Векторизація в обробці природної мови: Повний огляд методів
У цій статті ми детально розглянемо процес векторизації, важливу техніку в обробці природної мови (NLP), та дослідимо її значущість, надаючи вичерпний огляд різноманітних підходів до векторизації.
Раніше ми обговорювали ключові аспекти попередньої обробки тексту в NLP, зокрема методи очищення тексту. Ми також розглянули фундаментальні принципи NLP, його застосування та різноманітні методи, такі як токенізація, нормалізація, стандартизація та очищення текстової інформації.

Перед тим як перейти до обговорення векторизації, давайте згадаємо, що таке токенізація та чим вона відрізняється від процесу векторизації.
Що таке токенізація?
Токенізація — це процедура розділення речень на менші складові, відомі як токени. Токени спрощують комп’ютерне розуміння та обробку тексту.
Приклад: “Ця стаття цікава.”
Токени: [‘Ця’, ‘стаття’, ‘цікава’, ‘.’]
Що таке векторизація?
Як відомо, моделі та алгоритми машинного навчання оперують числовими даними. Векторизація – це процес конвертації текстових або категоріальних даних у числові вектори. Перетворюючи дані в цифрову форму, ви покращуєте точність навчання вашої моделі.
Навіщо потрібна векторизація?
- Токенізація та векторизація мають різні ролі в NLP. Токенізація ділить речення на менші фрагменти, тоді як векторизація перетворює їх у числові представлення, які можуть розуміти комп’ютери та моделі машинного навчання.
- Векторизація корисна не тільки для представлення даних в числовому форматі, але і для відображення їх семантичного значення.
- Векторизація допомагає зменшити розмірність даних, роблячи їх більш ефективними, що особливо важливо при роботі з великими наборами даних.
- Оскільки багато алгоритмів машинного навчання вимагають числових вхідних даних, зокрема нейронні мережі, векторизація стає необхідною.
У наступних розділах ми розглянемо різноманітні методи векторизації.
“Мішок слів”
Метод “мішка слів” спрощує аналіз великої кількості документів, розглядаючи кожен документ як набір слів.
Цей підхід є ефективним для таких задач як класифікація тексту, аналіз настроїв і пошук інформації.
Припустимо, ви працюєте з великою кількістю тексту. “Мішок слів” допомагає уявити текстові дані, створюючи словник унікальних слів з вашого текстового корпусу. Потім кожне слово кодується як вектор на основі його частоти (кількості появ у тексті).
Ці вектори складаються з невід’ємних цілих чисел (0, 1, 2…), які відображають частоту кожного слова в документі.
Метод “мішка слів” складається з трьох основних етапів:
Етап 1: Токенізація
Розбиття документів на токени.
Наприклад: (Речення: “Я люблю піцу та бургери”)
Етап 2: Створення словника
Створення переліку всіх унікальних слів, що зустрічаються у ваших реченнях.
[“Я”, “люблю”, “піцу”, “та”, “бургери”]
Етап 3: Підрахунок частоти слів та створення вектора
На цьому етапі підраховується, скільки разів кожне слово зі словника з’являється в документі, і результати зберігаються в розрідженій матриці. У цій матриці кожен рядок представляє вектор речення, а його довжина (кількість стовпців) відповідає розміру словника.
Імпорт CountVectorizer
Ми імпортуємо CountVectorizer для навчання нашої моделі “мішок слів”.
from sklearn.feature_extraction.text import CountVectorizerСтворення векторизатора
Створюємо нашу модель, використовуючи CountVectorizer, і навчаємо її на прикладі текстових документів.
# Приклади текстових документів
documents = [
"Це перший документ.",
"Цей документ другий.",
"А це третій.",
"Це перший документ?",
]
# Створення CountVectorizer
cv = CountVectorizer()
# Навчання та перетворення
X = cv.fit_transform(documents)
Перетворення у щільний масив
На цьому кроці ми перетворюємо представлення в щільний масив. Також ми отримуємо назви ознак або слів.
# Отримання назв ознак/слів
feature_names = vectorizer.get_feature_names_out()
# Перетворення в щільний масив
X_dense = X.toarray()
Виведемо матрицю термінів-документів та характерні слова
# Виведення матриці DTM та назв ознак
print("Матриця термінів-документів (DTM):")
print(X_dense)
print("\nНазви ознак:")
print(feature_names)
Матриця термінів-документів (DTM):

Назви ознак:

Як ви бачите, вектори складаються з невід’ємних чисел (0, 1, 2…), що відображають частоту слів у документі.
