План аварійного відновлення: Ключові терміни та стратегії
Для будь-якої організації, особливо в сучасному цифровому світі, план аварійного відновлення (ПВВ) є не просто бажаною, а необхідною умовою. Це своєрідний «запасний план», що вступає в дію в момент виникнення непередбачуваної ситуації.
В ІТ-сфері ПВВ є формалізованим документом, в якому чітко прописані всі кроки, дії та процедури, необхідні для мінімізації наслідків катастроф різного характеру. Катастрофа може виникнути раптово, незалежно від підготовки, створюючи труднощі для організацій та окремих осіб, впливаючи на фінанси та клієнтський досвід.
Добре розроблений та ефективний план аварійного відновлення дозволяє не тільки мінімізувати наслідки атаки, але й швидко відновити нормальну роботу. Це зменшує фінансові втрати, скорочує час простою та зберігає позитивний досвід користувача. Підготовка до відновлення вимагає готовності планів, ресурсів, персоналу, систем і стратегій.
У цій статті ми детально розглянемо ключові аспекти аварійного відновлення, а також важливу термінологію, що допоможе вам впевнено протистояти будь-яким викликам і вийти з них сильнішими.
Що таке катастрофа?
Катастрофа – це несподівана подія, яка може трапитися будь-де, включаючи ІТ-сектор. Це може бути природна подія або ж наслідок людських дій, що перешкоджає нормальній роботі компанії та порушує її інфраструктуру.
Такі події впливають на організацію, її клієнтів, постачальників, працівників та партнерів, створюючи тиск у фінансовій сфері, погіршуючи репутацію, підриваючи довіру клієнтів та послаблюючи рівень безпеки.
Саме тому важливо заздалегідь підготуватися до подолання таких ситуацій. Це вимагає миттєвого відновлення всіх операцій та даних. Простіше кажучи, ваша організація має бути готова повернутися до нормальної роботи за мінімальний час.
Катастрофи можуть бути різноманітними: кібератаки, диверсії, терористичні акти, програми-вимагачі, фізичні загрози, урагани, землетруси, пожежі, повені, промислові аварії, збої в електропостачанні тощо.
Що таке аварійне відновлення?

Аварійне відновлення (АВ) – це комплекс заходів, спрямованих на відновлення звичного режиму роботи після катастрофи. Це передбачає відновлення доступу до апаратного забезпечення, програмного забезпечення, обладнання, з’єднань, мережі, електропостачання та даних. Для підготовки до катастроф потрібні чіткі правила та процедури, закріплені в документально оформлених процесах.
У випадку, якщо об’єкти вашої організації зазнали руйнувань, вам доведеться налагодити додаткові види діяльності, такі як зв’язок, транспорт, пошук джерел та робочих місць.
Чому план аварійного відновлення такий важливий?
Створення ефективного плану відновлення після катастрофи є критичним завданням для будь-якої організації в ІТ-сфері. Важливо переконатися, що у вас є кваліфікований персонал та необхідні інструменти для реалізації цього плану.
Розглянемо детальніше важливість плану аварійного відновлення:
Обмеження збитків
Катастрофи є непередбачуваними. Ніхто не може точно сказати, коли саме вони трапляться. Проте, підготувавшись заздалегідь, ви можете контролювати збитки, завдані вашій інфраструктурі.
Наприклад, у районах, де можливі повені, можна розмістити важливі документи та обладнання на верхніх поверхах, щоб уникнути їх пошкодження.
Так само необхідно створювати резервні копії важливих даних для захисту від кібератак, які можуть призвести до їх пошкодження або викрадення.
Відновлення послуг
За наявності надійного плану відновлення, всі служби можна швидко та легко повернути до нормального стану. Це означає, що ви зможете за короткий час відновити практично всі основні активи та послуги.
Мінімізація переривань
Неможливо передбачити, що відбудеться завтра або на наступному етапі роботи. Проте, маючи ефективний план відновлення, вам не доведеться сильно турбуватися про наслідки. Ваша інфраструктура зможе працювати з мінімальними перервами.
