Структури даних DataFrames є основою роботи в мові програмування R, забезпечуючи необхідну структуру, гнучкість та інструменти для аналізу та обробки інформації. Їхня важливість є відчутною в багатьох областях, включаючи статистику, науку про дані, та прийняття рішень на основі даних у різноманітних галузях.
DataFrames створюють структуру та організацію, що дозволяє систематично та ефективно виявляти інсайти та приймати рішення, що базуються на даних.
У R, DataFrames організовані у формі таблиць, що складаються з рядків і стовпців. Кожен рядок відповідає окремому спостереженню, тоді як кожен стовпець відображає певну змінну. Така структура забезпечує легкість в організації та маніпулюванні даними. DataFrames можуть зберігати різноманітні типи даних, включаючи числові, текстові, та дати, що робить їх надзвичайно універсальними.
У цьому матеріалі ми розглянемо важливість DataFrames, а також процес їх створення за допомогою функції data.frame().
Ми також розглянемо різні методи обробки даних, навчимося створювати файли CSV та Excel, перетворювати інші формати даних в DataFrames та використовувати можливості бібліотеки tibble.
Ось декілька ключових причин, чому DataFrames є такими важливими в R:
Значення DataFrames

- Зберігання структурованих даних: DataFrames пропонують структурований, табличний формат для зберігання даних, що нагадує електронні таблиці. Цей формат спрощує управління та організацію інформації.
- Змішані типи даних: DataFrames здатні вміщувати різні типи даних в межах однієї структури. Можна створювати стовпці з числовими значеннями, текстовими рядками, факторами, датами і т.д. Ця універсальність важлива під час роботи з реальними даними.
- Організація даних: Кожен стовпець в DataFrame представляє окрему змінну, тоді як кожен рядок відповідає спостереженню або випадку. Таке впорядкування робить організацію даних більш зрозумілою, що покращує їхню чіткість.
- Імпорт та експорт даних: DataFrames підтримують імпорт та експорт даних з різних файлових форматів, наприклад CSV, Excel та баз даних. Це значно спрощує роботу із зовнішніми джерелами даних.
- Сумісність: DataFrames широко підтримуються різними пакетами та функціями R, забезпечуючи сумісність з іншими статистичними інструментами, інструментами для аналізу даних та бібліотеками. Це сприяє плавному інтегруванню в екосистему R.
- Обробка даних: R має розвинену екосистему пакетів, як, наприклад, “dplyr”. Ці пакети спрощують процеси фільтрації, трансформації та узагальнення даних, використовуючи DataFrames. Ця функція є критичною для очищення та підготовки даних.
- Статистичний аналіз: DataFrames є стандартним форматом даних для багатьох статистичних функцій та інструментів аналізу даних в R. Вони дозволяють ефективно проводити регресійний аналіз, перевірку гіпотез та багато іншого.
- Візуалізація: Інструменти візуалізації даних R, такі як ggplot2, ідеально працюють з DataFrames. Це дозволяє створювати інформативні діаграми та графіки для дослідження та представлення даних.
- Дослідження даних: DataFrames спрощують дослідження даних за допомогою підсумкової статистики, візуалізації та інших аналітичних методів. Це допомагає аналітикам та дослідникам краще розуміти характеристики даних, виявляти закономірності та аномалії.
Як створити DataFrame в R
Існує кілька способів створення DataFrame в R. Розглянемо деякі з найбільш поширених методів:
#1. Використання функції data.frame().
