Розберімося з усіма тонкощами дослідницького аналізу даних, важливого процесу, що використовується для виявлення трендів, закономірностей та узагальнення масивів даних за допомогою статистичних висновків і наочних графічних матеріалів.
Як і будь-який інший науковий проект, робота з даними – це тривалий процес, що вимагає часу, високого рівня організації та ретельного виконання декількох етапів. Одним з найважливіших кроків у цьому процесі є дослідницький аналіз даних (EDA).
Тому в цій статті ми детальніше розглянемо, що саме представляє собою дослідницький аналіз даних і яким чином його можна здійснити за допомогою мови програмування R!
Що таке розвідувальний аналіз даних?
Розвідувальний аналіз даних (EDA) передбачає перевірку та вивчення характеристик набору даних до його подальшої обробки, будь то в бізнесі, статистиці чи машинному навчанні.
Цей короткий огляд природи інформації та її основних особливостей зазвичай проводиться за допомогою візуальних методів, таких як графіки та таблиці. Практичне застосування EDA необхідне для оцінки потенціалу даних, які згодом підлягатимуть складнішій обробці.
Таким чином, EDA дає змогу:
- Сформулювати припущення щодо використання наявної інформації;
- Дослідити приховані аспекти структури даних;
- Визначити відсутні значення, відхилення або нетипову поведінку;
- Виявити тенденції та значущі змінні в наборі даних;
- Відсіяти нерелевантні змінні або ті, що корелюють з іншими;
- Визначити відповідні методи моделювання, які будуть застосовані.
Яка відмінність між описовим та розвідувальним аналізом даних?
Існують два основні види аналізу даних: описовий та розвідувальний аналіз даних. Хоча вони мають різні цілі, вони тісно пов’язані.
Перший тип аналізу, описовий, зосереджується на описі поведінки змінних, наприклад, обчислення середнього значення, медіани, моди тощо.
Натомість, розвідувальний аналіз даних спрямований на виявлення зв’язків між змінними, отримання початкових уявлень про дані та направлення процесу моделювання в напрямку найпоширеніших парадигм машинного навчання: класифікація, регресія та кластеризація.
Обидва типи аналізу можуть використовувати графічне представлення даних, але лише розвідувальний аналіз прагне до практичних висновків, тобто таких, що спонукають до дій особу, що приймає рішення.
Отже, якщо розвідувальний аналіз даних має на меті вирішення проблем та надання рішень для етапів моделювання, то описовий аналіз, як випливає з назви, створює детальний опис наявного набору даних.
| Описовий аналіз | Розвідувальний аналіз даних |
| Аналізує поведінку | Аналізує поведінку та взаємозв’язки |
| Надає резюме | Надає конкретні висновки |
| Організовує дані у таблицях та графіках | Впорядковує дані у таблицях та графіках |
| Не має значної пояснювальної сили | Має значну пояснювальну силу |
Приклади практичного застосування EDA
#1. Цифровий маркетинг
Сфера цифрового маркетингу перетворилася з процесу, що базується на творчості, на процес, що керується даними. Маркетингові компанії використовують розвідувальний аналіз даних для оцінки результатів кампаній або інших зусиль, керування інвестиціями, а також для прийняття рішень щодо цільового призначення.
Демографічні дослідження, сегментація споживачів та інші методи дозволяють маркетологам використовувати великі обсяги даних, таких як покупки споживачів, опитування та панельні дослідження, для розробки маркетингової стратегії.
Веб-аналітика дає маркетологам можливість отримувати інформацію про взаємодію користувачів із веб-сайтом на рівні сеансу. Google Analytics є безкоштовним і популярним інструментом аналітики, який маркетологи використовують з цією метою.
Методи розвідувального аналізу, що часто використовуються в маркетингу, включають в себе моделювання комплексу маркетингу, аналіз ціноутворення та просування, оптимізацію продажів та дослідження клієнтів, наприклад, сегментація.
#2. Розвідувальний аналіз портфеля
Поширеним застосуванням розвідувального аналізу даних є аналіз портфеля. Банк або кредитна установа мають набір рахунків з різною вартістю та рівнем ризику.
Рахунки можуть відрізнятися залежно від соціального статусу власника (заможний, середній клас, малозабезпечений тощо), географічного розташування, власного капіталу та багатьох інших факторів. Кредитодавець має збалансувати прибутковість кредиту з ризиком його непогашення. Виникає питання, як оцінити портфель в цілому.
Кредити з найменшим ризиком можуть бути надані заможним людям, але кількість таких людей дуже обмежена. З іншого боку, багато малозабезпечених людей можуть взяти кредит, але з більшим ризиком.
Для розв’язання цих проблем, методи розвідувального аналізу даних можуть поєднувати аналіз часових рядів з іншими підходами, щоб визначити час надання кредитів різним сегментам позичальників, або ж ставку кредитування. Відсотки нараховуються для покриття збитків в межах сегменту портфеля.
