Команда `grep` у Linux – це потужний інструмент для пошуку текстових рядків та шаблонів у файлах. Вона дозволяє знаходити відповідні рядки серед великої кількості даних, а також працює з виводом інших команд через конвеєр. Розглянемо детальніше, як саме використовувати цю утиліту.
Історія виникнення grep
Команда `grep` завоювала популярність у світі Linux і Unix завдяки кільком факторам. По-перше, вона відрізняється високою корисністю. По-друге, її можливості настільки широкі, що можуть вразити навіть досвідчених користувачів. І, по-третє, її створили протягом однієї ночі для вирішення конкретного завдання. Перші два пункти є очевидними, а третій – дещо несподіваним.
Кен Томпсон, витягнувши функціонал пошуку за регулярними виразами з редактора `ed` (вимовляється “і-ді”), створив невелику програму для персонального використання з метою пошуку в текстових файлах. Його керівник у Bell Labs, Дуг Макілрой, звернувся до Томпсона, описавши проблему, з якою зіткнувся один з їхніх колег, Лі Макмехон.
Макмехон проводив текстовий аналіз для ідентифікації авторів “Федералістських документів”. Йому потрібен був інструмент, який би дозволяв шукати фрази та рядки в текстових файлах. Того ж вечора Томпсон протягом приблизно години перетворив свій особистий інструмент на загальнодоступну утиліту, яку назвав `grep`. Назва походить від командного рядка редактора `ed` – `g/re/p`, що означає “глобальний пошук за регулярними виразами”.
Ви можете знайти відео, де Томпсон розповідає про народження `grep` Браяну Кернігану.
Простий пошук за допомогою grep
Для пошуку конкретного рядка у файлі, введіть у командному рядку пошуковий термін і назву файлу:

Відобразяться рядки, що містять вказаний термін. У наведеному прикладі це лише один рядок. Знайдений текст буде виділено, оскільки в більшості дистрибутивів Linux для `grep` встановлено псевдонім:
alias grep='grep --colour=auto'
Розглянемо випадок, коли збігається кілька рядків. Шукаємо слово “Середнє” у файлі журналу програми. Оскільки ми не знаємо, чи записане слово з великої чи малої літери, використаємо параметр `-i` (ігнорувати регістр):
grep -i Average geek-1.log

Буде виведено кожен рядок, який містить слово “середнє” у будь-якому регістрі, і відповідний текст буде підсвічено.
Для виведення рядків, які *не* містять заданого терміну, використовуйте параметр `-v` (інвертувати збіг):
grep -v Mem geek-1.log

Текст не буде виділено, оскільки відображаються лише рядки, що не відповідають пошуковому запиту.
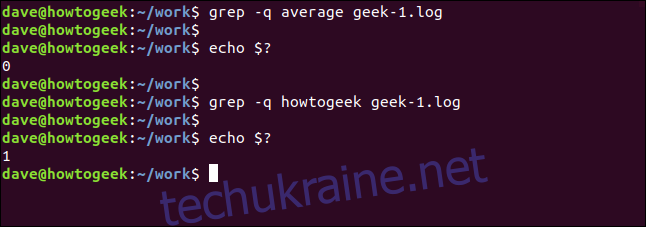
Можна зробити так, щоб `grep` працював у безшумному режимі. Результат його роботи повертається в оболонку як значення. Нульовий результат означає, що рядок знайдено, одиничний – що не знайдено. Код повернення можна перевірити за допомогою спеціального параметра `$?`:
grep -q average geek-1.log
echo $?
grep -q wdzwdz geek-1.log
echo $?
Рекурсивний пошук за допомогою grep
Для пошуку у вкладених папках використовуйте параметр `-r` (рекурсивний). Зауважте, що потрібно вказати шлях, а не ім’я файлу. Наприклад, шукаємо у поточному каталозі “.” та у всіх його підпапках:
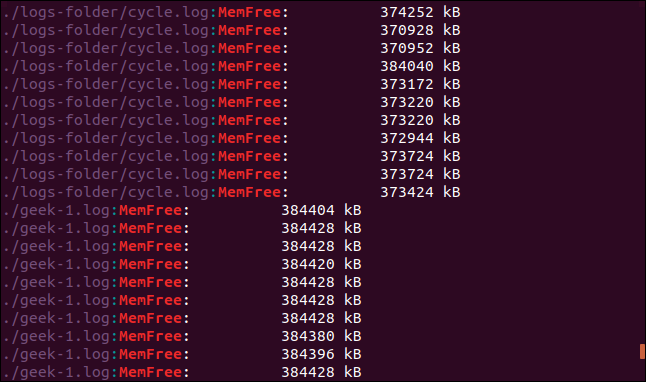
grep -r -i memfree .

