
Ви зацікавлені в аналізі своїх даних за допомогою природної мови? Дізнайтеся, як це зробити за допомогою бібліотеки Python PandasAI.
У світі, де дані мають вирішальне значення, важливо їх розуміти та аналізувати. Однак традиційний аналіз даних може бути складним. Ось тут на допомогу приходить PandasAI. Він спрощує аналіз даних, дозволяючи спілкуватися з даними за допомогою природної мови.
Pandas AI працює, перетворюючи ваші запитання на код для аналізу даних. Він заснований на популярній бібліотеці Python pandas. PandasAI — це бібліотека Python, яка розширює pandas, добре відомий інструмент аналізу та обробки даних, функціями Generative AI. Він має на меті доповнити панд, а не замінити їх.
PandasAI вводить розмовний аспект у pandas (а також інші широко використовувані бібліотеки аналізу даних), що дозволяє вам взаємодіяти з вашими даними за допомогою запитів природною мовою.
Цей підручник проведе вас через кроки налаштування Pandas AI, використання його з реальним набором даних, створення графіків, вивчення ярликів, а також вивчення сильних сторін і обмежень цього потужного інструменту.
Після його завершення ви зможете легше та інтуїтивно зрозуміліше виконувати аналіз даних природною мовою.
Отже, давайте досліджувати захоплюючий світ аналізу даних природної мови за допомогою ШІ Pandas!
Налаштування вашого середовища
Щоб розпочати роботу з PandasAI, вам слід почати з інсталяції бібліотеки PandasAI.
Для цього проекту я використовую блокнот Jupyter. Але ви можете використовувати Google Collab або VS Code відповідно до ваших вимог.
Якщо ви плануєте використовувати великі мовні моделі відкритого штучного інтелекту (LLM), також важливо встановити Open AI Python SDK для плавної роботи.
# Installing Pandas AI !pip install pandas-ai # Pandas AI uses OpenAI's language models, so you need to install the OpenAI Python SDK !pip install openai
Тепер давайте імпортуємо всі необхідні бібліотеки:
# Importing necessary libraries import pandas as pd import numpy as np # Importing PandasAI and its components from pandasai import PandasAI, SmartDataframe from pandasai.llm.openai import OpenAI
Ключовим аспектом аналізу даних за допомогою PandasAI є ключ API. Цей інструмент підтримує декілька великих мовних моделей (LLM) і моделей LangChains, які використовуються для створення коду із запитів природною мовою. Це робить аналіз даних більш доступним і зручним для користувача.
PandasAI є універсальним і може працювати з різними типами моделей. Серед них моделі Hugging Face, Azure OpenAI, Google PALM і Google VertexAI. Кожна з цих моделей має власні сильні сторони, розширюючи можливості PandasAI.
Пам’ятайте, що для використання цих моделей вам знадобляться відповідні ключі API. Ці ключі автентифікують ваші запити та дозволяють використовувати потужність цих передових мовних моделей у ваших завданнях аналізу даних. Отже, переконайтеся, що ваші ключі API під рукою, коли налаштовуватимете PandasAI для ваших проектів.
Ви можете отримати ключ API та експортувати його як змінну середовища.
На наступному кроці ви дізнаєтеся, як використовувати PandasAI з різними типами великих мовних моделей (LLM) від OpenAI і Hugging Face Hub.
Використання великих мовних моделей
Ви можете вибрати LLM, створивши екземпляр і передавши його конструктору SmartDataFrame або SmartDatalake, або ви можете вказати один у файлі pandasai.json.
Якщо модель очікує один або більше параметрів, ви можете передати їх у конструктор або вказати у файлі pandasai.json у параметрі llm_options, як показано нижче:
{
"llm": "OpenAI",
"llm_options": {
"api_token": "API_TOKEN_GOES_HERE"
}
}
Як використовувати моделі OpenAI?
Щоб використовувати моделі OpenAI, вам потрібно мати ключ OpenAI API. Ви можете отримати один тут.
