Веб-скрейпінг – це ефективний метод для видобування даних з вебсайтів та їх автоматизованого опрацювання. Звісно, це можна робити вручну, але цей процес є досить виснажливим та займає багато часу. Інструменти для автоматичного веб-скрейпінгу роблять цей процес швидшим та продуктивнішим, часто при цьому є більш економічно вигідними.
Цікаво, що за допомогою функції IMPORTXML, Google Таблиці можуть стати вашим універсальним інструментом для збору даних з інтернету. Завдяки IMPORTXML можна без особливих зусиль видобувати дані з вебсторінок та використовувати їх для аналізу, підготовки звітів або будь-яких інших завдань, що потребують обробки даних.
Функція IMPORTXML в Google Таблицях
Google Таблиці пропонують вбудовану функцію під назвою IMPORTXML, яка дозволяє імпортувати дані з веб-форматів, таких як XML, HTML, RSS і CSV. Ця функція є особливо корисною, якщо вам потрібно збирати дані з вебсайтів без необхідності використовувати складне програмування.
Основний синтаксис IMPORTXML виглядає так:
=IMPORTXML(адреса_URL; запит_xpath)
- адреса_URL: Адреса вебсторінки, з якої потрібно отримати дані.
- запит_xpath: Запит XPath, який конкретизує дані, які потрібно отримати.
XPath (XML Path Language) – це мова, яка використовується для навігації по XML-документах, включно з HTML. Це дає можливість точно вказати місце розташування необхідних даних у структурі HTML. Розуміння запитів XPath є ключовим для ефективного використання IMPORTXML.
Розуміння XPath
XPath пропонує різноманітні функції та вирази для навігації та фільтрації даних у HTML-документі. Повний опис XML та XPath виходить за рамки цієї статті, тому ми зосередимось на деяких основних принципах XPath:
- Вибір елементів: Ви можете вибирати елементи, використовуючи / та // для позначення шляхів. Наприклад, /html/body/div вибере всі елементи div у тілі документа.
- Вибір атрибутів: Для вибору атрибутів використовується символ @. Наприклад, //@href вибере всі атрибути href на сторінці.
- Фільтри-предикати: Ви можете фільтрувати елементи за допомогою предикатів, що беруться в квадратні дужки ([ ]). Наприклад, /div[@class=”container”] вибере всі елементи div з класом “container”.
- Функції: XPath має ряд функцій, таких як contains(), starts-with() та text(), що дозволяють виконувати певні дії, наприклад, перевірку текстового контенту або значень атрибутів.
Тепер ви знайомі з синтаксисом IMPORTXML, знаєте URL вебсайту та розумієте, який елемент хочете вилучити. Але як отримати XPath елемента?
Необов’язково знати структуру вебсайту напам’ять, щоб отримати дані за допомогою IMPORTXML. Кожен сучасний браузер має інструмент, який дозволяє швидко скопіювати XPath будь-якого елемента.