# Завантажуємо необхідну бібліотеку, якщо вона ще не завантажена
if (!require("dplyr")) {
install.packages("dplyr")
library(dplyr)
}
library(dplyr)
set.seed(42)
# Створюємо DataFrame з прикладом даних про продажі з реальними назвами продуктів
sales_data <- data.frame(
OrderID = 1001:1010,
Product = c("Laptop", "Smartphone", "Tablet", "Headphones", "Camera", "TV", "Printer", "Washing Machine", "Refrigerator", "Microwave Oven"),
Quantity = sample(1:10, 10, replace = TRUE),
Price = round(runif(10, 100, 2000), 2),
Discount = round(runif(10, 0, 0.3), 2),
Date = sample(seq(as.Date('2023-01-01'), as.Date('2023-01-10'), by="days"), 10)
)
# Виводимо DataFrame з даними про продажі
print(sales_data)
Розглянемо, як працює цей код:
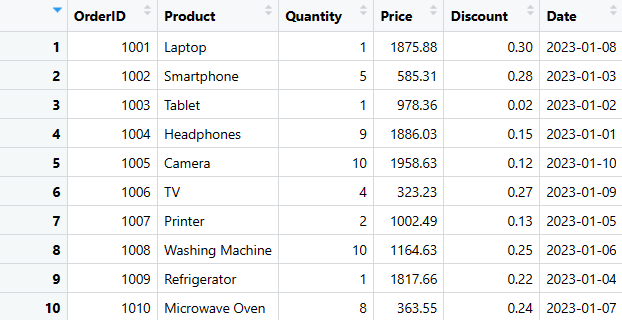 Sales_dataframe
Sales_dataframe
Це один з найпростіших способів створення DataFrame в R. Далі ми розглянемо, як витягувати, додавати, видаляти та вибирати певні стовпці або рядки, а також як узагальнювати дані.
Видобування стовпців
Існує два способи видобути потрібні стовпці з DataFrame:
- Можна використовувати індексацію для отримання останніх трьох стовпців DataFrame.
- Можна використовувати оператор $ для доступу до окремих стовпців за їхніми назвами.
Розглянемо обидва методи одночасно:
# Видобуваємо останні три стовпці (Discount, Price та Date) з DataFrame sales_data
last_three_columns <- sales_data[, c("Discount", "Price", "Date")]
# Виводимо видобуті стовпці
print(last_three_columns)
############################################# АБО #########################################################
# Видобуваємо останні три стовпці (Discount, Price та Date) за допомогою оператора $
discount_column <- sales_data$Discount
price_column <- sales_data$Price
date_column <- sales_data$Date
# Створюємо новий DataFrame з видобутими стовпцями
last_three_columns <- data.frame(Discount = discount_column, Price = price_column, Date = date_column)
# Виводимо видобуті стовпці
print(last_three_columns)
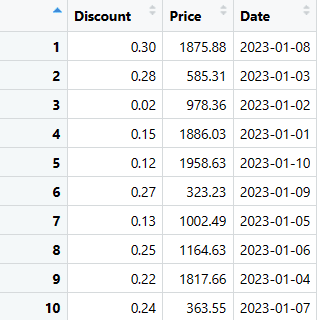
Ви можете використовувати будь-який з цих кодів для видобування необхідних стовпців.
Видобути рядки з DataFrame в R можна різними способами. Ось простий приклад:
# Видобуваємо певні рядки (3, 6 та 9) з DataFrame last_three_columns selected_rows <- last_three_columns[c(3, 6, 9), ] # Виводимо вибрані рядки print(selected_rows)
Також можна використовувати умови для видобування рядків:
# Видобуваємо та впорядковуємо рядки, які відповідають заданим умовам selected_rows <- sales_data %>% filter(Discount < 0.3, Price > 100, format(Date, "%Y-%m") == "2023-01") %>% arrange(OrderID) %>% select(Discount, Price, Date) # Виводимо вибрані рядки print(selected_rows)
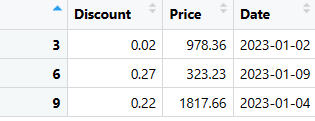 Видобуті рядки
Видобуті рядки
Додавання нового рядка
Для додавання нового рядка до існуючого DataFrame в R можна використовувати функцію rbind():
# Створюємо новий рядок як DataFrame
new_row <- data.frame(
OrderID = 1011,
Product = "Coffee Maker",
Quantity = 2,
Price = 75.99,
Discount = 0.1,
Date = as.Date("2023-01-12")
)
# Використовуємо функцію rbind() для додавання нового рядка до DataFrame
sales_data <- rbind(sales_data, new_row)
# Виводимо оновлений DataFrame
print(sales_data)
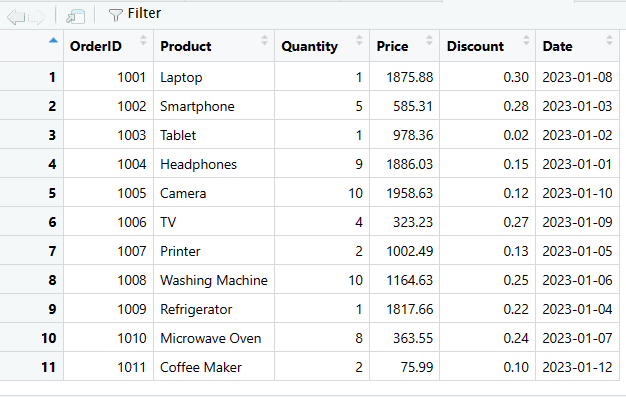 Додано новий рядок
Додано новий рядок
Додавання нового стовпця
Додати стовпець до DataFrame можна за допомогою простого коду. Тут ми додамо стовпець “PaymentMethod” до наших даних.