#3. Аналіз ризиків
Прогностичні моделі в банківській справі розроблені для оцінки ризиків, пов’язаних з окремими клієнтами. Кредитні рейтинги використовуються для прогнозування поведінки людини та оцінки її кредитоспроможності.
Крім того, аналіз ризиків проводиться в наукових та страхових галузях. Він також широко застосовується у фінансових установах, таких як платіжні системи, для аналізу транзакцій на предмет їх справжності та уникнення шахрайства.
Для цього вони використовують історію транзакцій клієнта. Це особливо актуально для покупок, здійснених кредитною карткою. У випадку раптового зростання обсягу транзакцій клієнта, йому надходить запит для підтвердження того, що транзакцію ініціював саме він. Це допомагає зменшити втрати в таких випадках.
Розвідувальний аналіз даних за допомогою R
Перш за все, для здійснення EDA за допомогою R необхідно завантажити базову R та R Studio (IDE), а потім встановити та завантажити наступні пакети:
#Встановлення пакетів
install.packages("dplyr")
install.packages("ggplot2")
install.packages("magrittr")
install.packages("tsibble")
install.packages("forecast")
install.packages("skimr")
#Завантаження пакетів
library(dplyr)
library(ggplot2)
library(magrittr)
library(tsibble)
library(forecast)
library(skimr)
У цьому посібнику ми будемо використовувати набір економічних даних, вбудований в R, що містить річні дані про економічні показники США. Для спрощення ми змінимо його назву на econ:
econ <- ggplot2::economics
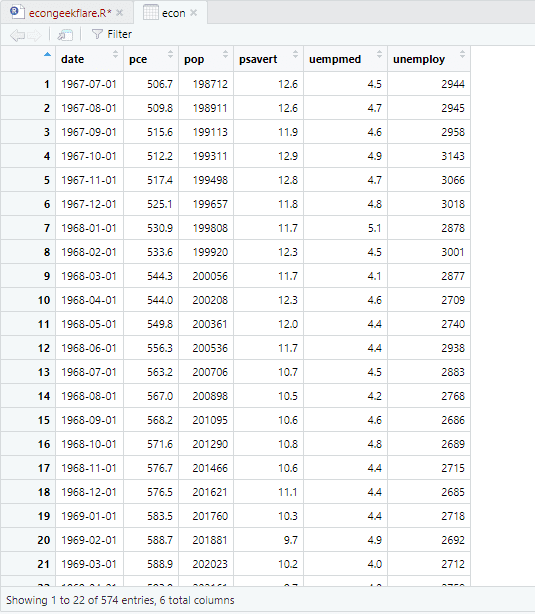
Для здійснення описового аналізу ми використаємо пакет skimr, що обчислює статистичні показники простим та зручним способом:
#Описовий аналіз skimr::skim(econ)

Також можна використовувати функцію summary для описового аналізу:
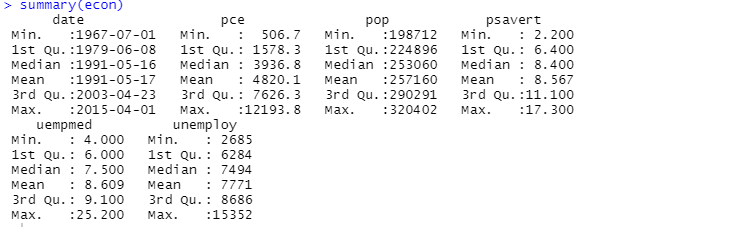
Описовий аналіз показує, що набір даних складається з 547 рядків та 6 стовпців. Мінімальна дата – 1967-07-01, а максимальна – 2015-04-01. Також відображається середнє значення та стандартне відхилення.
Тепер у нас є загальне розуміння набору даних econ. Побудуємо гістограму змінної uempmed для кращого візуального представлення:
#Гістограма безробіття econ %>% ggplot2::ggplot() + ggplot2::aes(x = uempmed) + ggplot2::geom_histogram() + labs(x = "Безробіття", title = "Місячний рівень безробіття в США з 1967 по 2015 роки")
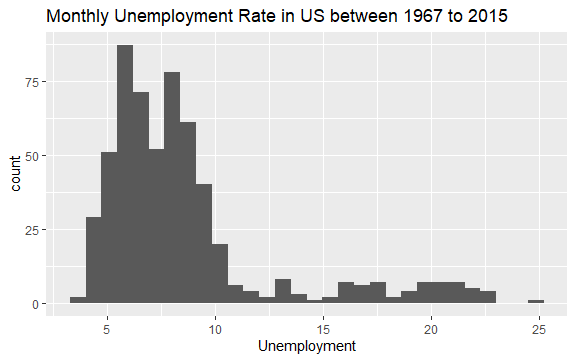
Розподіл гістограми показує, що вона має подовжений хвіст праворуч, тобто, можливо, є кілька спостережень цієї змінної з більш «екстремальними» значеннями. Виникає питання, в який період були зафіксовані ці значення та який тренд змінної?