Вивід міститиме назви папок та файлів для кожного знайденого рядка.
`grep` може переходити за символічними посиланнями, якщо використовувати параметр `-R` (рекурсивне розіменування). У цьому прикладі є символічне посилання `logs-folder`, яке вказує на `/home/dave/logs`.
ls -l logs-folder

Повторимо попередній пошук, але з параметром `-R`:
grep -R -i memfree .

Тепер пошук буде проведено також і в каталозі, на який вказує символічне посилання.
Пошук цілих слів
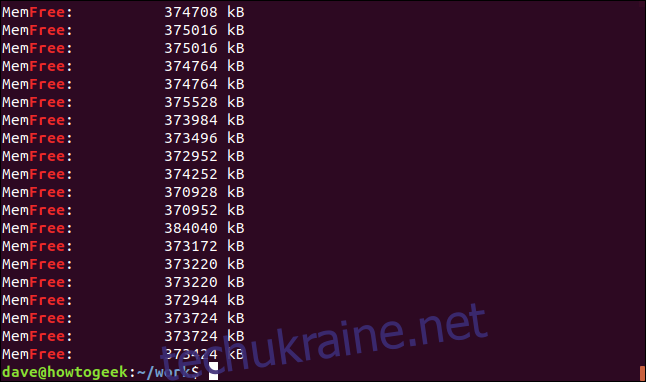
За замовчуванням `grep` знаходить рядки, які містять пошуковий термін будь-де, навіть всередині іншого слова. Розглянемо приклад: пошук слова “free”.
grep -i free geek-1.log

У результатах є рядки, що містять “free”, але це не окремі слова, а частина слова “MemFree”.
Щоб `grep` шукав тільки окремі слова, використовуйте параметр `-w` (регулярний вираз слова).
grep -w -i free geek-1.log
echo $?
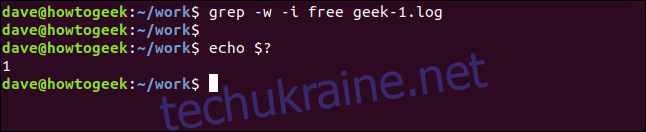
Цього разу результатів немає, оскільки окреме слово “free” не зустрічається у файлі.
Використання кількох пошукових термінів
Параметр `-E` (розширений регулярний вираз) дозволяє шукати декілька слів. Цей параметр є аналогом застарілої команди `egrep`.
Наступна команда шукає два слова: “середній” та “вільна пам’ять”.
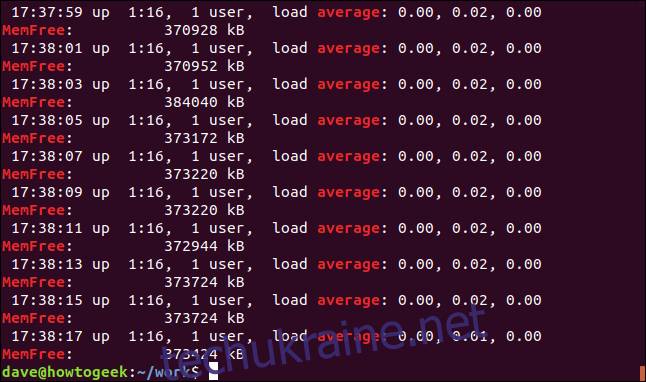
grep -E -w -i "average|memfree" geek-1.log

Виводяться рядки, що містять будь-який з цих термінів.
Можна шукати як окремі слова, так і фрагменти слів.
Параметр `-e` дозволяє використовувати кілька пошукових термінів у командному рядку. Також можна використовувати дужки регулярних виразів, наприклад `[]`, щоб створити шаблон. У цьому випадку `grep` буде шукати рядки, що містять `kB` або `KB`.