# Створюємо новий стовпець "PaymentMethod" зі значеннями для кожного рядка
sales_data$PaymentMethod <- c("Credit Card", "PayPal", "Cash", "Credit Card", "Cash", "PayPal", "Cash", "Credit Card", "Credit Card", "Cash", "Credit Card")
# Виводимо оновлений DataFrame
print(sales_data)
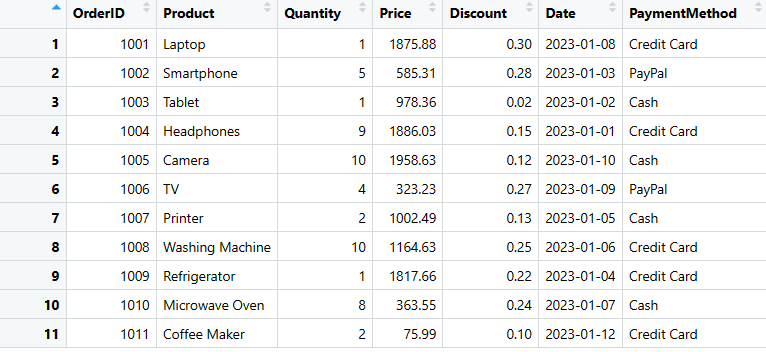 Стовпець додано до Dataframe
Стовпець додано до Dataframe
Видалення рядків
Якщо потрібно видалити непотрібні рядки, цей метод може бути корисним:
# Визначаємо рядок для видалення за OrderID row_to_delete <- sales_data$OrderID == 1010 # Виключаємо визначений рядок та створюємо новий DataFrame sales_data <- sales_data[!row_to_delete, ] # Виводимо оновлений DataFrame без видаленого рядка print(sales_data)
Видалення стовпців
Можна видалити стовпець з DataFrame в R, використовуючи пакет dplyr.
# install.packages("dplyr")
library(dplyr)
# Видаляємо стовпець "Discount" за допомогою функції select()
sales_data <- sales_data %>% select(-Discount)
# Виводимо оновлений DataFrame без стовпця "Discount"
print(sales_data)
Отримання зведення
Для отримання зведеної інформації про дані в R можна використовувати функцію summary(). Ця функція надає швидкий огляд центральних тенденцій та розподілу числових змінних в даних.
# Отримуємо зведену інформацію про дані data_summary <- summary(sales_data) # Виводимо зведену інформацію print(data_summary)
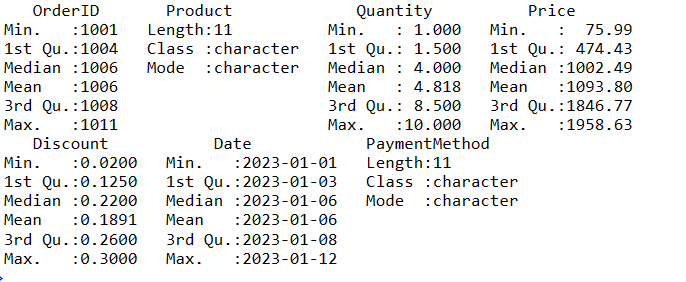
Це кілька кроків, які можна виконати для маніпулювання даними в DataFrame.
