Ефективне застосування Grep та Regex у Linux
Якщо ви вже певний час користуєтесь Linux, вам, ймовірно, знайома команда grep – інструмент для обробки тексту, що дозволяє здійснювати пошук у файлах та директоріях. Її корисність не викликає сумнівів, особливо для досвідчених користувачів Linux. Однак, використання grep без застосування регулярних виразів може значно обмежити її можливості.
Що ж таке Regex?
Regex, або регулярні вирази, є вдосконаленими шаблонами фільтрації вихідних даних, що розширюють пошукові можливості grep. Навчившись ефективно їх використовувати, ви зможете застосовувати регулярні вирази не лише з командою grep, а й з іншими командами Linux, що значно спростить та оптимізує вашу роботу з текстом.
У цій інструкції ми розглянемо, як ефективно застосовувати grep спільно з регулярними виразами.
Вимоги
Для ефективної роботи з grep та регулярними виразами потрібні базові знання Linux. Якщо ви початківець, рекомендуємо ознайомитися з нашими посібниками з Linux.
Вам також знадобиться комп’ютер або ноутбук з операційною системою Linux. Ви можете використовувати будь-який дистрибутив Linux за вашим вибором. Якщо ви використовуєте Windows, Linux можна запустити через WSL2. Докладніше про це можна дізнатися тут.
Для виконання команд, наведених у цьому посібнику, потрібен доступ до командного рядка/терміналу.
Крім того, вам знадобляться текстові файли для практичних прикладів. Для цього я використав ChatGPT, щоб створити текст про технології, попросивши його написати 400 слів, у яких би згадувалися різні технології, зокрема і з повторенням їхніх назв.
Згенерований текст я скопіював та зберіг у файлі tech.txt, який ми використовуватимемо протягом усього цього посібника.
Насамкінець, обов’язкове базове розуміння команди grep. Для оновлення своїх знань, ви можете переглянути 16 прикладів команд grep. Ми також коротко розглянемо команду grep для початківців.
Синтаксис та приклади команди grep
Синтаксис команди grep досить простий:
$ grep -options [regex/pattern] [files]
Як ви можете бачити, команда приймає шаблон та перелік файлів, в яких виконується пошук.
Існує багато різних параметрів grep, що змінюють її функціональність. Ось деякі з них:
- -i: ігнорувати регістр символів
- -r: виконувати рекурсивний пошук у піддиректоріях
- -w: шукати лише цілі слова
- -v: виводити рядки, що не відповідають шаблону
- -n: виводити номери рядків, у яких знайдено відповідність
- -l: виводити імена файлів, де знайдено збіг
- –color: виводити результати з кольоровим підсвічуванням
- -c: показує кількість збігів для використаного шаблону
#1. Пошук цілого слова
Для пошуку цілого слова використовуйте параметр -w. Це дозволяє уникнути рядків, що містять заданий шаблон як частину іншого слова.
$ grep -w ‘tech\|5G’ tech.txt
Як бачимо, ця команда шукає слова “5G” та “tech” у всьому тексті і позначає їх червоним кольором.
Тут символ | (вертикальна риска) екранується, щоб grep не обробляв його як метасимвол.
#2. Пошук без урахування регістру
Щоб виконати пошук без урахування регістру, використовуйте параметр -i.
$ grep -i ‘tech’ tech.txt
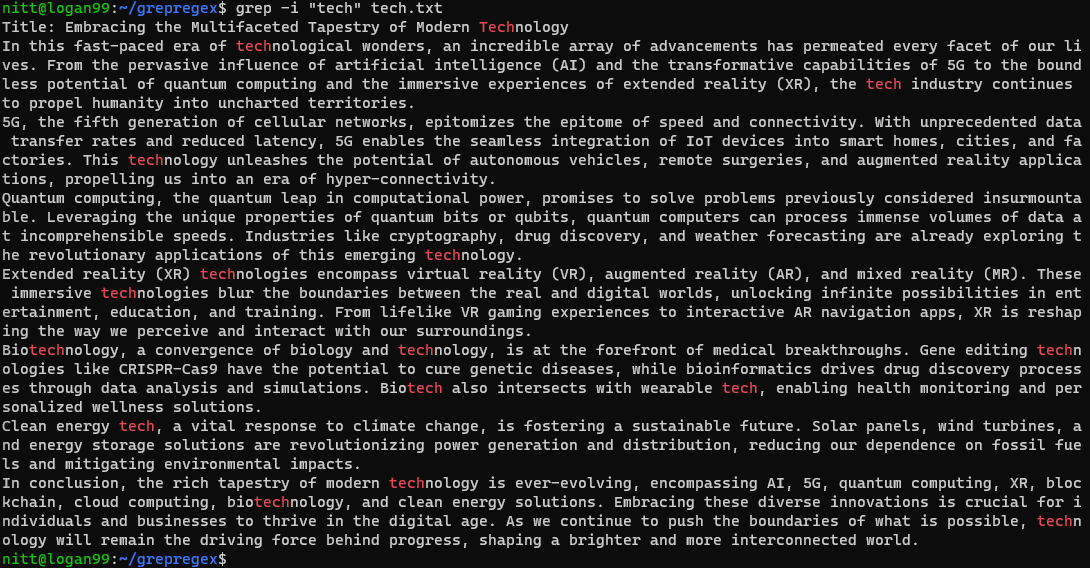
Ця команда шукає всі екземпляри “tech” незалежно від регістру, будь то повне слово або його частина.
#3. Пошук невідповідних рядків
Для відображення рядків, що не містять заданого шаблону, використовуйте параметр -v.
$ grep -v ‘tech’ tech.txt