Отримавши ключ API, ви можете використовувати його для створення екземпляра об’єкта OpenAI:
#We have imported all necessary libraries in privious step
llm = OpenAI(api_token="my-api-key")
pandas_ai = SmartDataframe("data.csv", config={"llm": llm})
Не забудьте замінити «my-api-key» на оригінальний ключ API
Як альтернативу ви можете встановити змінну середовища OPENAI_API_KEY і створити екземпляр об’єкта OpenAI без передачі ключа API:
# Set the OPENAI_API_KEY environment variable
llm = OpenAI() # no need to pass the API key, it will be read from the environment variable
pandas_ai = SmartDataframe("data.csv", config={"llm": llm})
Якщо ви працюєте за явним проксі-сервером, ви можете вказати openai_proxy під час створення екземпляра об’єкта OpenAI або налаштувати передачу змінної середовища OPENAI_PROXY.
Важлива примітка. Використовуючи бібліотеку PandasAI для аналізу даних із вашим ключем API, важливо відстежувати використання маркера, щоб керувати витратами.
Цікаво, як це зробити? Просто запустіть наступний код лічильника токенів, щоб отримати чітке уявлення про використання ваших токенів і відповідні витрати. Таким чином ви зможете ефективно керувати своїми ресурсами та уникнути будь-яких сюрпризів у виставленні рахунків.
Ви можете підрахувати кількість маркерів, використаних підказкою, наступним чином:
"""Example of using PandasAI with a pandas dataframe"""
from pandasai import SmartDataframe
from pandasai.llm import OpenAI
from pandasai.helpers.openai_info import get_openai_callback
import pandas as pd
llm = OpenAI()
# conversational=False is supposed to display lower usage and cost
df = SmartDataframe("data.csv", {"llm": llm, "conversational": False})
with get_openai_callback() as cb:
response = df.chat("Calculate the sum of the gdp of north american countries")
print(response)
print(cb)
Ви отримаєте такі результати:
# The sum of the GDP of North American countries is 19,294,482,071,552. # Tokens Used: 375 # Prompt Tokens: 210 # Completion Tokens: 165 # Total Cost (USD): $ 0.000750
Не забудьте вести облік загальних витрат, якщо у вас обмежений кредит!
Як використовувати моделі обличчя, що обіймаються?
Щоб використовувати моделі HuggingFace, вам потрібно мати ключ HuggingFace API. Ви можете створити обліковий запис HuggingFace тут і отримати ключ API тут.
Отримавши ключ API, ви можете використовувати його для створення екземпляра однієї з моделей HuggingFace.
На даний момент PandasAI підтримує наступні моделі HuggingFace:
- Старкодер: bigcode/starcoder
- Falcon: tiiuae/falcon-7b-instruct
from pandasai.llm import Starcoder, Falcon
llm = Starcoder(api_token="my-huggingface-api-key")
# or
llm = Falcon(api_token="my-huggingface-api-key")
df = SmartDataframe("data.csv", config={"llm": llm})
Як альтернативу ви можете встановити змінну середовища HUGGINGFACE_API_KEY і створити об’єкт HuggingFace без передачі ключа API:
from pandasai.llm import Starcoder, Falcon
llm = Starcoder() # no need to pass the API key, it will be read from the environment variable
# or
llm = Falcon() # no need to pass the API key, it will be read from the environment variable
df = SmartDataframe("data.csv", config={"llm": llm})
Starcoder і Falcon є моделями LLM, доступними на Hugging Face.
Ми успішно налаштували наше середовище та дослідили, як використовувати моделі OpenAI і Hugging Face LLMs. А тепер давайте продовжимо аналіз даних.
Ми будемо використовувати набір даних Big Mart Sales data, який містить інформацію про продажі різних товарів у різних торгових точках Big Mart. Набір даних складається з 12 стовпців і 8524 рядків. Посилання ви отримаєте в кінці статті.
Аналіз даних за допомогою PandasAI
Тепер, коли ми успішно встановили та імпортували всі необхідні бібліотеки, давайте приступимо до завантаження нашого набору даних.
Завантажте набір даних
Ви можете вибрати LLM, створивши екземпляр і передавши його в SmartDataFrame. Ви отримаєте посилання на набір даних у кінці статті.