Перейдемо до другого методу створення DataFrame.
#2. Створення DataFrame в R з CSV файлу
Для створення DataFrame з CSV файлу можна використовувати функцію read.csv():
# Зчитуємо CSV файл в DataFrame
df <- read.csv("my_data.csv")
# Переглядаємо перші кілька рядків DataFrame
head(df)
Ця функція зчитує дані з CSV файлу та перетворює їх у DataFrame. Після цього можна працювати з даними в R.
# Встановлюємо та завантажуємо пакет readr, якщо він ще не встановлений
if (!requireNamespace("readr", quietly = TRUE)) {
install.packages("readr")
}
library(readr)
# Зчитуємо CSV файл в DataFrame
df <- read_csv("data.csv")
# Переглядаємо перші кілька рядків DataFrame
head(df)
Ви можете використовувати пакет readr для зчитування CSV файлів в R. Функція read_csv() з цього пакету часто використовується для цієї мети. Вона є швидшою, ніж звичайний метод.
#3. Використання функції as.data.frame().
Функція as.data.frame() дозволяє створювати DataFrame в R. Вона перетворює інші структури даних, такі як матриці або списки, в DataFrame.
Ось як її використовувати:
# Створюємо вкладений список для представлення даних
data_list <- list(
OrderID = 1001:1011,
Product = c("Laptop", "Smartphone", "Tablet", "Headphones", "Camera", "TV", "Printer", "Washing Machine", "Refrigerator", "Microwave Oven", "Coffee Maker"),
Quantity = c(1, 5, 1, 9, 10, 4, 2, 10, 1, 8, 2),
Price = c(1875.88, 585.31, 978.36, 1886.03, 1958.63, 323.23, 1002.49, 1164.63, 1817.66, 363.55, 75.99),
Discount = c(0.3, 0.28, 0.02, 0.15, 0.12, 0.27, 0.13, 0.25, 0.22, 0.24, 0.1),
Date = as.Date(c("2023-01-08", "2023-01-03", "2023-01-02", "2023-01-01", "2023-01-10", "2023-01-09", "2023-01-05", "2023-01-06", "2023-01-04", "2023-01-07", "2023-01-12")),
PaymentMethod = c("Credit Card", "PayPal", "Cash", "Credit Card", "Cash", "PayPal", "Cash", "Credit Card", "Credit Card", "Cash", "Credit Card")
)
# Перетворюємо вкладений список в DataFrame
sales_data <- as.data.frame(data_list)
# Виводимо DataFrame
print(sales_data)
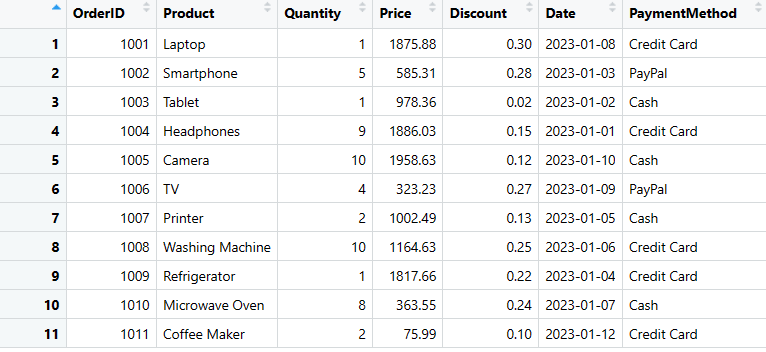 Sales_data
Sales_data
Цей метод дозволяє створити DataFrame без вказівки кожного стовпця окремо, і є особливо корисним, коли є великий обсяг даних.
#4. З існуючого DataFrame
Для створення нового DataFrame шляхом вибору певних стовпців або рядків з існуючого DataFrame, можна використовувати квадратні дужки [] для індексації. Ось як це працює:
# Вибираємо рядки та стовпці
sales_subset <- sales_data[c(1, 3, 4), c("Product", "Quantity")]
# Виводимо вибрану підмножину
print(sales_subset)
У цьому коді створюється новий DataFrame під назвою sales_subset, який містить певні рядки (1, 3 та 4) та стовпці (“Product” та “Quantity”) з DataFrame sales_data.