Результат показує усі рядки, де немає слова “tech”. Також можна побачити порожні рядки, які є наслідком абзаців.
#4. Рекурсивний пошук
Для рекурсивного пошуку в директоріях використовуйте параметр -r.
$ grep -R ‘error\|warning’ /var/log/*.log
#output /var/log/bootstrap.log:2023-01-03 21:40:18 URL:http://ftpmaster.internal/ubuntu/pool/main/libg/libgpg-error/libgpg-erro 0_1.43-3_amd64.deb [69684/69684] -> "/build/chroot//var/cache/apt/archives/partial/libgpg-error0_1.43-3_amd64.deb" [1] /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 5 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 5 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 24 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 24 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: ignoring pre-dependency problem!
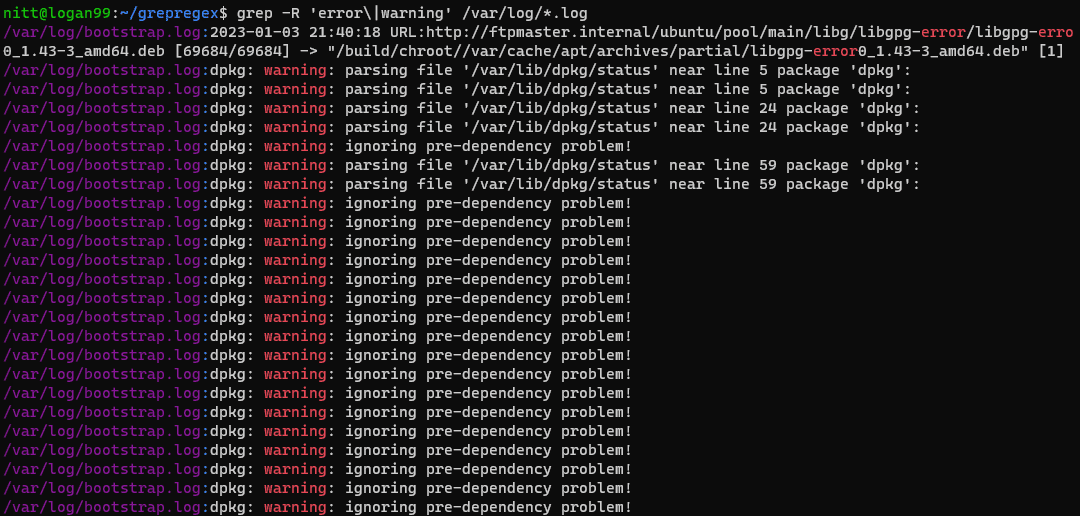
Ця команда рекурсивно шукає слова “error” та “warning” у файлах журналу в каталозі /var/log. Це корисний спосіб пошуку попереджень та помилок у файлах журналу.
Grep та Regex: що це і як їх використовувати
При роботі з регулярними виразами важливо знати, що вони пропонують три варіанти синтаксису:
- Базові регулярні вирази (BRE)
- Розширені регулярні вирази (ERE)
- Регулярні вирази, сумісні з Perl (PCRE)
Команда grep використовує BRE як параметр за замовчуванням. Для використання інших режимів регулярних виразів, їх потрібно вказати явно. Grep також обробляє метасимволи буквально, тому їх потрібно екранувати за допомогою зворотного слеша (\), якщо ви хочете, щоб вони виконували свою спеціальну функцію.
Синтаксис grep із регулярними виразами виглядає так:
$ grep [regex] [filenames]
Розглянемо практичні приклади застосування grep і regex.
#1. Пошук буквальних слів
Для пошуку буквального слова потрібно передати рядок як регулярний вираз. Адже слово само по собі також є регулярним виразом.
$ grep "technologies" tech.txt