Ми маємо чотири приклади текстових документів, і ми визначили дев’ять унікальних слів з цих документів. Ми зберегли ці унікальні слова в словнику, присвоївши їм “Назви ознак”.
Потім наша модель “мішок слів” перевіряє наявність першого унікального слова в першому документі. Якщо воно є, воно присвоює значення 1, інакше — 0.
Якщо слово з’являється кілька разів (наприклад, 2 рази), воно присвоює відповідне значення.
Наприклад, у другому документі слово “документ” зустрічається двічі, отже, його значення в матриці буде 2.
Якщо ми хочемо використовувати окреме слово як ознаку – це є представлення уніграм.
n-грами = уніграми, біграми… тощо.
Існує безліч бібліотек, таких як scikit-learn, для реалізації методу “мішка слів”: Keras, Gensim та інші. Цей метод є досить простим і може бути корисним у багатьох ситуаціях.
Хоча “мішок слів” є швидким, він має певні недоліки:
- Він призначає однакову вагу кожному слову, незважаючи на його важливість. У багатьох випадках одні слова є більш важливими, ніж інші.
- BoW просто підраховує частоту слова в документі. Це може призвести до упередження до загальних слів, таких як “the”, “and”, “is” тощо, які можуть не мати значного значення.
- Довші документи можуть мати більше слів і, отже, створювати більші вектори. Це може ускладнити порівняння документів. Метод може створювати розріджену матрицю, що не є оптимальним для складних NLP-проектів.
Для вирішення цих проблем можна використовувати більш досконалі підходи, такі як TF-IDF, який ми розглянемо далі.
TF-IDF
TF-IDF (частота терміна – зворотна частота документа) — це числовий метод, що визначає важливість слів у документі.
Чому TF-IDF кращий за “мішок слів”?
“Мішок слів” розглядає всі слова однаково, враховуючи лише частоту унікальних слів у реченнях. TF-IDF надає вагу словам, враховуючи як частоту, так і їхню унікальність.
Слова, що часто повторюються, не переважають над рідшими, але більш важливими словами.
TF (частота терміна) визначає, наскільки важливе слово в одному реченні.
IDF (зворотна частота документа) визначає, наскільки важливе слово у всій колекції документів.
TF = Частота слова у документі / Загальна кількість слів у документі
DF = Кількість документів, що містять слово w / Загальна кількість документів
IDF = log (Загальна кількість документів / Кількість документів, що містять слово w)
IDF є оберненою величиною DF. Чим частіше слово зустрічається у всіх документах, тим менше його значення у поточному документі.
Остаточний бал TF-IDF: TF-IDF = TF * IDF
Це дозволяє визначити слова, які є типовими для одного документа, але унікальними для всієї колекції. Ці слова можуть бути корисними для виявлення головної теми документа.
Наприклад:
Doc1 = “Я люблю машинне навчання”
Doc2 = “Я люблю techukraine.net”
Знайдемо матрицю TF-IDF для цих документів.
Спочатку створимо словник унікальних слів.
Словник = [“Я”, “люблю”, “машинне”, “навчання”, “techukraine.net”]
Отже, ми маємо 5 слів. Знайдемо TF і IDF для кожного з них.
TF = частота слова в документі / загальна кількість слів у документі
TF:
- Для “Я” = TF для Doc1: 1/4 = 0.25 та для Doc2: 1/3 ≈ 0.33
- Для “люблю”: TF для Doc1: 1/4 = 0.25 та для Doc2: 1/3 ≈ 0.33
- Для “машинне”: TF для Doc1: 1/4 = 0.25 та для Doc2: 0/3 ≈ 0
- Для “навчання”: TF для Doc1: 1/4 = 0.25 та для Doc2: 0/3 ≈ 0
- Для “techukraine.net”: TF для Doc1: 0/4 = 0 та для Doc2: 1/3 ≈ 0.33
Тепер обчислимо IDF.