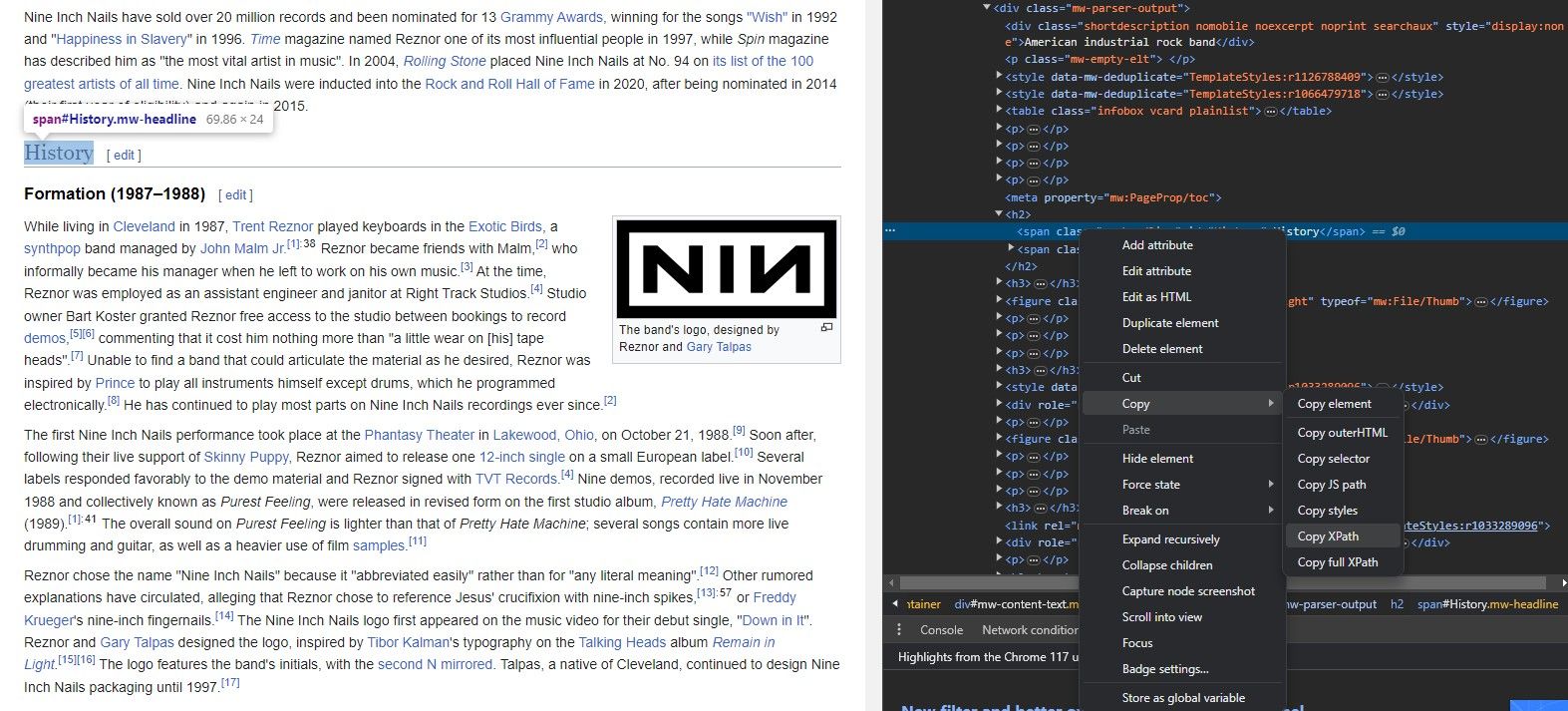
Інструмент “Перевірити елемент” дозволяє отримувати XPath з елементів вебсайту. Ось як це працює:
Тепер, коли ви маєте все необхідне, давайте розглянемо IMPORTXML в дії та видобудемо декілька посилань.
Як видобути посилання з вебсайту за допомогою IMPORTXML
Ви можете використовувати IMPORTXML для збору різноманітних даних з вебсайтів. Це стосується посилань, відео, зображень та майже будь-якого елемента вебсайту. Посилання є одним з найважливіших елементів у веб-аналізі, і ви можете багато дізнатися про вебсайт, просто аналізуючи сторінки, на які він посилається.
IMPORTXML дозволяє швидко видобувати посилання в Google Таблицях, а потім аналізувати їх за допомогою різноманітних функцій Google Таблиць.
1. Видобування усіх посилань
Для того, щоб видобути усі посилання з вебсторінки, ви можете використовувати наступну формулу:
=IMPORTXML(адреса_URL; "//a/@href")
Цей запит XPath вибирає всі атрибути href елементів, фактично вилучаючи всі посилання на сторінці.