Аналогічно можна використовувати буквальні збіги для пошуку поточних користувачів:
$ grep bash /etc/passwd
#output root:x:0:0:root:/root:/bin/bash nitt:x:1000:1000:,,,:/home/nitt:/bin/bash
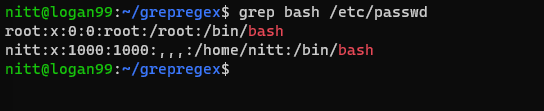
Це відобразить користувачів, які мають доступ до bash.
#2. Зіставлення прив’язки
Зіставлення прив’язки – це корисна техніка для розширеного пошуку. У регулярних виразах існують різні символи прив’язки, що представляють певні позиції у тексті. Ось деякі з них:
- Символ каретки “^”: він відповідає початку рядка або рядка введення.
- Символ долара “$”: він відповідає кінцю рядка або рядка введення.
Інші символи прив’язки включають межу слова “\b” та межу не слова “\B”.
- Межа слова ‘\b’: дозволяє встановити позицію між словом і символом, що не є словом. Це дозволяє знаходити цілі слова, уникаючи часткових збігів.
- Межа не слова ‘\B’: стверджує позицію, що не знаходиться між символами зі слова або без слова.
Розглянемо приклади для кращого розуміння.
$ grep ‘^From’ tech.txt

Введення слова або шаблону вимагає правильного регістру, оскільки grep чутливий до регістру. Отже, якщо виконати наступну команду, вона нічого не поверне:
$ grep ‘^from’ tech.txt
Аналогічно, можна використовувати символ $ для пошуку речення, що відповідає заданому шаблону.
$ grep ‘technology.$' tech.txt

Можна комбінувати символи ^ і $. Розглянемо приклад:
$ grep “^From \| technology.$” tech.txt
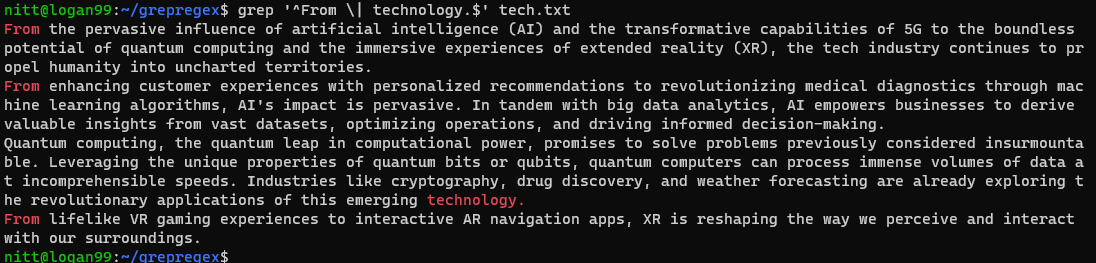
Результат містить речення, що починаються на “From”, і речення, що закінчуються на “technology”.
#3. Групування
Для пошуку кількох шаблонів одночасно використовуйте групування. Це допомагає створювати невеликі групи символів та шаблонів, що розглядаються як єдине ціле. Наприклад, можна створити групу (tech), яка включатиме “t”, “e”, “c”, “h”.
Для кращого розуміння розглянемо приклад:
$ grep 'technol\(ogy\)\?' tech.txt

