Дипфейк-відео вже змусили нас сумніватися в тому, що ми бачимо. Тепер, дипфейк-аудіо може змусити нас перестати довіряти навіть власним вухам. Чи дійсно глава держави оголосив війну іншій країні? Чи справді це ваш родич телефонує, щоб отримати доступ до вашої електронної пошти?
Додамо ще одне занепокоєння до вже існуючих страхів про те, як наша власна самовпевненість може призвести до самознищення. В минулі часи, коли світ хвилювали ядерна, хімічна та біологічна загрози, технологічні ризики здавалися менш підступними.
Згодом нас почали турбувати сірі зони нанотехнологій і глобальні пандемії. Тепер ми маємо справу з дипфейками – технологією, яка дозволяє маніпулювати зовнішністю і голосами людей.
Що таке аудіодипфейк?
Більшість із нас вже бачили відео дипфейки, де за допомогою алгоритмів штучного інтелекту одне обличчя замінюють на інше. Найкращі з цих підробок дуже реалістичні. Тепер аналогічна технологія застосовується до аудіо. Аудіодипфейк – це створення синтетичного звуку за допомогою “клонованого” голосу, який майже неможливо відрізнити від справжнього.
За словами Зохаїба Ахмеда, керівника компанії Resemble AI, технологія клонування голосу – це “наче Photoshop для звуку”.
Однак, як і невдалі фотошопні роботи, аудіодипфейки теж можна розпізнати. Експерти з безпеки стверджують, що люди розрізняють справжній і підроблений звук лише в 57% випадків, тобто не краще, ніж при підкиданні монети.
Крім того, більшість голосових записів – це телефонні розмови поганої якості або записи в шумних місцях, що робить аудіо-підробки ще складнішими для розпізнавання. Чим гірша якість звуку, тим важче виявити ознаки підробки.
Але навіщо взагалі потрібен Photoshop для голосів?
Переваги синтезованого аудіо
Синтезоване аудіо насправді користується великим попитом. За словами Ахмеда, “інвестиції в цю технологію швидко окупаються”.
Особливо це актуально в ігровій індустрії. Раніше, мова була єдиним компонентом гри, який не можна було створити на вимогу. Навіть в сучасних іграх з кінематографічними сценами, діалог з неігровими персонажами часто був статичним.
Тепер технології вийшли на новий рівень. Студії можуть клонувати голоси акторів і використовувати синтез мовлення, щоб персонажі могли говорити будь-що в реальному часі.
Також, технологія має застосування в рекламі, техніці та підтримці клієнтів. Тут важливо, щоб голос звучав природно, відповідав ситуації та не потребував участі живої людини.
Компанії, що займаються клонуванням голосу, також бачать великий потенціал у медицині. Звичайно, заміна голосу не новина в медицині – Стівен Хокінг використовував синтезований голос після втрати власного. Однак, сучасні технології клонування голосу обіцяють щось більше.
У 2008 році компанія CereProc, відтворила голос покійного кінокритика Роджера Еберта, після того, як рак позбавив його можливості говорити. CereProc створила веб-сторінку, де люди могли вводити повідомлення, які потім озвучувались голосом колишнього президента Джорджа Буша.
“Еберт побачив це і сказав: “Якщо вони можуть скопіювати голос Буша, вони можуть скопіювати і мій”, – розповів Меттью Айлетт, головний науковий співробітник CereProc. Після цього Еберт попросив створити йому замінний голос, що і було зроблено за допомогою великої бібліотеки голосових записів.
“Це був один із перших випадків, коли хтось це зробив, і це був справжній успіх”, – зазначив Айлетт.
В останні роки ряд компаній (включаючи CereProc) співпрацювали з Асоціацією ALS у проєкті Project Revoice, щоб надати синтетичні голоси людям з БАС.

Як працює синтетичне аудіо
Технологія клонування голосу постійно розвивається, і багато компаній працюють над розробкою відповідних інструментів. Resemble AI і Descript пропонують онлайн-демо версії, які кожен може спробувати безкоштовно. Вам просто потрібно записати фрази, що з’являються на екрані, і за кілька хвилин буде створена модель вашого голосу.