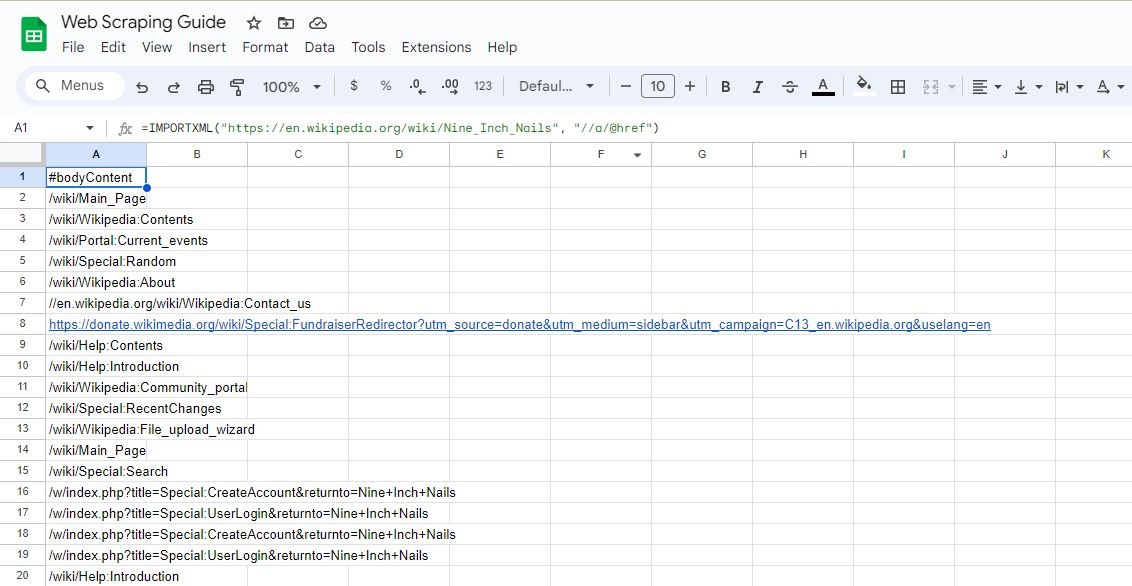
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails"; "//a/@href")
Наведена вище формула збирає усі посилання зі статті у Вікіпедії.
Рекомендується вводити URL вебсторінки в окрему комірку, а потім посилатися на неї. Це допоможе зробити вашу формулу коротшою та простішою. Аналогічно можна вчинити і з запитом XPath.
2. Видобування усіх текстів посилань
Для отримання тексту посилань разом з їх URL, ви можете використовувати:
=IMPORTXML(адреса_URL; "//a")
Цей запит вибирає всі елементи і ви можете отримати текст посилання та URL-адресу з результатів.
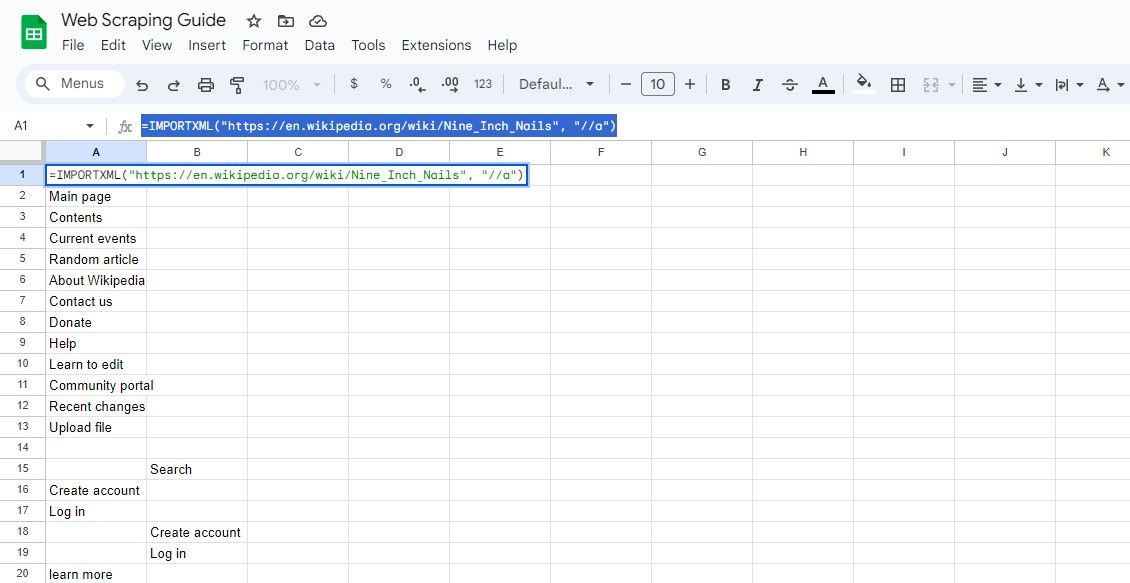
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails"; "//a")
Наведена вище формула збирає тексти посилань у цій же статті Вікіпедії.