IDF = log (Загальна кількість документів / Кількість документів, що містять слово w)
IDF:
- Для “Я”: IDF = log(2/2) = 0
- Для “люблю”: IDF = log(2/2) = 0
- Для “машинне”: IDF = log(2/1) = log(2) ≈ 0.69
- Для “навчання”: IDF = log(2/1) = log(2) ≈ 0.69
- Для “techukraine.net”: IDF = log(2/1) = log(2) ≈ 0.69
Тепер обчислимо остаточні бали TF-IDF:
- Для “Я”: TF-IDF для Doc1: 0.25 * 0 = 0 і TF-IDF для Doc2: 0.33 * 0 = 0
- Для “люблю”: TF-IDF для Doc1: 0.25 * 0 = 0 і TF-IDF для Doc2: 0.33 * 0 = 0
- Для “машинне”: TF-IDF для Doc1: 0.25 * 0.69 ≈ 0.17 і TF-IDF для Doc2: 0 * 0.69 = 0
- Для “навчання”: TF-IDF для Doc1: 0.25 * 0.69 ≈ 0.17 і TF-IDF для Doc2: 0 * 0.69 = 0
- Для “techukraine.net”: TF-IDF для Doc1: 0 * 0.69 = 0 і TF-IDF для Doc2: 0.33 * 0.69 ≈ 0.23
Матриця TF-IDF виглядає так:
I love machine learning techukraine.net
Doc1 0.0 0.0 0.17 0.17 0.0
Doc2 0.0 0.0 0.0 0.0 0.23
Значення в матриці TF-IDF показують важливість кожного слова в кожному документі. Високі значення вказують на те, що термін важливий для конкретного документа, а низькі значення свідчать про меншу важливість або розповсюдженість терміна в цьому контексті.
TF-IDF найчастіше використовується для класифікації тексту, пошуку інформації, створення чат-ботів і підсумовування тексту.
Імпорт TfidfVectorizer
Імпортуємо TfidfVectorizer з sklearn.
from sklearn.feature_extraction.text import TfidfVectorizerСтворення векторизатора
Створюємо нашу модель Tf Idf за допомогою TfidfVectorizer.
# Приклади текстових документів
text = [
"Це перший документ.",
"Цей документ другий.",
"А це третій.",
"Це перший документ?",
]
# Створення TfidfVectorizer
cv = TfidfVectorizer()
Створення матриці TF-IDF
Навчаємо нашу модель, передаючи їй текст. Після цього перетворюємо матрицю в щільний масив.
# Навчання та перетворення для створення матриці TF-IDF
X = cv.fit_transform(text)
# Отримання назв ознак/слів feature_names = vectorizer.get_feature_names_out() # Перетворення матриці TF-IDF в щільний масив для зручності обробки (за бажанням) X_dense = X.toarray()
Виведемо матрицю TF-IDF та характерні слова
# Виведення матриці TF-IDF та назв ознак
print("Матриця TF-IDF:")
print(X_dense)
print("\nНазви ознак:")
print(feature_names)
Матриця TF-IDF:
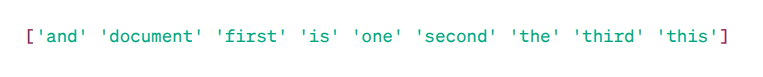
Як ви бачите, ці десяткові числа показують важливість слів у певних документах.
Також можна об’єднувати слова в групи по 2, 3, 4 і т.д. за допомогою n-грам.
Існують й інші параметри, які ми можемо використовувати: min_df, max_feature, subliner_tf та інші.
До цього моменту ми досліджували основні методи, що базуються на частоті слів.
Проте TF-IDF не завжди здатний забезпечити семантичне значення та контекстне розуміння тексту.
Давайте перейдемо до більш складних методів, що змінили світ вкладень слів і є більш ефективними для відображення семантичного значення та контексту.
Word2Vec
Word2vec є популярною технікою вкладення слів в NLP, що дозволяє фіксувати семантичну та синтаксичну подібність. Розроблений Томасом Міколовим та його командою з Google у 2013 році, word2vec представляє слова як неперервні вектори в багатовимірному просторі.
Мета word2vec – представляти слова так, щоб відобразити їх семантичне значення. Вектори, створені word2vec, розташовані в неперервному векторному просторі.
Наприклад, вектори “кіт” і “собака” будуть ближчими один до одного, ніж вектори “кіт” і “дівчина”.
