди ходили півні», — сказав Баласубраманіян. «І є одна жінка, яка використовувала плач дитини на задньому плані, щоб переконати агентів колл-центру, що «привіт, я переживаю важкий час», щоб отримати співчуття».
А ще є злочинці-чоловіки, які переслідують банківські рахунки жінок.
«Вони використовують технології, щоб збільшити частоту свого голосу, щоб звучати більш жіночно», – пояснила Баласубраманіян. Вони можуть бути успішними, але «іноді програмне забезпечення псується, і вони звучать як Елвін і бурундуки».
Звичайно, клонування голосу – це лише остання розробка в цій війні, що постійно загострюється. Охоронні фірми вже спіймали шахраїв, які використовували синтетичний звук принаймні в одній атаці підводного полювання.
«При правильній цілі виплата може бути величезною», – сказав Баласубраманіян. «Отже, має сенс присвятити час, щоб створити синтезований голос потрібної особистості».
Чи може хтось сказати, що голос фальшивий?

Коли справа доходить до розпізнавання, чи був голос підроблений, є як хороші, так і погані новини. Погано те, що голосові клони стають кращими з кожним днем. Системи глибокого навчання стають розумнішими і створюють більш автентичні голоси, для створення яких потрібно менше звуку.
Як можна зрозуміти з цього кліпу Президент Обама наказує МС Рену зайняти позицію, ми вже підійшли до того моменту, коли високоточна, ретельно побудована голосова модель може звучати досить переконливо для людського вуха.
Чим довший аудіокліп, тим більша ймовірність, що ви помітите, що щось не так. Однак для коротших кліпів ви можете не помітити, що вони синтетичні, особливо якщо у вас немає причин сумніватися в його законності.
Чим чіткіша якість звуку, тим легше помітити ознаки дипфейку звуку. Якщо хтось говорить прямо в мікрофон студійної якості, ви зможете слухати уважно. Але неякісний запис телефонного дзвінка або розмову, зняту на кишеньковий пристрій у галасливому гаражі, оцінити буде набагато важче.
Хороша новина полягає в тому, що навіть якщо людям важко відрізнити справжнє від підробки, комп’ютери не мають таких же обмежень. На щастя, інструменти голосової перевірки вже існують. Pindrop має один, який протиставляє системи глибокого навчання одна з одною. Він використовує і те, і інше, щоб дізнатися, чи є аудіо зразок тією людиною, якою вона повинна бути. Однак він також перевіряє, чи може людина навіть видавати всі звуки в семплі.
Залежно від якості звуку кожна секунда мовлення містить від 8 000 до 50 000 вибірок даних, які можна проаналізувати.
«Те, що ми зазвичай шукаємо, — це обмеження мовлення через еволюцію людини», — пояснив Баласубраманіян.
Наприклад, два вокальні звуки мають мінімально можливе відокремлення один від одного. Це тому, що фізично неможливо вимовити їх швидше через швидкість, з якою м’язи вашого рота і голосові зв’язки можуть переналаштуватися.
«Коли ми дивимося на синтезований аудіо, — сказав Баласубраманіян, — ми іноді бачимо речі і кажемо: «Це ніколи не могло бути створено людиною, тому що єдина людина, яка могла б створити це, повинна мати шию довжиною 7 футів. ”
Існує також клас звуків, який називається «фрикативні». Вони утворюються, коли повітря проходить через вузьке звуження у вашому горлі, коли ви вимовляєте такі літери, як f, s, v і z. Особливо важко оволодіти фрикативами системам глибокого навчання, оскільки програмному забезпеченню важко відрізнити їх від шуму.
Тож, принаймні наразі, програмне забезпечення для клонування голосу спотикається через те, що люди — це мішки з м’ясом, які пропускають повітря через отвори в їхніх