За допомогою групування можна зіставляти повторювані шаблони, охоплювати групи та шукати альтернативи.
Альтернативний пошук з групуванням
Розглянемо приклад альтернативного пошуку.
$ grep "\(tech\|technology\)" tech.txt
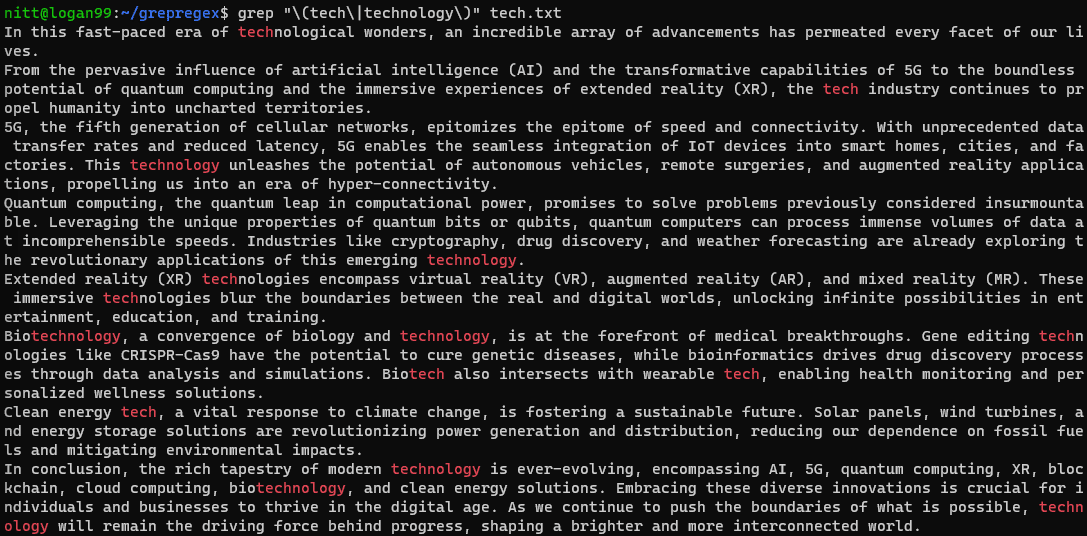
Якщо потрібно виконати пошук у рядку, передайте його за допомогою символу вертикальної лінії. Розглянемо приклад:
$ echo “tech technological technologies technical” | grep "\(tech\|technology\)"
#output “tech technological technologies technical”

Групи захоплення, групи без захоплення та повторювані шаблони
Що щодо захоплених та незахоплених груп?
Для захоплення груп потрібно створити групу в регулярному виразі та передати її в рядок або файл.
$ echo 'tech655 tech655nical technologies655 tech655-oriented 655' | grep "\(tech\)\(655\)"
#output tech655 tech655nical technologies655 tech655-oriented 655