Навчання та підготовка

В ІТ-інфраструктурі працює велика кількість співробітників. Усі вони повинні знати про процес відновлення, щоб у випадку надзвичайної ситуації оперативно діяти.
Правильна підготовка знизить рівень стресу для всіх, хто працює у вашій організації. Крім цього, ви зможете навчити своїх працівників, як діяти в разі несподіваної події.
Далі розглянемо ключові терміни, які допоможуть вам глибше зрозуміти аварійне відновлення.
RTO
Цільовий час відновлення (RTO) – це час, за який організація повинна відновити свою роботу після катастрофи, не зазнаючи значних фінансових втрат.
При визначенні RTO, компанія повинна проаналізувати можливі простої та їх вплив на різні аспекти її діяльності. Цей показник використовується для розробки стратегій, що дозволяють продовжити бізнес-операції навіть після катастрофи. Коли клієнти зіштовхуються з проблемами у роботі програм, вони хочуть знати, як швидко програма відновиться. Відповіддю на це питання є RTO.
Наприклад, якщо ви компанія, що займається онлайн-транзакціями (наприклад, PayPal), ваш RTO повинен бути достатньо швидким для відновлення операцій. Компанії встановлюють RTO на рівні однієї або двох годин, щоб уникнути значних фінансових втрат або втрати даних.
RPO
Цільові точки відновлення (RPO) – це обсяг даних, який може бути втрачений у результаті катастрофи.
Для прикладу візьмемо базу даних банку, яка фіксує транзакції, такі як перекази, платежі тощо. Якщо трапляється катастрофа, база даних відновлюється в реальному часі. Різниця між станом бази даних на момент аварії та після відновлення буде дорівнювати нулю.
Деякі компанії можуть дозволити собі витратити 24 години на відновлення інформації з резервної копії. Проте, в інших випадках, це може мати катастрофічні наслідки. Важливо налаштувати свою інфраструктуру відповідно до вимог RPO. Це включає збільшення частоти резервного копіювання та створення резервної бази даних.
Перехід після відмови
Пригадайте ситуацію, коли під час далекої подорожі у вас спустило колесо. Ви радієте, що маєте в машині запасне колесо та інструменти.
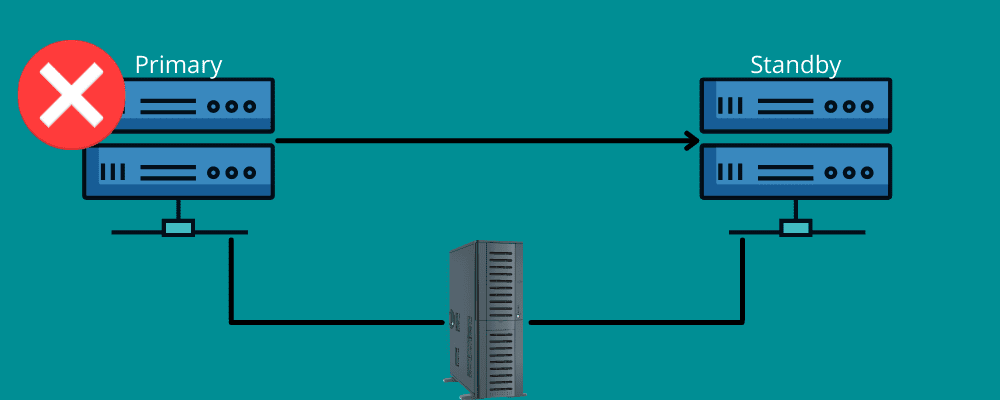
Перехід після відмови працює за тим же принципом.
Це означає, що на випадок катастрофи вам потрібне резервне з’єднання. Коротко кажучи, відновлення після збою передбачає наявність мереж та систем, які використовуються під час аварії для переміщення даних у систему відновлення.
Відмовостійкість забезпечує безперебійну роботу всіх ваших служб, навіть у разі виникнення проблем з інфраструктурою або апаратним забезпеченням. Це дозволяє запобігти втраті даних та прибутку, а також забезпечує безперебійну роботу для кінцевих користувачів.