Можна налаштувати індекси та назви рядків і стовпців, щоб вибрати потрібні дані.
 Sales_Subset
Sales_Subset
#5. З вектора
Вектор – це одновимірна структура даних в R, що складається з елементів одного типу, таких як логічні, цілі, дійсні, символьні або інші типи.
DataFrame в R, навпаки, є двовимірною структурою, призначеною для зберігання даних у табличному форматі з рядками та стовпцями. Існують різні методи створення DataFrame з вектора, один з яких наведено нижче.
# Створюємо вектори для кожного стовпця
OrderID <- 1001:1011
Product <- c("Laptop", "Smartphone", "Tablet", "Headphones", "Camera", "TV", "Printer", "Washing Machine", "Refrigerator", "Microwave Oven", "Coffee Maker")
Quantity <- c(1, 5, 1, 9, 10, 4, 2, 10, 1, 8, 2)
Price <- c(1875.88, 585.31, 978.36, 1886.03, 1958.63, 323.23, 1002.49, 1164.63, 1817.66, 363.55, 75.99)
Discount <- c(0.3, 0.28, 0.02, 0.15, 0.12, 0.27, 0.13, 0.25, 0.22, 0.24, 0.1)
Date <- as.Date(c("2023-01-08", "2023-01-03", "2023-01-02", "2023-01-01", "2023-01-10", "2023-01-09", "2023-01-05", "2023-01-06", "2023-01-04", "2023-01-07", "2023-01-12"))
PaymentMethod <- c("Credit Card", "PayPal", "Cash", "Credit Card", "Cash", "PayPal", "Cash", "Credit Card", "Credit Card", "Cash", "Credit Card")
# Створюємо DataFrame, використовуючи data.frame()
sales_data <- data.frame(
OrderID = OrderID,
Product = Product,
Quantity = Quantity,
Price = Price,
Discount = Discount,
Date = Date,
PaymentMethod = PaymentMethod
)
# Виводимо DataFrame
print(sales_data)
У цьому коді створюються окремі вектори для кожного стовпця, а потім вони об’єднуються в DataFrame за допомогою функції data.frame(), під назвою sales_data.
Це дозволяє створити структуровану табличну форму даних з окремих векторів в R.
#6. З файлу Excel
Для створення DataFrame шляхом імпорту файлу Excel в R, можна використовувати сторонні пакети, такі як readxl, оскільки R не підтримує зчитування файлів CSV вбудованими засобами. Функція read_excel() є одним з таких інструментів для зчитування файлів Excel.
# Завантажуємо бібліотеку readxl library(readxl) # Вказуємо шлях до файлу Excel excel_file_path <- "your_file.xlsx" # Замініть на актуальний шлях до файлу # Зчитуємо файл Excel і створюємо DataFrame data_frame_from_excel <- read_excel(excel_file_path) # Виводимо DataFrame print(data_frame_from_excel)
Цей код зчитає файл Excel і збереже його дані в DataFrame в R, що дозволить працювати з цими даними.
#7. З текстового файлу
Функція read.table() в R може імпортувати текстовий файл в DataFrame. Для неї потрібні два важливі параметри: ім’я файлу та роздільник, що визначає, як розділені поля у файлі.
# Визначаємо ім'я файлу та роздільник file_name <- "your_text_file.txt" # Замініть на фактичне ім'я файлу delimiter <- "\t" # Замініть на фактичний роздільник (наприклад, "\t" для табуляції, "," для CSV) # Використовуємо функцію read.table() для створення DataFrame data_frame_from_text <- read.table(file_name, header = TRUE, sep = delimiter) # Виводимо DataFrame print(data_frame_from_text)
Цей код зчитує текстовий файл і перетворює його в DataFrame в R, що дозволяє аналізувати дані.