Знайдено обидва рядки, причому деякі містять обидва варіанти.
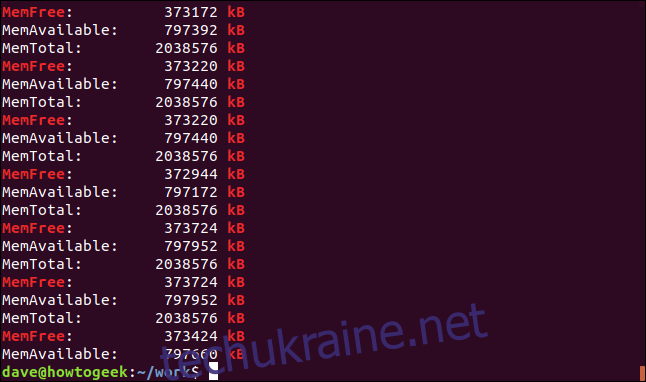
Точно відповідні лінії
`-x` (рядковий регулярний вираз) знаходить рядки, де *весь* рядок збігається з пошуковим терміном. Наприклад, пошукаємо мітку дати та часу, яка, як відомо, зустрічається лише один раз:
grep -x "20-Jan--06 15:24:35" geek-1.log

Знайдено та виведено один відповідний рядок.
Можна виводити лише рядки, які *не* збігаються. Це зручно, коли переглядаєте файли конфігурації, де коментарі часто ускладнюють пошук потрібних налаштувань. Ось приклад з файлом `/etc/sudoers`:
За допомогою наступної команди ми виключимо рядки коментарів:
sudo grep -v "https://www.wdzwdz.com/496056/how-to-use-the-grep-command-on-linux/#" /etc/sudoers
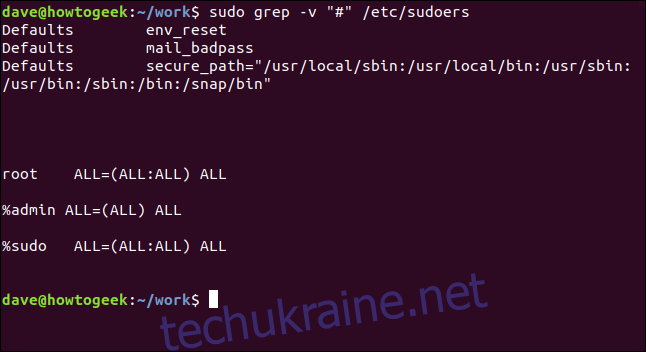
Результат значно зручніший для аналізу.
Відображення лише відповідного тексту
Іноді потрібно виводити не весь рядок, а лише сам текст, який відповідає пошуковому терміну. Для цього використовується параметр `-o` (тільки відповідний).
grep -o MemFree geek-1.log

Виводиться лише текст, який відповідає заданому терміну.

Підрахунок за допомогою grep
`grep` також надає числову інформацію. За допомогою параметра `-c` можна підрахувати, скільки разів термін з’являється у файлі:
grep -c average geek-1.log

`grep` повідомляє, що термін “average” зустрічається у файлі 240 разів.
Щоб вивести номер рядка для кожного збігу, використовуйте параметр `-n`.
grep -n Jan geek-1.log