Ви можете налаштувати його вручну або дозволити йому працювати автоматично, щоб перемістити дані на резервний сервер.
Відновлення після відмови
Відновлення після відмови – це процес повернення виробничих потужностей на своє вихідне місце після усунення аварії. Під час атаки, компанії виконують операцію переходу після відмови, переміщуючи усі робочі навантаження на репліку віртуальної машини або резервної системи.
Однак, не можна пропустити наступний крок — відновлення. Коли все буде відновлено та повернено в робочий стан, вам необхідно перенести усі робочі навантаження на вихідні віртуальні машини або системи. Цей процес переміщення робочих навантажень на вихідне місце називається відновленням після відмови. Іншими словами, це «повернення» після атаки.
Відновлення після відмови також використовується для планового технічного обслуговування підприємства. Відновлення після збою – це перший крок, а відновлення – другий. Відновлення можна налаштувати між хмарою та хмарою, локально та локально, локально та хмару, або будь-яку іншу комбінацію.
DR
Аварійне відновлення (DR) – це процес, у якому ви маєте заздалегідь підготовлені плани щодо відновлення ваших активів у визначений час.
DR дозволяє організації швидко реагувати та відновлювати кожну послугу після несподіваної події. Він містить офіційну документацію з інструкціями щодо дій у разі непередбачених інцидентів.
BCP
План безперервності бізнесу (BCP) – це план, який допомагає ІТ-інфраструктурі розробити стратегії для усунення збоїв у роботі серверів, мобільних пристроїв, комп’ютерів та мереж.
BCP дещо відрізняється від аварійного відновлення, оскільки допомагає організації розробити стратегії для відновлення корпоративного програмного забезпечення та продуктивності з метою задоволення ключових бізнес-потреб.
BCP передбачає створення системи відновлення для подолання потенційних загроз, таких як кібератаки чи стихійні лиха. Він призначений для захисту активів та забезпечення швидкого відновлення усіх служб після атаки.
BCM

Управління безперервністю бізнесу (BCM) – це процес управління ризиками, що розроблений для захисту від загроз бізнес-процесам. BCM є наступним кроком після BCP, де перевіряються плани відновлення, щоб переконатися, що всі працівники оперативно реагують на план та відновлюють усі важливі елементи.
BCM діє як структура управління, яка дозволяє виявляти ризики інфраструктури при зовнішніх та/або внутрішніх загрозах. Регулярні тестування забезпечують ефективну роботу, підвищують передбачуваність, зменшують ризики та допомагають планувати дії на випадок майбутніх атак.
BIA
Аналіз впливу на бізнес (BIA) – це процес аналізу рівня виживання бізнесу шляхом визначення важливих систем, операцій та процесів. Він виявляє вплив катастрофи на організацію через перерву в роботі.
BIA дозволяє прогнозувати наслідки ще до настання події, що допомагає зібрати інформацію для створення ефективних стратегій відновлення. Також BIA визначає витрати, пов’язані зі збоями, такі як вартість заміни обладнання, втрата прибутку, зарплати тощо.
Створюючи звіт BIA, необхідно враховувати ключові процеси, вплив збоїв на різні сфери, допустиму тривалість перерв, фінансові витрати тощо.
Дерево дзвінків
Дерево дзвінків – це список персоналу, якого необхідно оповістити у разі надзвичайної ситуації. Ця процедура має деревоподібну структуру.
Наприклад, під час катастрофи, одна особа зв’язується з невеликою групою членів команди з терміновим повідомленням. Ці члени, в свою чергу, телефонують кожній групі окремо. Таким чином, весь персонал буде проінформований та зможе вчасно розпочати роботу по відновленню процесів.
Створення списку – це проста справа, проте, реалізація його в реальному часі може спричинити плутанину.
Регулярні дзвінки допоможуть підготувати кожного працівника до екстреної ситуації. Тестування виявить змінені або відсутні номери телефонів, що може негативно вплинути на продуктивність.