Для груп без захоплення потрібно використовувати ?: у дужках.
Нарешті, розглянемо повторювані шаблони. Для їх перевірки потрібно змінити регулярний вираз.
$ echo ‘teach tech ttrial tttechno attest’ | grep '\(t\+\)'
#output
‘teach tech ttrial tttechno attest’
Тут регулярний вираз шукає один або більше символів “t”.
#4. Класи символів
За допомогою класів символів можна спростити написання регулярних виразів. Ці класи використовують квадратні дужки. Деякі відомі класи символів:
- [:digit:] – цифри від 0 до 9
- [:alpha:] – букви
- [:alnum:] – буквено-цифрові символи
- [:lower:] – літери нижнього регістру
- [:upper:] – літери верхнього регістру
- [:xdigit:] – шістнадцяткові цифри, включаючи 0-9, A-F, a-f
- [:blank:] – пробіли, такі як табуляція або пробіл
Розглянемо приклади:
$ grep [[:digit]] tech.txt

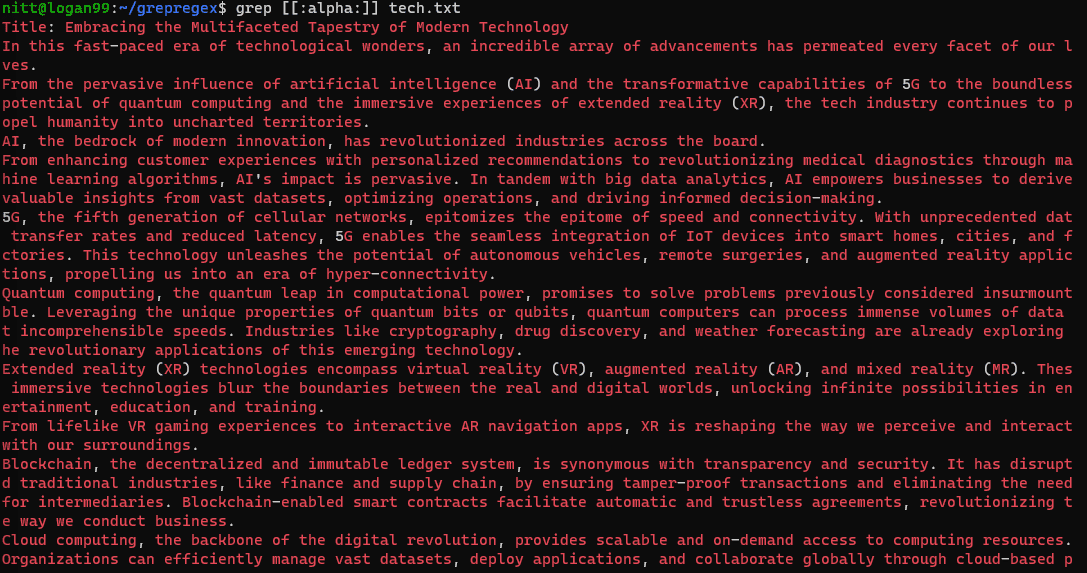
$ grep [[:alpha:]] tech.txt
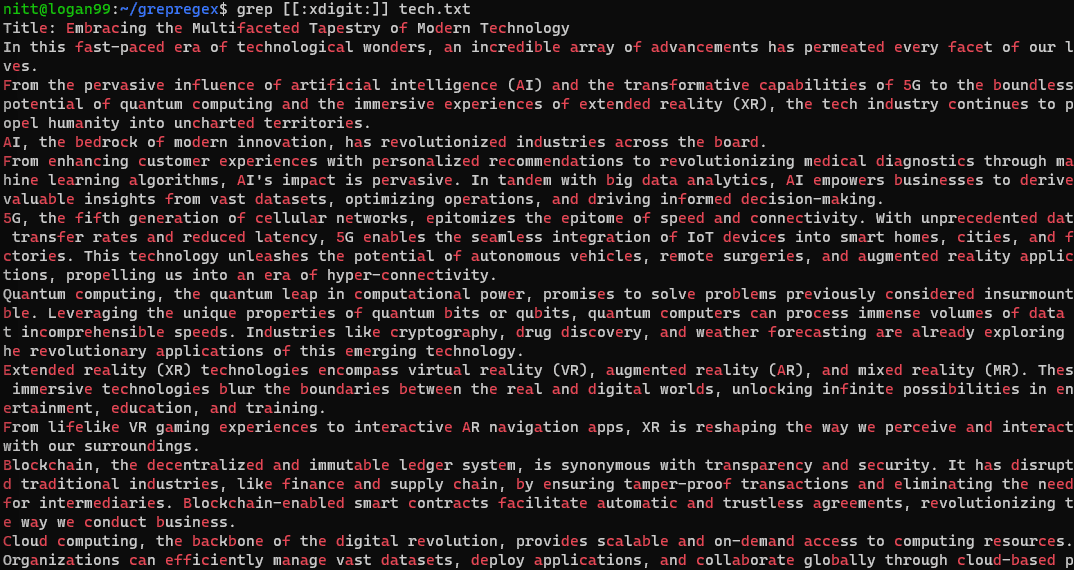
$ grep [[:xdigit:]] tech.txt
#5. Квантори
Квантори є метасимволами і є основою регулярного виразу. Вони дозволяють точно зіставляти зовнішній вигляд. Ось їхній перелік:
- * → нуль або більше збігів
- + → один або більше збігів
- ? → нуль або один збіг
- {x} → точно x збігів
- {x, } → x або більше збігів
- {x,z} → від x до z збігів
- {, z} → до z збігів
$ echo ‘teach tech ttrial tttechno attest’ | grep -E 't+'
#output
‘teach tech ttrial tttechno attest’
Тут він шукає екземпляри символу “t” для одного або кількох збігів. Параметр -E позначає розширений регулярний вираз (про що ми поговоримо далі).