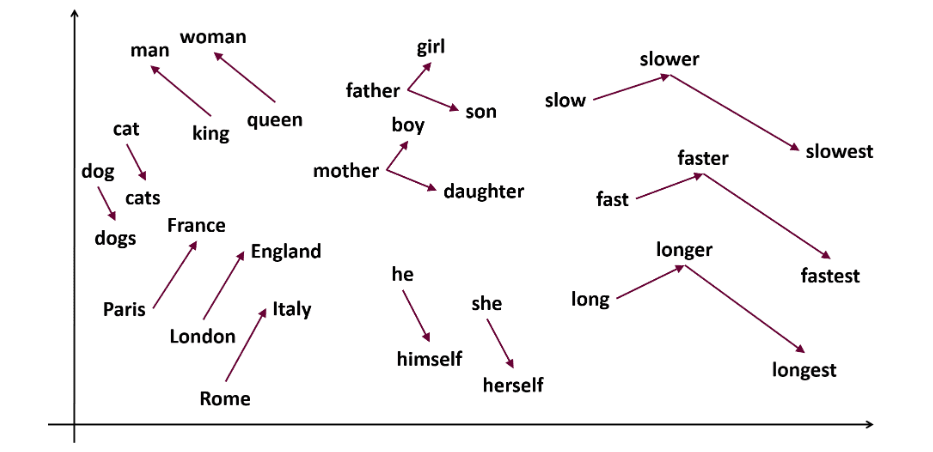
Джерело: usna.edu
Word2vec може використовувати дві різні архітектури моделі для створення вкладень слів.
CBOW (Continuous bag of words) намагається передбачити цільове слово, усереднюючи значення навколишніх слів. Він використовує фіксовану кількість або вікно слів навколо цільового слова, перетворює їх у числову форму (вкладення), усереднює їх і використовує це середнє значення для передбачення цільового слова за допомогою нейронної мережі.
Приклад: “Лисиця” (цільове слово)
Слова речення: “The”, “quick”, “brown”, “jumps”, “over”, “the”
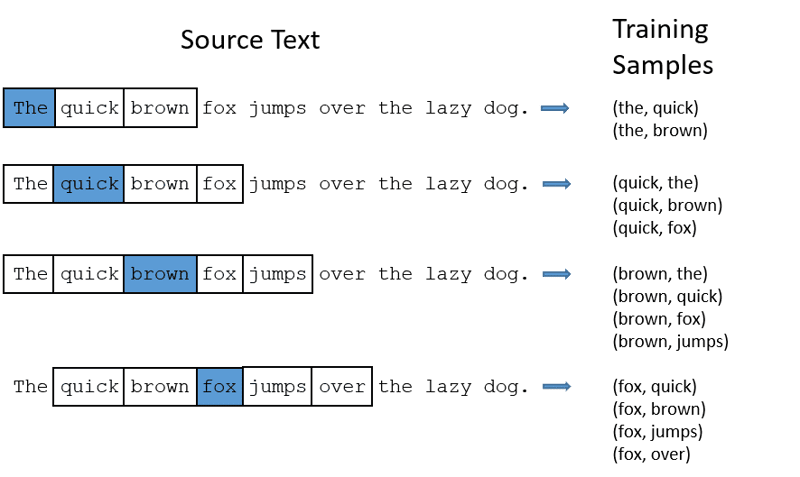
- CBOW використовує вікно фіксованого розміру (кількості) слів, наприклад 2 (2 зліва та 2 справа).
- Перетворення слів у вкладення.
- CBOW усереднює вкладення слів.
- CBOW усереднює вкладення контекстних слів.
- Усереднений вектор використовується для передбачення цільового слова за допомогою нейронної мережі.
Давайте розглянемо, чим skip-gram відрізняється від CBOW.
Skip-gram – це модель вкладення слів, що працює інакше. Замість передбачення цільового слова skip-gram прогнозує контекстні слова на основі заданого цільового слова.
Skip-gram краще виявляє семантичні зв’язки між словами.
Наприклад: “король – чоловіки + жінки = королева”
Для роботи з Word2Vec є два варіанти: навчити власну модель або використовувати попередньо навчену. Ми скористаємося попередньо навченою моделлю.