Найбільш прямий спосіб визначити тренд змінної – це лінійний графік. Нижче ми створюємо лінійний графік та додаємо згладжуючу лінію:
#Лінійний графік безробіття econ %>% ggplot2::autoplot(uempmed) + ggplot2::geom_smooth()
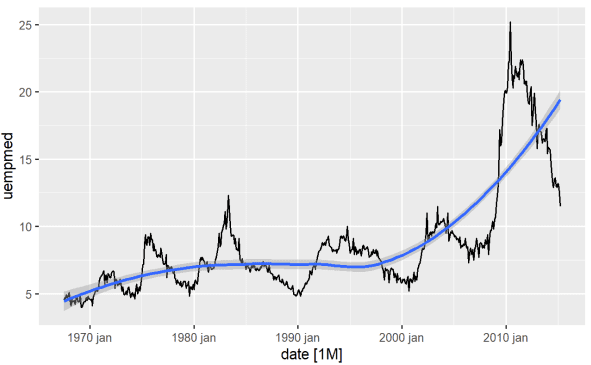
З цього графіка можна побачити, що в останній період, тобто в останніх спостереженнях з 2010 року, існує тенденція зростання безробіття, що перевищує історичний рівень попередніх десятиліть.
Іншим важливим аспектом, особливо в контексті економетричного моделювання, є стаціонарність часового ряду, тобто чи є його середнє значення та дисперсія постійними в часі?
Якщо ці припущення не виконуються, ми говоримо, що ряд має одиничний корінь (нестаціонарний), тому потрясіння, яких зазнає змінна, створюють постійний ефект.
Саме це і сталося з тривалістю безробіття. Ми бачили, що коливання змінної суттєво змінилися, що має серйозні наслідки, пов’язані з економічними теоріями. Але як ми можемо на практиці перевірити стаціонарність змінної?
Пакет forecast має корисну функцію, яка дозволяє застосовувати такі тести, як ADF, KPSS та інші, що вже повертають кількість диференціювань, необхідних для стаціонарності ряду:
#Використання ADF тесту для перевірки стаціонарності forecast::ndiffs( x = econ$uempmed, test = "adf")

Тут p-значення більше 0.05 свідчить про нестаціонарність даних.
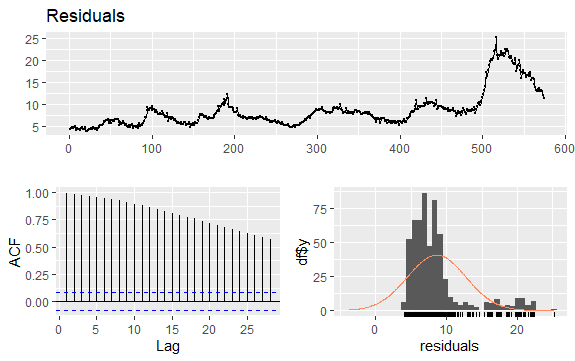
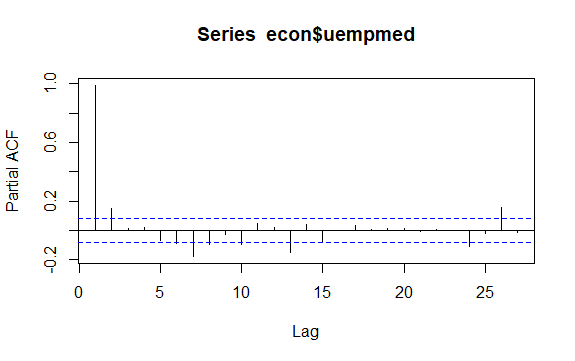
Іншим важливим моментом у аналізі часових рядів є ідентифікація кореляцій (лінійної залежності) між значеннями ряду з відставанням. Корелограми ACF та PACF допомагають у цьому.
Оскільки ряд не має сезонності, але має певну тенденцію, початкові автокореляції, як правило, є великими та позитивними, оскільки спостереження, близькі за часом, також близькі за значенням.
Таким чином, автокореляційна функція (ACF) часового ряду зі схильністю мати позитивні значення, які повільно зменшуються зі збільшенням лагів.
#Залишки безробіття checkresiduals(econ$uempmed) pacf(econ$uempmed)
Висновок
Коли ми маємо у своєму розпорядженні дані, ми часто хочемо одразу перейти до етапу побудови моделей, щоб отримати перші результати. Проте слід протистояти цьому бажанню та розпочати з розвідувального аналізу даних, який є досить простим, але допомагає нам отримати глибоке розуміння даних.
Ви також можете вивчити додаткові ресурси для вивчення статистики для Data Science.