Номер рядка відображається на початку кожного відповідного рядка.
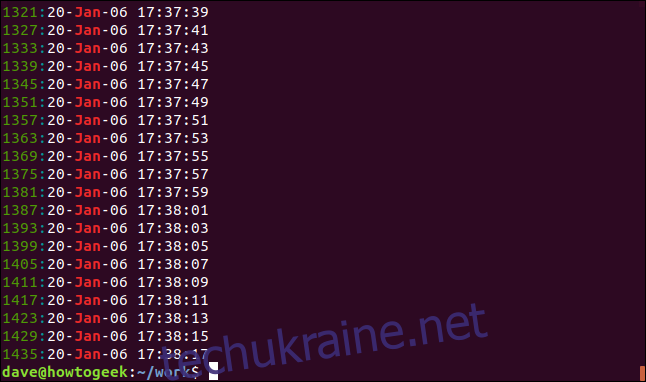
Для обмеження кількості виведених результатів використовуйте параметр `-m` (максимальна кількість). Наприклад, виведемо лише перші 5 рядків:
grep -m5 -n Jan geek-1.log
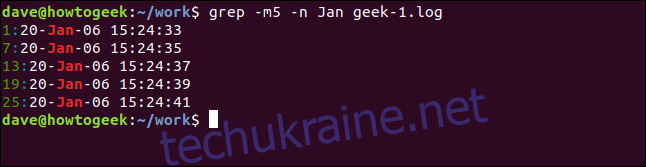
Додавання контексту
Часто корисно бачити додаткові (можливо, невідповідні) рядки для кожного збігу. Це допомагає зрозуміти, які рядки є найбільш цікавими.
Для виведення рядків *після* збігу використовуйте параметр `-A` (після контексту). Наприклад, виведемо 3 рядки після відповідного:
grep -A 3 -x "20-Jan-06 15:24:35" geek-1.log
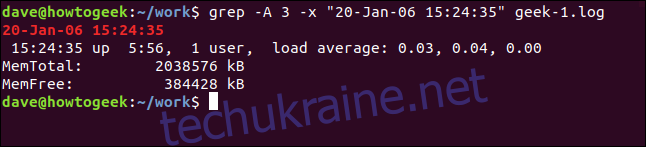
Щоб вивести рядки *перед* збігом, використовуйте параметр `-B` (контекст перед).
grep -B 3 -x "20-Jan-06 15:24:35" geek-1.log
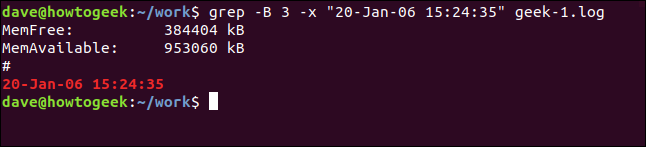
Для виведення рядків *до і після* збігу використовуйте параметр `-C` (контекст).
grep -C 3 -x "20-Jan-06 15:24:35" geek-1.log
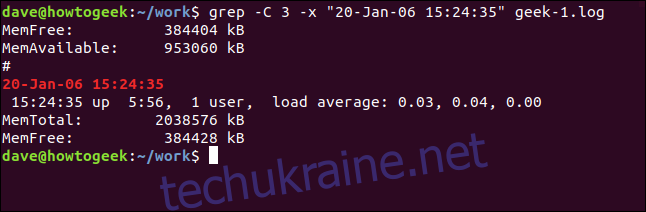
Відображення відповідних файлів
Щоб побачити назви файлів, що містять пошуковий термін, використовуйте параметр `-l` (файли зі збігом). Наприклад, дізнаємося, які C-файли містять посилання на заголовок `sl.h`:
grep -l "sl.h" *.c

Виводяться лише назви файлів, а не самі відповідні рядки.

Аналогічно, можна шукати файли, які *не* містять заданий термін, за допомогою параметра `-L` (файли без відповідності).
grep -L "sl.h" *.c

Початок і кінець рядків
`grep` може знаходити збіги лише на початку або в кінці рядка. Символ `^` відповідає початку рядка. Знайдемо рядки, що починаються з пробілу:
grep "^ " geek-1.log