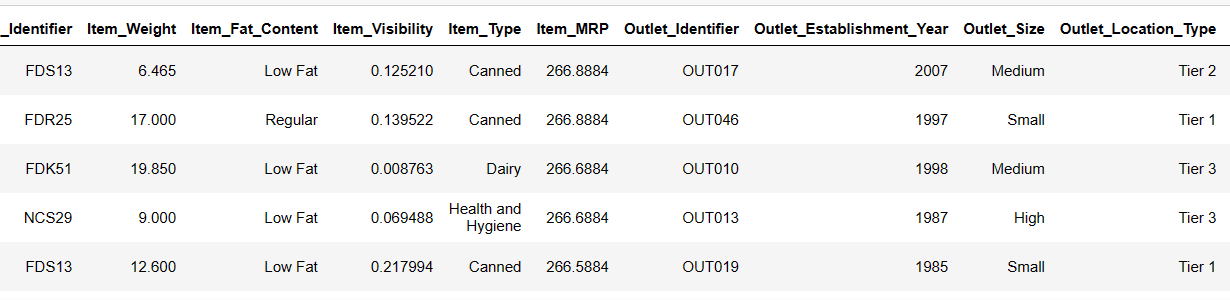
#Load the dataset from device path = r"D:\Pandas AI\Train.csv" df = SmartDataframe(path)
Використовуйте модель LLM OpenAI
Після завантаження наших даних. Я збираюся використовувати модель LLM OpenAI для використання PandasAI
llm = OpenAI(api_token="API_Key") pandas_ai = PandasAI(llm, conversational=False)
Все добре! А тепер спробуємо скористатися підказками.
Надрукуйте перші 6 рядків нашого набору даних
Давайте спробуємо завантажити перші 6 рядків, надавши інструкції:
Result = pandas_ai(df, "Show the first 6 rows of data in tabular form") Result
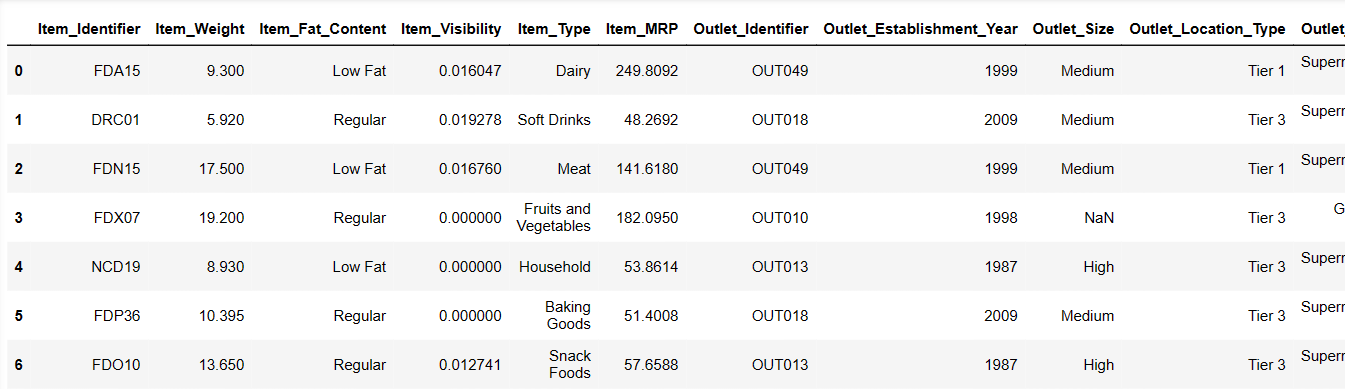 Перші 6 рядків із набору даних
Перші 6 рядків із набору даних
Це було дуже швидко! Давайте розберемося з нашим набором даних.
Створення описової статистики DataFrame
# To get descriptive statistics Result = pandas_ai(df, "Show the description of data in tabular form") Result
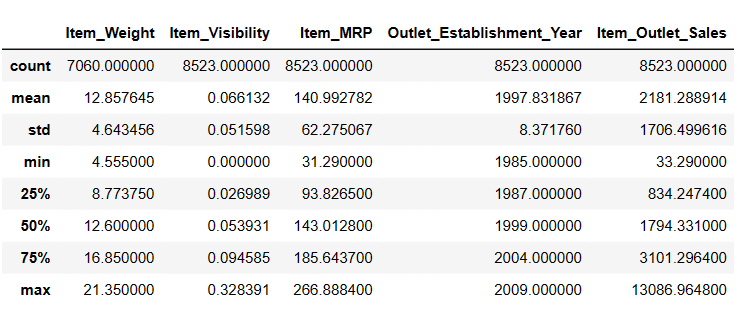 опис
опис
Існує 7060 значень у Item_Weigth; можливо, бракує деяких значень.