Як видобути певні посилання з вебсайту за допомогою IMPORTXML
Іноді вам може знадобитися видобути певні посилання на основі заданих критеріїв. Наприклад, вам можуть бути цікаві посилання, що містять певне ключове слово, або посилання з конкретного розділу вебсторінки.
Завдяки належному розумінню XPath, ви можете точно визначити потрібний вам елемент.
1. Видобування посилань, що містять ключове слово
Для видобування посилань, що містять певне ключове слово, можна використовувати функцію contains() XPath:
=IMPORTXML(адреса_URL; "//a[contains(@href; 'ключове_слово')]/@href")
Цей запит вибирає атрибути href елементів, де href містить задане ключове слово.
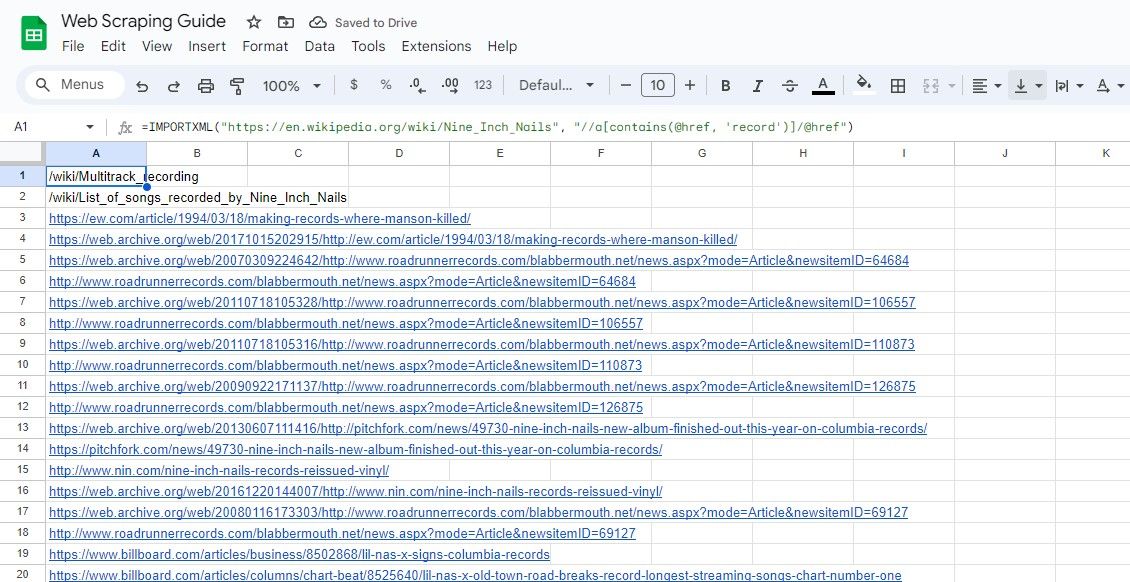
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails"; "//a[contains(@href; 'record')]/@href")
Наведена вище формула видобуває всі посилання, що містять слово “record” у тексті зразкової статті Вікіпедії.