#8. Використання Tibble
Для створення DataFrame з використанням наданих векторів та бібліотеки tidyverse, виконайте наступні дії:
# Завантажуємо бібліотеку tidyverse
library(tidyverse)
# Створюємо tibble, використовуючи надані вектори
sales_data <- tibble(
OrderID = 1001:1011,
Product = c("Laptop", "Smartphone", "Tablet", "Headphones", "Camera", "TV", "Printer", "Washing Machine", "Refrigerator", "Microwave Oven", "Coffee Maker"),
Quantity = c(1, 5, 1, 9, 10, 4, 2, 10, 1, 8, 2),
Price = c(1875.88, 585.31, 978.36, 1886.03, 1958.63, 323.23, 1002.49, 1164.63, 1817.66, 363.55, 75.99),
Discount = c(0.3, 0.28, 0.02, 0.15, 0.12, 0.27, 0.13, 0.25, 0.22, 0.24, 0.1),
Date = as.Date(c("2023-01-08", "2023-01-03", "2023-01-02", "2023-01-01", "2023-01-10", "2023-01-09", "2023-01-05", "2023-01-06", "2023-01-04", "2023-01-07", "2023-01-12")),
PaymentMethod = c("Credit Card", "PayPal", "Cash", "Credit Card", "Cash", "PayPal", "Cash", "Credit Card", "Credit Card", "Cash", "Credit Card")
)
# Виводимо створений sales tibble
print(sales_data)
Цей код використовує функцію tibble() з бібліотеки tidyverse для створення DataFrame tibble під назвою sales_data. Формат tibble забезпечує більш інформативний вивід порівняно зі стандартним DataFrame в R.
Як ефективно використовувати DataFrames в R
Ефективне використання DataFrames є важливим для обробки та аналізу даних в R. DataFrames є базовою структурою даних, і їх створення та маніпулювання зазвичай відбувається за допомогою функції data.frame. Ось кілька порад для ефективної роботи:
- Переконайтеся, що ваші дані чисті та добре структуровані перед створенням DataFrame. Видаліть непотрібні рядки або стовпці, обробіть відсутні значення та переконайтеся, що типи даних є відповідними.
- Встановіть відповідні типи даних для стовпців (наприклад, числові, символьні, факторні, дата). Це може покращити використання пам’яті та швидкість обчислень.
- Використовуйте індексацію та підмножини для обробки менших частин даних. Функція підмножини() та оператор [ ] є корисними для цієї мети.
- Хоча attach() та detach() можуть бути зручними, вони також можуть призвести до неоднозначності та непередбачуваної поведінки.
- R оптимізований для векторизованих операцій. За можливості використовуйте векторизовані функції замість циклів для обробки даних.
- Вкладені цикли можуть бути повільними в R. Замість них спробуйте використовувати векторизовані операції або функції, такі як lapply або sapply.
- Великі DataFrames можуть споживати багато пам’яті. Розгляньте використання пакетів data.table або dtplyr, які більш ефективно використовують пам’ять для великих наборів даних.
- R має багато пакетів для обробки даних. Використовуйте такі пакети, як dplyr, tidyr та data.table для ефективної трансформації даних.
- Зведіть до мінімуму використання глобальних змінних, особливо при роботі з кількома DataFrames. Використовуйте функції та передавайте DataFrames як аргументи.
- При роботі зі зведеними даними використовуйте функції group_by() та summarise() з пакету dplyr для ефективного виконання обчислень.
- Для великих наборів даних розгляньте можливість використання паралельної обробки за допомогою пакетів, таких як parallel або foreach, щоб пришвидшити операції.
- При зчитуванні даних в R використовуйте функції, такі як readr або data.table::fread, замість базових функцій, таких як read.csv, для швидшого імпорту.
- Для дуже великих наборів даних розгляньте можливість використання систем баз даних або спеціалізованих форматів зберігання, таких як Feather, Arrow або Parquet.
Дотримуючись цих порад, ви зможете ефективно працювати з DataFrames в R, роблячи обробку та аналіз даних швидшими та легшими.
Заключні думки
Створення DataFrame в R є простим процесом, і існує багато різних методів. Ми розглянули важливість DataFrames і обговорили їх створення за допомогою функції data.frame().
Також ми вивчили методи обробки даних, створення файлів CSV та Excel, перетворення інших структур даних в DataFrames і використання бібліотеки tibble.
Можливо, вас також зацікавлять найкращі IDE для програмування на R.