Знайти відсутні значення
Є два способи знайти відсутні значення за допомогою pandas ai.
#Find missing values Result = pandas_ai(df, "Show the missing values of data in tabular form") Result
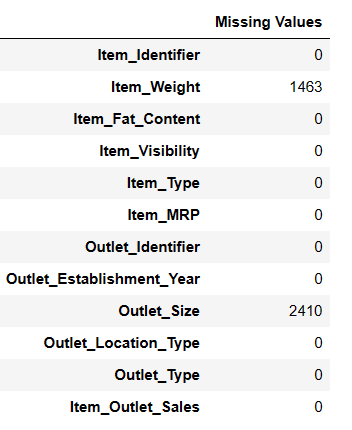 Пошук відсутніх значень
Пошук відсутніх значень
# Ярлик для очищення даних
df = SmartDataframe('data.csv')
df.clean_data()
Цей ярлик виконає очищення даних у кадрі даних.
Тепер давайте заповнимо відсутні нульові значення.
Заповніть відсутні значення
#Fill Missing values result = pandas_ai(df, "Fill Item Weight with median and Item outlet size null values with mode and Show the missing values of data in tabular form") result
 Заповнені нульові значення
Заповнені нульові значення
Це корисний метод заповнення нульових значень, але я зіткнувся з деякими проблемами під час заповнення нульових значень.
# Ярлик для заповнення нульових значень
df = SmartDataframe('data.csv')
df.impute_missing_values()
Цей ярлик додасть відсутні значення у кадрі даних.
Відкинути нульові значення
Якщо ви хочете видалити всі нульові значення з вашого df, ви можете спробувати цей метод.
result = pandas_ai(df, "Drop the row with missing values with inplace=True") result
Аналіз даних має важливе значення для виявлення тенденцій, як короткострокових, так і довгострокових, що може бути безцінним для компаній, урядів, дослідників і окремих людей.
Давайте спробуємо знайти загальну тенденцію продажів за роки з моменту заснування.
Пошук тенденції продажів
# finding trend in sales result = pandas_ai(df, "What is the overall trend in sales over the years since outlet establishment?") result
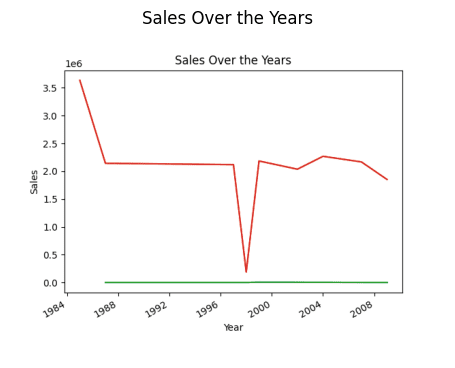 Продажі за рік (лінія)
Продажі за рік (лінія)
Початковий процес створення сюжету був трохи повільним, але після перезапуску ядра та запуску всього цього він працював швидше.
# Ярлик для побудови лінійних графіків
df.plot_line_chart(x = ['a', 'b', 'c'], y = [1, 2, 3])
Цей ярлик побудує лінійну діаграму кадру даних.
Вам може бути цікаво, чому спостерігається зниження тренду. Це пов’язано з тим, що ми не маємо даних з 1989 по 1994 рік.
Пошук року найвищих продажів
А тепер давайте дізнаємося, в якому році продажі найбільші.
# finding year of highest sales result = pandas_ai(df, "Explain which years have highest sales") result

Отже, рік з найбільшими продажами – 1985 рік.
Але я хочу з’ясувати, який тип товару генерує найвищі середні продажі, а який тип генерує найменші середні продажі.
Найвищі та найнижчі середні продажі
# finding highest and lowest average sale result = pandas_ai(df, "Which item type generates the highest average sales, and which one generates the lowest?") result

Крохмалисті продукти мають найвищі середні продажі, а інші мають найнижчі середні продажі. Якщо ви не хочете, щоб інші мали найнижчі продажі, ви можете покращити підказку відповідно до ваших потреб.