2. Видобування посилань з розділу
Для того, щоб видобути посилання з певного розділу сторінки, ви можете вказати XPath цього розділу. Наприклад:
=IMPORTXML(адреса_URL; "//div[@class="розділ"]//a/@href")
Цей запит вибирає атрибути href елементів у елементах div з класом “розділ”.
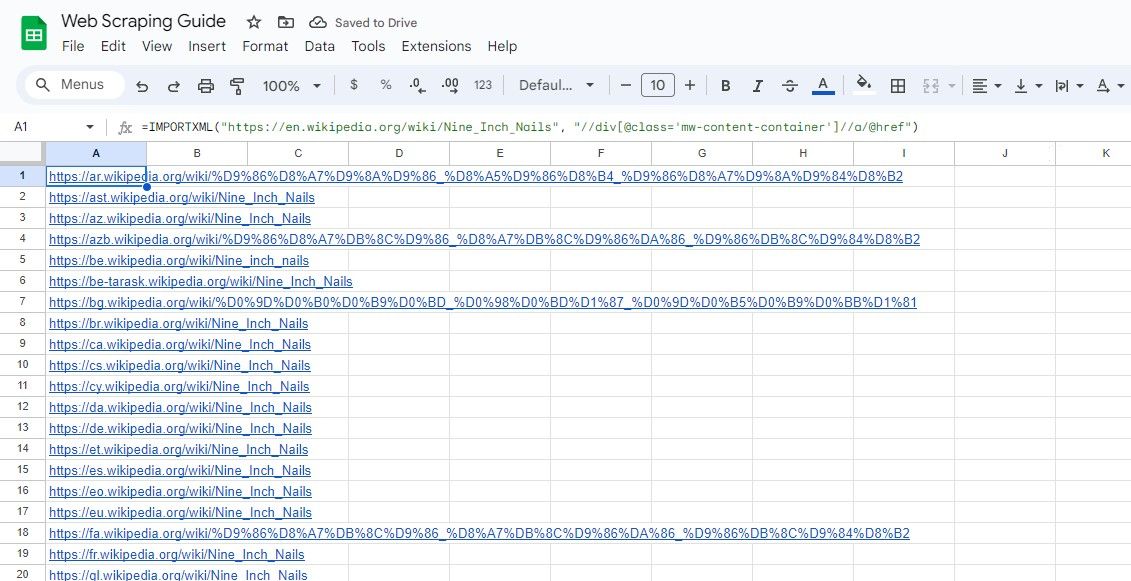
Аналогічно, наведена нижче формула вибирає усі посилання в класі div, що має клас “mw-content-container”:
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails"; "//div[@class="mw-content-container"]//a/@href")
Варто зазначити, що IMPORTXML можна використовувати не тільки для веб-скрейпінгу. Ви можете використовувати сімейство функцій IMPORT для імпорту таблиць даних з вебсайтів в Google Таблиці.
Хоча Google Таблиці та Excel мають багато спільних функцій, сімейство функцій IMPORT є унікальним для Google Таблиць. Тому, для імпорту даних з вебсайтів в Excel вам потрібно використовувати інші підходи.
Спростіть веб-скрейпінг за допомогою Google Таблиць
Веб-скрейпінг за допомогою Google Таблиць і функції IMPORTXML є універсальним та доступним способом збору даних з вебсайтів.
Оволодівши XPath і навчившись створювати ефективні запити, ви можете повністю розкрити потенціал IMPORTXML та отримувати цінну інформацію з веб-ресурсів. Отже, почніть скрейпінг і виведіть свій веб-аналіз на новий рівень!