Імпорт gensim
Gensim встановлюється командою pip install:
pip install gensimТокенізація речень за допомогою word_tokenize:
Спершу ми перетворимо речення в нижній регістр. Потім ми токенізуємо їх за допомогою word_tokenize.
# Імпорт необхідних бібліотек
from gensim.models import Word2Vec
from nltk.tokenize import word_tokenize
# Приклади речень
sentences = [
"Я люблю Тора",
"Халк - важливий член Месників",
"Залізна Людина допомагає Людині-павуку",
"Людина-павук є одним з популярних членів Месників",
]
# Токенізація речень
tokenized_sentences = [word_tokenize(sentence.lower()) for sentence in sentences]
Навчання нашої моделі:
Ми навчимо нашу модель, передавши їй токенізовані речення. Використовуємо вікно розміром 5, але ви можете налаштувати його відповідно до ваших потреб.
# Навчання моделі Word2Vec
model = Word2Vec(sentences=tokenized_sentences, vector_size=100, window=5, min_count=1, sg=0)
# Пошук схожих слів
similar_words = model.wv.most_similar("avengers")
# Виведення схожих слів
print("Слова, схожі на 'месники':")
for word, score in similar_words:
print(f"{word}: {score}")
Слова, схожі на “месники”:

Це слова, схожі на “месники” на основі моделі Word2Vec, разом з їхніми оцінками подібності.
Модель обчислює оцінку подібності (здебільшого косинусну подібність) між вектором слова “месники” та векторами інших слів зі словника. Оцінка подібності показує, наскільки тісно пов’язані два слова у векторному просторі.
Наприклад:
Тут слово “допомагає” має косинус подібності -0.005911458611011982 зі словом “месники”. Від’ємне значення вказує на те, що ці слова можуть бути не схожими одне на одного.
Значення подібності косинуса коливаються від -1 до 1, де:
- 1 означає, що два вектори ідентичні та мають позитивну подібність.
- Значення, близькі до 1, вказують на високу позитивну подібність.
- Значення, близькі до 0, вказують на те, що вектори не сильно пов’язані.
- Значення, близькі до -1, вказують на високу несхожість.
- -1 вказує на те, що два вектори абсолютно протилежні та мають ідеальну негативну подібність.
Перейдіть за цим посиланням, якщо бажаєте краще зрозуміти моделі word2vec та візуальне представлення того, як вони працюють. Це чудовий інструмент для спостереження за CBOW та skip-gram у дії.
Подібно до Word2Vec, існує GloVe. GloVe може створювати вбудовування, які потребують менше пам’яті порівняно з Word2Vec. Давайте розглянемо GloVe докладніше.
GloVe
Глобальні вектори для представлення слів (GloVe) — це метод, подібний до word2vec. Він використовується для представлення слів як векторів у неперервному просторі. Концепція GloVe збігається з Word2Vec: створення контекстних вкладень слів, враховуючи високу продуктивність Word2Vec.
Навіщо потрібен GloVe?
Word2vec – це віконний метод, який використовує навколишні слова для розуміння слів. Це означає, що семантичне значення цільового слова залежить лише від сусідніх слів, що є неефективним використанням статистики.
У той час як GloVe фіксує як глобальну, так і локальну статистику з додаванням слів.
Коли використовувати GloVe?
Використовуйте GloVe, коли вам потрібно вкладення слів, яке фіксує ширші семантичні зв’язки та глобальні асоціації між словами.
GloVe є кращим за інші моделі у таких задачах як розпізнавання іменованих об’єктів, аналогії слів і схожості слів.