Чудово! Тепер я хочу з’ясувати розподіл продажів між різними торговими точками.
Розподіл продажів по різних торгових точках
Існує чотири типи торгових точок: Супермаркет типу 1/2/3 і Продуктові магазини.
# distribution of sales across different outlet types since establishment response = pandas_ai(df, "Visualize the distribution of sales across different outlet types since establishment using bar plot, plot size=(13,10)") response
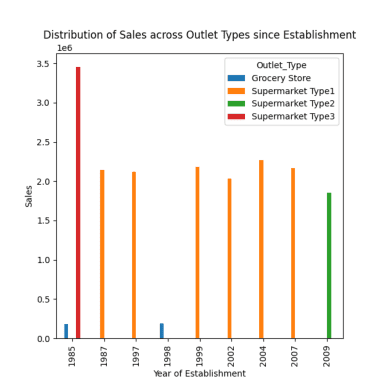 Розподіл продажів по різних торгових точках
Розподіл продажів по різних торгових точках
Як спостерігалося в попередніх підказках, пік продажів припав на 1985 рік, і на цьому графіку показано найвищі продажі в 1985 році в супермаркетах типу 3.
# Ярлик для побудови гістограми
df = SmartDataframe('data.csv')
df.plot_bar_chart(x = ['a', 'b', 'c'], y = [1, 2, 3])
Цей ярлик побудує гістограму кадру даних.
# Ярлик для побудови гістограми
df = SmartDataframe('data.csv')
df.plot_histogram(column = 'a')
Цей ярлик побудує гістограму кадру даних.
А тепер давайте дізнаємось, які середні продажі товарів із вмістом жиру «з низьким вмістом жиру» та «звичайним».
Знайдіть середні показники продажів для товарів із вмістом жиру
# finding index of a row using value of a column result = pandas_ai(df, "What is the average sales for the items with 'Low Fat' and 'Regular' item fat content?") result
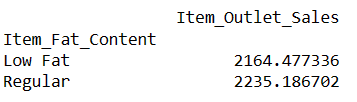
Написання таких підказок дає змогу порівнювати два чи більше продуктів.
Середні продажі для кожного типу товару
Я хочу порівняти всі продукти з їхніми середніми продажами.
#Average Sales for Each Item Type result = pandas_ai(df, "What are the average sales for each item type over the past 5 years?, use pie plot, size=(6,6)") result
 Кругова діаграма середніх продажів
Кругова діаграма середніх продажів
Усі розділи кругової діаграми виглядають схожими, оскільки вони мають майже однакові цифри продажів.
# Ярлик для побудови кругової діаграми
df.plot_pie_chart(labels = ['a', 'b', 'c'], values = [1, 2, 3])
Цей ярлик побудує секторну діаграму кадру даних.
5 найпопулярніших типів товарів
Хоча ми вже порівняли всі продукти на основі середніх продажів, тепер я хотів би визначити 5 найкращих товарів із найвищими продажами.
#Finding top 5 highest selling items result = pandas_ai(df, "What are the top 5 highest selling item type based on average sells? Write in tablular form") result
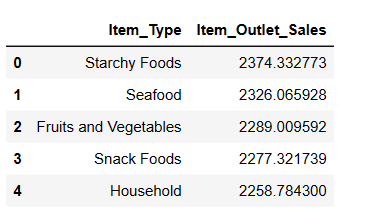
Як і очікувалося, виходячи з середнього обсягу продажів, найпопулярнішим є продукт із крохмалем.
Топ-5 типів найнижчих товарів
result = pandas_ai(df, "What are the top 5 lowest selling item type based on average sells?") result
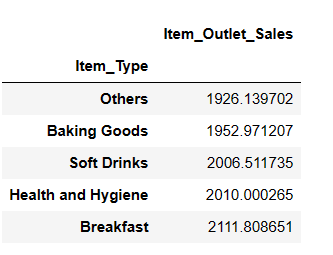
Ви можете бути здивовані, побачивши безалкогольні напої в категорії найнижчих продажів. Однак важливо зазначити, що ці дані стосуються лише 2008 року, а тенденція щодо безалкогольних напоїв з’явилася через кілька років.