Завдяки штучному інтелекту, зокрема алгоритмам глибокого навчання, комп’ютер може зіставити записану мову з текстом, щоб зрозуміти фонеми, з яких складається ваш голос. Потім він використовує отримані мовні блоки, щоб імітувати слова, які він не чув від вас раніше.
Основна технологія існувала вже деякий час, але, як зазначила Айлетт, вона потребувала вдосконалення.
“Копіювання голосу було схоже на приготування тіста”, – сказав він. “Це було важко зробити, і потрібно було налаштовувати його вручну різними способами, щоб змусити його працювати”.
Розробникам потрібна була велика кількість записаних голосових даних, щоб отримати задовільні результати. Але кілька років тому, все змінилося. Ключовими виявилися дослідження в галузі комп’ютерного зору. Вчені розробили генеративні змагальні мережі (GAN), які вперше змогли екстраполювати та робити прогнози на основі наявних даних.
“Замість того, щоб комп’ютер бачив зображення коня і казав “це кінь”, моя модель тепер могла б перетворити коня на зебру”, – сказала Ейлетт. “Отже, вибух синтезу мовлення зараз відбувається завдяки академічній роботі з комп’ютерного зору”.
Одним з найбільших досягнень у клонуванні голосу стало значне зменшення обсягу необроблених даних, необхідних для створення голосу. Раніше системам потрібні були десятки або навіть сотні годин аудіо. Тепер, однак, якісний голос можна створити всього за кілька хвилин.
Страх недовіри до всього
Ця технологія, як і ядерна енергетика, нанотехнології, 3D-друк і CRISPR, одночасно захоплює і лякає. У новинах вже з’являлися повідомлення про випадки обману людей за допомогою голосових клонів. У 2019 році компанія з Великобританії заявила, що стала жертвою аудіодипфейк-шахрайства і переказала гроші злочинцям.
Не потрібно далеко ходити, щоб знайти переконливі аудіопідробки. На YouTube каналі Vocal Synthesis можна побачити, як відомі люди говорять те, чого вони ніколи не говорили, наприклад, Джордж Буш читає реп “In Da Club” 50 Cent.
На інших каналах YouTube можна почути, як колишні президенти Обама, Клінтон і Рейган читають реп NWA. Хоч музика та фонові звуки і маскують деякі недоліки, потенціал все одно вражає.
Ми спробували інструменти Resemble AI і Descript і створили власний голосовий клон. Descript використовує технологію клонування голосу Lyrebird, яка є особливо вражаючою. Ми були вражені якістю. Слухати власний голос, який каже те, чого ти ніколи не говорив – це дивно.
Звичайно, у мові є деяка роботизованість, але при звичайному прослуховуванні, більшість людей не помітить підробку.
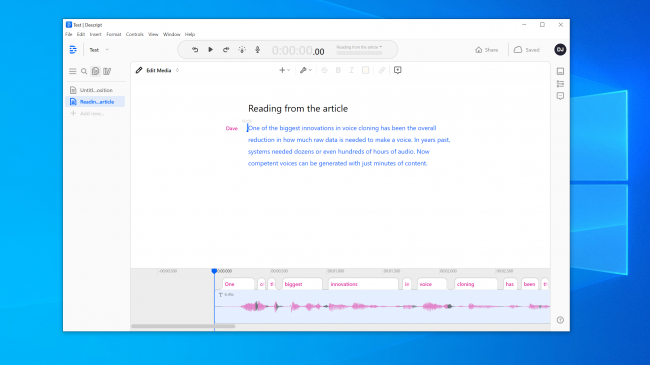
Ми покладали великі надії на Resemble AI. Він пропонує інструменти для створення діалогів з кількома голосами, змінювати виразність, емоції та темп. Однак, ми не впевнені, що голосова модель передає основні характеристики голосу, який ми використовували. Насправді, навряд чи когось можна було б обдурити.
Представник Resemble AI сказав нам, що “більшість людей вражені результатами, якщо вони роблять це правильно”. Ми створювали голосову модель двічі з подібними результатами. Отже, очевидно, не завжди легко створити якісний голосовий клон.
Незважаючи на це, засновник Lyrebird (тепер частина Descript), Кундан Кумар, вважає, що ми вже досягли цього рівня.