Для початку необхідно встановити Gensim:
pip install gensimЕтап 1: Встановлення необхідних бібліотек
# Імпорт необхідних бібліотек import numpy as np import matplotlib.pyplot as plt from sklearn.manifold import TSNE import gensim.downloader as api
Етап 2: Імпорт моделі GloVe
import gensim.downloader as api
glove_model = api.load('glove-wiki-gigaword-300')
Етап 3: Отримання векторного представлення слова “милий”
glove_model["cute"]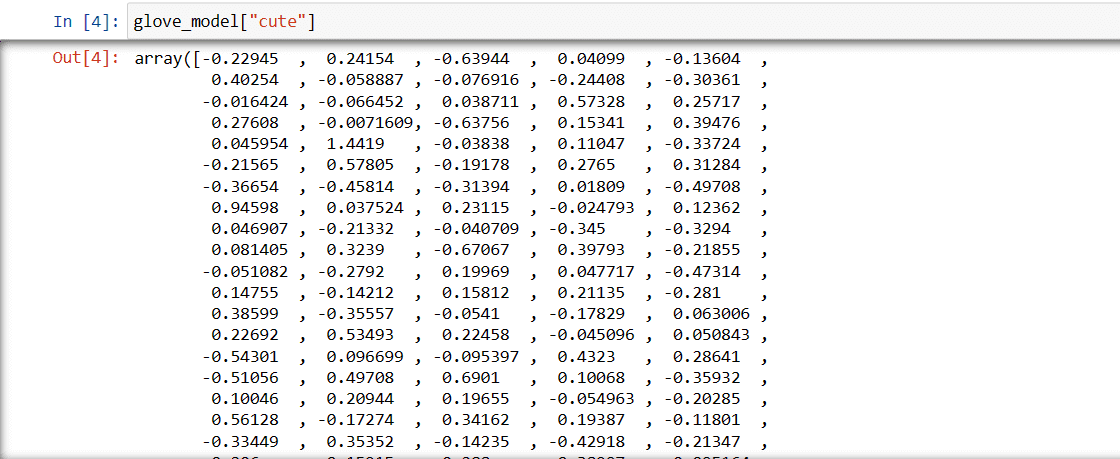
Ці значення відображають значення слова та його зв’язки з іншими словами. Позитивні значення свідчать про позитивні асоціації з певними поняттями, тоді як негативні значення вказують на негативні асоціації з іншими поняттями.
У моделі GloVe кожен вимір у векторі слова відображає певний аспект значення або контексту слова.
Негативні та позитивні значення в цих вимірах впливають на те, наскільки “милий” семантично пов’язаний з іншими словами у словнику моделі.
Значення можуть відрізнятися для різних моделей. Давайте знайдемо слова, схожі на “хлопець”.
Топ-10 схожих слів, які модель вважає найбільш схожими на “хлопець”:
glove_model.most_similar("boy")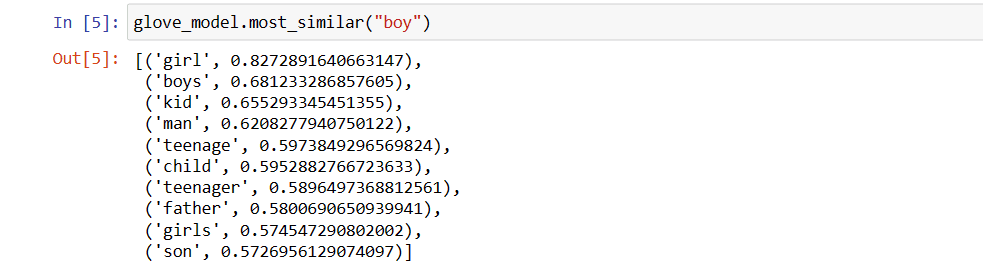
Як бачите, слово “хлопчик” найбільш схоже на слово “дівчинка”.
Тепер ми спробуємо визначити, наскільки точно модель розпізнає семантичне значення поданих слів.
glove_model.most_similar(positive=['boy', 'queen'], negative=['girl'], topn=1)
Наша модель здатна знаходити ідеальний зв’язок між словами.
Визначення переліку слів:
Тепер спробуємо зрозуміти семантичне значення або зв’язок між словами, візуалізувавши їх. Визначимо перелік слів, які ми хочемо візуалізувати.
# Визначення переліку слів для візуалізації vocab = ["boy", "girl", "man", "woman", "king", "queen", "banana", "apple", "mango", "cow", "coconut", "orange", "cat", "dog"]
Створення матриці вбудовування:
Напишемо код для створення матриці вбудовування.
# Код для створення матриці вбудовування
EMBEDDING_DIM = glove_model.vectors.shape[1]
word_index = {word: index for index, word in enumerate(vocab)}
num_words = len(vocab)
embedding_matrix = np.zeros((num_words, EMBEDDING_DIM))
for word, i in word_index.items():
embedding_vector = glove_model[word]
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
Визначення функції для візуалізації t