Продаж категорій продуктів
Тут я використав слово «категорія продукту» замість «тип товару», і PandasAI все одно створив графіки, демонструючи своє розуміння подібних слів.
result = pandas_ai(df, "Give a stacked large size bar chart of the sales of the various product categories for the last FY") result
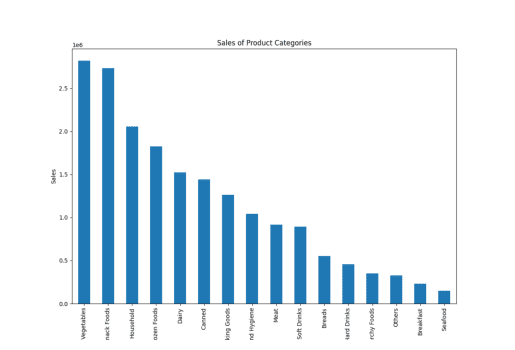 Продаж типу товару
Продаж типу товару
Ви можете знайти інші ярлики тут.
Ви можете помітити, що коли ми пишемо підказку та надаємо інструкції PandasAI, він надає результати виключно на основі цієї підказки. Він не аналізує ваші попередні підказки, щоб запропонувати точніші відповіді.
Однак за допомогою агента чату ви також можете досягти цієї функції.
Агент чату
За допомогою агента чату ви можете брати участь у динамічних бесідах, де агент зберігає контекст під час обговорення. Це дає змогу мати більш інтерактивний та змістовний обмін.
Основні функції, які забезпечують цю взаємодію, включають збереження контексту, коли агент запам’ятовує історію розмов, що забезпечує безперебійну взаємодію з урахуванням контексту. Ви можете використовувати метод уточнюючих запитань, щоб отримати роз’яснення щодо будь-якого аспекту розмови, переконавшись, що ви повністю розумієте надану інформацію.
Крім того, метод Explain доступний для отримання детальних пояснень того, як агент прийшов до певного рішення або відповіді, пропонуючи прозорість і розуміння процесу прийняття рішень агентом.
Не соромтеся розпочинати розмови, шукати роз’яснень і досліджувати пояснення, щоб покращити вашу взаємодію з агентом чату!
from pandasai import Agent
agent = Agent(df, config={"llm": llm}, memory_size=10)
result = agent.chat("Which are top 5 items with highest MRP")
result
На відміну від SmartDataframe або SmartDatalake, агент відстежуватиме стан розмови та зможе відповідати на багаточергові розмови.
Давайте перейдемо до переваг і обмежень PandasAI
Переваги PandasAI
Використання Pandas AI пропонує кілька переваг, які роблять його цінним інструментом для аналізу даних, наприклад:
- Доступність: PandasAI спрощує аналіз даних, роблячи його доступним для широкого кола користувачів. Будь-хто, незалежно від свого технічного досвіду, може використовувати його, щоб отримати інформацію з даних і відповісти на бізнес-питання.
- Запити природною мовою: можливість ставити запитання безпосередньо та отримувати відповіді з даних за допомогою запитів природною мовою робить дослідження та аналіз даних більш зручними для користувача. Ця функція дозволяє навіть нетехнічним користувачам ефективно взаємодіяти з даними.
- Функціональність чату агента: функція чату дозволяє користувачам взаємодіяти з даними в інтерактивному режимі, тоді як функція чату агента використовує історію попереднього чату, щоб надавати відповіді з урахуванням контексту. Це сприяє динамічному та розмовному підходу до аналізу даних.
- Візуалізація даних: PandasAI надає ряд опцій візуалізації даних, включаючи теплові карти, точкові діаграми, стовпчасті діаграми, кругові діаграми, лінійні діаграми тощо. Ці візуалізації допомагають зрозуміти та представити шаблони даних і тенденції.
- Швидкі клавіші для економії часу: наявність ярликів і функцій для економії часу оптимізує процес аналізу даних, допомагаючи користувачам працювати ефективніше та результативніше.
- Сумісність файлів: PandasAI підтримує різні формати файлів, включаючи CSV, Excel, Google Sheets тощо. Ця гнучкість дозволяє користувачам працювати з даними з різних джерел і форматів.