“У деяких випадках це вже є”, – сказав Кумар. “Якщо я використовую синтетичний звук, щоб змінити кілька слів в розмові, це вже настільки добре, що вам буде важко зрозуміти, що змінилося”.
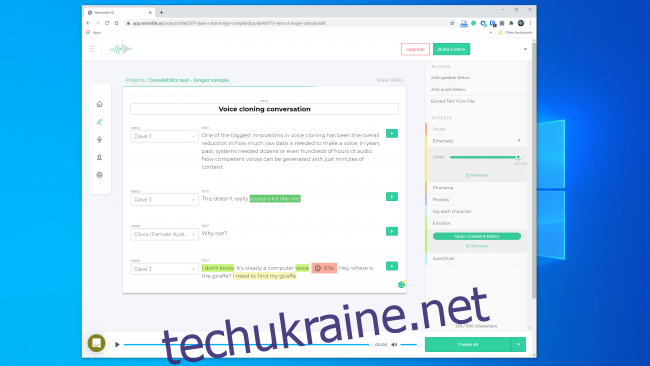
З часом ця технологія буде тільки вдосконалюватися. Системам потрібно буде менше звуку для створення моделі, а швидші процесори зможуть будувати модель в реальному часі. Штучний інтелект навчиться додавати більш переконливий людський ритм і акцент в мову, навіть не маючи прикладу для наслідування.
Це означає, що ми наближаємося до широкого розповсюдження клонування голосу.
Етичні питання
Більшість компаній, які працюють в цій сфері, здається, готові використовувати технологію відповідально. Resemble AI, наприклад, має цілий розділ “Етика” на своєму веб-сайті:
“Ми ретельно співпрацюємо з компаніями, щоб переконатися, що голос, який вони клонують, використовується з їхньою згодою та згодою акторів озвучування”.
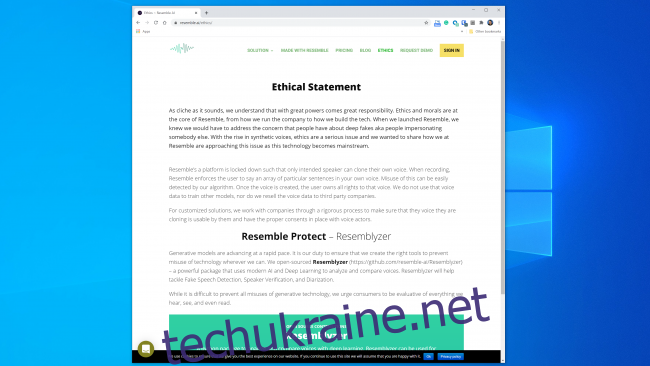
Крім того, Кумар сказав, що Lyrebird з самого початку стурбований можливим зловживанням. Тому зараз, як частина Descript, він дозволяє людям клонувати тільки власний голос. І Resemble, і Descript вимагають, щоб люди записували зразки голосу в режимі реального часу, щоб запобігти клонуванню голосу без згоди.
Приємно бачити, що основні гравці ввели певні етичні принципи. Однак, важливо пам’ятати, що ці компанії не єдині, хто має доступ до технології. Існує ряд інструментів з відкритим кодом, до яких не застосовуються жодні правила. За словами Генрі Адждера, керівника відділу розвідки загроз Deeptrace, для зловживання цією технологією не потрібні спеціальні знання з програмування.
“Багато прогресу в цьому напрямку досягнуто завдяки спільній роботі на таких платформах, як GitHub, з використанням реалізацій з відкритим кодом раніше опублікованих наукових робіт”, – сказав Айдер. “Це може використовувати кожен, хто має базові знання з програмування”.
Експерти з безпеки вже бачили це раніше
Злочинці намагалися вкрасти гроші по телефону ще задовго до того, як з’явилася технологія клонування голосу. Експерти з безпеки завжди були готові до того, щоб виявити та запобігти цьому. Компанія Pindrop бореться з шахрайством в банківській сфері, перевіряючи, чи є абонент тим, за кого він себе видає.
Тільки в 2019 році Pindrop проаналізував 1,2 мільярда голосових взаємодій і запобіг спробам шахрайства на суму близько 470 мільйонів доларів.