Відобразяться рядки, що починаються з пробілу.
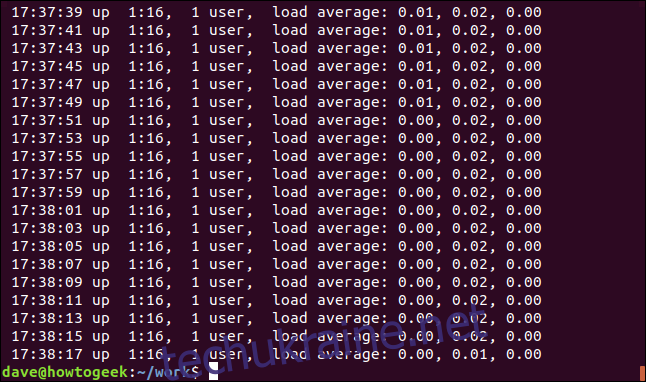
Для відповідності кінцю рядка використовуйте символ `$`. Знайдемо рядки, що закінчуються на “00”:
grep "00$" geek-1.log

Виводяться рядки, що закінчуються на “00”.
Використання Pipes з grep
`grep` можна використовувати у конвеєрах з іншими командами, перенаправляючи її вихід та вхід.
Наприклад, щоб побачити усі згадки рядка “ExtractParameters” у вихідних C-файлах, але у меншому обсязі, можна скористатися командою:
grep "ExtractParameters" *.c | less

Результат буде виведений за допомогою утиліти `less`.
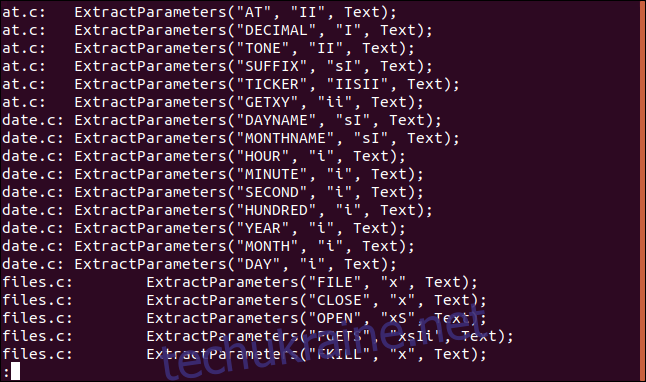
Це дозволить переглядати список файлів та використовувати можливості пошуку `less`.
Якщо перенаправити вивід `grep` до `wc` і використати параметр `-l`, то можна підрахувати кількість рядків у вихідних файлах, що містять “ExtractParameters”. Хоча це можна зробити і за допомогою `grep -c`, це гарний спосіб продемонструвати роботу конвеєра:
grep "ExtractParameters" *.c | wc -l

Наступна команда перенаправляє вихід `ls` до `grep`, а потім до `sort`. Вона виводить файли у поточному каталозі, відбираючи ті, що містять “Aug”, і сортує їх за розміром:
ls -l | grep "Aug" | sort +4n
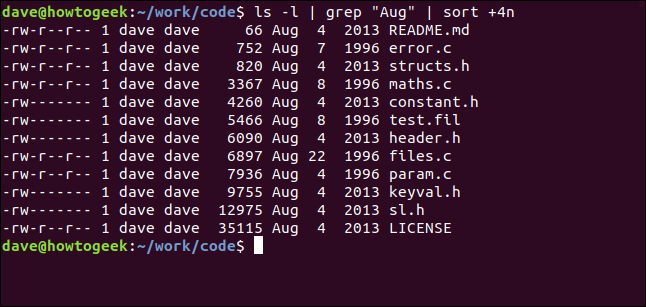
Розглянемо цю команду детальніше:
- `ls -l`: Виводить довгий список файлів у поточному каталозі.
- `grep “Aug”`: З цього списку відбирає рядки, що містять “Aug”. Зверніть увагу, що це також знайде файли, які мають “Aug” у своїй назві.
- `sort +4n`: Сортує вивід `grep` по четвертому стовпчику (розмір файлу).
Таким чином, виводиться список файлів, змінених у серпні (незалежно від року), відсортований за розміром.
grep: Більше, ніж команда, ваш надійний союзник
`grep` – це чудовий інструмент, який має бути в арсеналі кожного користувача Linux. Існує з 1974 року, і досі актуальний завдяки своїй ефективності та корисності.
Поєднання `grep` з можливостями регулярних виразів відкриває ще більші горизонти для пошуку та аналізу даних.