- Спеціальні підказки: користувачі можуть створювати власні підказки за допомогою простих інструкцій і коду Python. Ця функція дає змогу користувачам адаптувати свою взаємодію з даними відповідно до конкретних потреб і запитів.
- Зберегти зміни: можливість зберегти зміни, внесені до фреймів даних, гарантує збереження вашої роботи, і ви можете будь-коли переглянути та поділитися своїм аналізом.
- Спеціальні відповіді: можливість створення власних відповідей дозволяє користувачам визначати певну поведінку чи взаємодію, що робить інструмент ще більш універсальним.
- Інтеграція моделі: PandasAI підтримує різні мовні моделі, включно з моделями Hugging Face, Azure, Google Palm, Google VertexAI і LangChain. Ця інтеграція розширює можливості інструменту та забезпечує розширену обробку та розуміння природної мови.
- Вбудована підтримка LangChain: вбудована підтримка моделей LangChain додатково розширює спектр доступних моделей і функцій, підвищуючи глибину аналізу та розуміння, яке можна отримати з даних.
- Розуміти імена: PandasAI демонструє здатність розуміти кореляцію між назвами стовпців і реальною термінологією. Наприклад, навіть якщо ви використовуєте такі терміни, як «категорія продукту» замість «тип товару» у своїх підказках, інструмент все одно може надавати відповідні та точні результати. Ця гнучкість у розпізнаванні синонімів і зіставлення їх із відповідними стовпцями даних підвищує зручність для користувача та адаптивність інструменту до запитів природною мовою.
Хоча PandasAI пропонує кілька переваг, він також має деякі обмеження та проблеми, про які користувачі повинні знати:
Обмеження PandasAI
Ось деякі обмеження, які я помітив:
- Вимога до ключа API: щоб використовувати PandasAI, необхідно мати ключ API. Якщо у вашому обліковому записі OpenAI недостатньо кредитів, можливо, ви не зможете скористатися послугою. Однак варто зазначити, що OpenAI надає кредит у розмірі 5 доларів США для нових користувачів, що робить його доступним для тих, хто тільки починає користуватися платформою.
- Час обробки: іноді служба може затримуватись у наданні результатів, що можна пояснити великим використанням або навантаженням на сервер. Користувачі повинні бути готові до можливого часу очікування під час запиту до служби.
- Інтерпретація підказок: хоча ви можете задавати запитання за допомогою підказок, здатність системи пояснювати відповіді може бути не повністю розвиненою, і якість пояснень може відрізнятися. Цей аспект PandasAI може покращитися в майбутньому з подальшим розвитком.
- Чутливість підказок: користувачі повинні бути обережними, створюючи підказки, оскільки навіть незначні зміни можуть призвести до інших результатів. Ця чутливість до фраз і структури підказок може вплинути на послідовність результатів, особливо під час роботи з діаграмами даних або складнішими запитами.
- Обмеження щодо складних підказок: PandasAI може не обробляти дуже складні підказки чи запити так само ефективно, як простіші. Користувачі повинні пам’ятати про складність своїх запитань і переконатися, що інструмент підходить для їхніх конкретних потреб.
- Непослідовні зміни DataFrame: користувачі повідомляли про проблеми із внесенням змін до DataFrames, наприклад заповнення нульових значень або видалення рядків нульових значень, навіть якщо вказано «Inplace=True». Ця невідповідність може викликати розчарування у користувачів, які намагаються змінити свої дані.
- Змінні результати: під час перезапуску ядра або повторного запуску підказок можна отримати різні результати або інтерпретації даних із попередніх запусків. Ця мінливість може бути складною для користувачів, яким потрібні послідовні та відтворювані результати. Не застосовується до всіх підказок.
Ви можете завантажити набір даних тут.
Код доступний на GitHub.
Висновок
PandasAI пропонує зручний підхід до аналізу даних, доступний навіть тим, хто не має великих навичок програмування.
У цій статті я розповів, як налаштувати та використовувати PandasAI для аналізу даних, включаючи створення графіків, обробку нульових значень і використання переваг функції чату агента.
Підпишіться на нашу розсилку, щоб отримувати більше інформативних статей. Вам може бути цікаво дізнатися про моделі ШІ для створення генеративного ШІ.
Чи була ця стаття корисною?
Спасибі за ваш відгук!