До появи клонування голосу, шахраї використовували різні прийоми. Найпростішим було просто подзвонити з іншого місця, використовуючи особисту інформацію клієнта.
“Наша акустична сигнатура дозволяє нам визначити, що дзвінок насправді надходить з телефону Skype в Нігерії, через характеристики звуку”, – сказав генеральний директор Pindrop Віджай Баласубраманіян. “Тоді ми можемо порівняти це з тим, що клієнт використовує телефон AT&T в Атланті”.
Деякі злочинці також використовують фонові звуки, щоб ввести в оману банківських представників.
“Є шахрай, якого ми називали “Курочка”, у якого на задньому плані завжди ходили кури”, – сказав Баласубраманіян. “А ще є жінка, яка використовувала плач дитини на задньому плані, щоб переконати операторів кол-центру, що вона в скруті, і отримати співчуття”.
Також, існують чоловіки, які полюють на банківські рахунки жінок.
“Вони використовують технології, щоб підвищити частоту свого голосу, щоб звучати більш жіночно”, – пояснив Баласубраманіян. Іноді це спрацьовує, але “іноді програма дає збій, і вони починають звучати як Елвін і бурундуки”.
Звичайно, клонування голосу – це лише новий етап у цій постійній боротьбі. Компанії з безпеки вже спіймали шахраїв, які використовували синтетичний звук принаймні в одній атаці.
“При правильній цілі виплата може бути величезною”, – сказав Баласубраманіян. “Отже, є сенс витратити час на створення синтетичного голосу конкретної особистості”.
Чи можна розпізнати підроблений голос?

Щодо розпізнавання підробленого голосу, є як хороші, так і погані новини. Погана новина полягає в тому, що голосові клони стають кращими з кожним днем. Системи глибокого навчання стають розумнішими і створюють більш автентичні голоси, для яких потрібно менше звуку.
Як можна почути в цьому кліпі Президент Обама дає команду реперу MC Ren, ми вже досягли моменту, коли якісно створена голосова модель може звучати дуже переконливо.
Чим довший аудіозапис, тим більше ймовірності, що ви помітите щось не так. Однак, в коротких аудіофайлах, ви можете не помітити, що вони синтетичні, особливо якщо у вас немає причин сумніватися в їхній автентичності.
Чим чіткіша якість звуку, тим легше розпізнати ознаки аудіодипфейка. Якщо хтось говорить прямо в мікрофон студійної якості, можна уважно прислухатися. Але неякісні записи телефонної розмови або звуку, знятого на мобільний пристрій в шумному місці, буде набагато важче оцінити.
Хороша новина полягає в тому, що навіть якщо людям важко відрізнити справжнє від підробки, комп’ютери мають більші можливості. На щастя, вже існують інструменти голосової перевірки. Pindrop розробила систему, яка порівнює різні системи глибокого навчання. Вона використовує їх, щоб визначити, чи належить аудіо тій людині, за яку її видають. Також, система перевіряє, чи може людина взагалі відтворювати всі звуки в зразку.
Залежно від якості звуку, кожна секунда мовлення містить від 8000 до 50000 вибірок даних, які можна проаналізувати.
“Зазвичай ми шукаємо обмеження мови, пов’язані з еволюцією людини”, – пояснив Баласубраманіян.
Наприклад, два вокальні звуки мають мінімальну можливу відстань між собою. Це тому, що фізично неможливо вимовити їх швидше, через швидкість, з якою м’язи вашого рота і голосові зв’язки можуть переналаштуватися.
“Коли ми аналізуємо синтезоване аудіо, іноді ми бачимо речі, які кажуть: “Це неможливо, щоб людина так говорила, бо для цього потрібно мати шию довжиною 2 метри””, – сказав Баласубраманіян.
Також існує клас звуків, які називаються “фрикативними”. Вони утворюються, коли повітря проходить через вузьку щілину в горлі, коли ви вимовляєте такі літери, як f, s, v і z. Системам глибокого навчання особливо важко опрацювати фрикативи, оскільки програмному забезпеченню важко відрізнити їх від шуму.
Отже, принаймні поки що, програмне забезпечення для клонування голосу спотикається через те, що люди – це мішки з м’ясом, які пропускають повітря через отвори в їхніх тілах.