#6. Розширений регулярний вираз
Якщо ви не бажаєте додавати контрольні символи до шаблону регулярного виразу, використовуйте розширений регулярний вираз. Він усуває необхідність в символах екранування. Для цього потрібно використовувати параметр -E.
$ grep -E 'in+ovation' tech.txt

#7. Використання PCRE для складних пошуків
PCRE (Regular Expression, сумісний з Perl) дозволяє робити набагато більше, ніж просто писати вирази. Наприклад, “\d” позначає [0-9].
Наприклад, ви можете використовувати PCRE для пошуку адрес електронної пошти.
echo "Contact me at [email protected]" | grep -P "\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}\b"
#output Contact me at [email protected]

PCRE забезпечує відповідність шаблону. Аналогічно можна використовувати шаблон PCRE для перевірки формату дати.
$ echo "The Sparkain site launched on 2023-07-29" | grep -P "\b\d{4}-\d{2}-\d{2}\b"
#output
The Sparkain site launched on 2023-07-29

Ця команда знаходить дату у форматі РРРР-ММ-ДД. Ви можете змінити його, щоб відповідати іншим форматам дати.
#8. Чергування
Для пошуку альтернативних збігів використовуйте символ вертикальної лінії (\|).
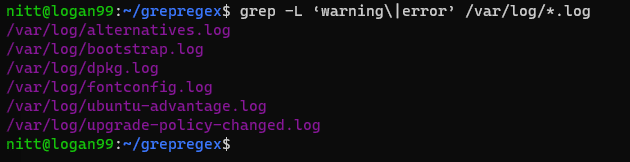
$ grep -L ‘warning\|error’ /var/log/*.log
#output /var/log/alternatives.log /var/log/bootstrap.log /var/log/dpkg.log /var/log/fontconfig.log /var/log/ubuntu-advantage.log /var/log/upgrade-policy-changed.log
Вихід містить список імен файлів, що містять “warning” або “error”.
Висновок
На цьому наш посібник із grep і regex закінчено. Ви можете використовувати grep у поєднанні з регулярними виразами для уточнення пошукових запитів. Правильне їх застосування значно заощадить ваш час та допоможе автоматизувати багато завдань, особливо при написанні сценаріїв або пошуку в тексті.
Далі рекомендуємо переглянути поширені питання та відповіді на співбесідах по Linux.