Дерево дзвінків використовується для доставки інструкцій під час екстреної ситуації. Хоча це можна робити вручну, сьогодні автоматизація дозволяє пришвидшити цей процес та сповістити всіх учасників у цифровому середовищі.
Командний центр/Центр управління
Це віртуальний або фізичний об’єкт, призначений для управління планами відновлення під час кризи. Він підтримує зв’язок з командою для управління системами та функціями під час катастрофи.
Раніше інфраструктура залежала від командного центру, що реагував на кризи без чіткого плану. Сьогодні організації розробляють свої центри управління, що дозволяє перетворити негайну реакцію на ключову компетенцію.
При виникненні катастрофи командний центр швидко переходить до фази відновлення. Він також є пунктом звітності для служб, преси, доставки тощо. Командний центр об’єднує фахівців з різних дисциплін у надзвичайних ситуаціях.
Реагування на інцидент

Реагування на інцидент – це дії, спрямовані на боротьбу з атакою. Воно здійснюється за допомогою чітких процедур та кваліфікованого персоналу для ефективного збереження безпеки мережі та даних.
Якщо організація має план реагування на інциденти, вона зможе захистити свої дані від загроз у реальному часі. Фахівці з реагування на інциденти завжди уважні до проблем та діють за визначеним планом. Вони вживають необхідних заходів для уникнення порушень безпеки, гарантуючи, що під час аварійного відновлення не буде пропущено жодного важливого кроку.
Спочатку необхідно визначити критичні дані та зберегти їх у хмарі або будь-якому іншому віддаленому місці. Важливо регулярно оновлювати плани реагування на інциденти.
Резервне копіювання
Рішення для резервного копіювання дозволяють ІТ-інфраструктурі зберігати копії даних у безпечному місці. Якщо ви зіштовхнулися з пошкодженням бази даних, випадковим видаленням даних або іншою проблемою, ви повинні мати резервні копії для миттєвого відновлення даних та продовження роботи.

Резервне копіювання передбачає реплікацію файлів та їх збереження у безпечному місці. Для забезпечення можливості відновлення даних навіть у випадку збою одного сайту, необхідно створювати резервні копії у кількох місцях.
Стійкість
Здатність спільнот, урядів, організацій та окремих осіб протистояти катастрофі без шкоди для послуг та систем називається стійкістю до катастрофи.
Організація повинна бути готовою витримати стрес через небезпеки. Забезпечте можливості для мінімізації втрат за допомогою планування, замість очікування допомоги. Це допоможе вам ефективно впоратися з катастрофами та відновити ІТ-інфраструктуру.
Головна мета полягає в збереженні та відновленні основних функцій у потрібний час. Щоб стати стійкою до катастроф організацією, необхідно заздалегідь підготуватися, мати здатність передбачати ризики, адаптуватися до змін, ділитися досвідом, співпрацювати з різними секторами та управляти рівнями ризику.
SLA

Угода про рівень обслуговування (SLA) – це план дій у разі катастрофи, де кінцеві користувачі інформуються про час, потрібний для відновлення послуг під час надзвичайної ситуації.
SLA гарантує клієнтам, що їхні дані знаходяться в безпеці. Це єдиний канал зв’язку з кінцевими користувачами.
Кожна ІТ-інфраструктура гарантує своїм клієнтам виконання SLA. Тому переконайтеся, що ви заздалегідь спілкуєтесь з кінцевими користувачами.
SPOF
Єдина точка відмови (SPOF) – це частина обладнання, окрема особа, ресурс або програма, до якої підключено багато інших систем.
У випадку виходу з ладу такого елемента, усі інші важливі частини, підключені до цієї системи, також перестають працювати. Це впливає на весь процес та бізнес-операцію.
Тому важливо мати стратегію для вирішення такої проблеми. Перше, що можна зробити – це визначити елемент, який може мати найбільший вплив на роботу. Далі потрібно запустити аналіз впливу на бізнес та оцінку ризиків. Важливо виявити SPOF до того, як відбудеться інцидент.
Перерахувавши усі SPOF, необхідно класифікувати їх відповідно до процесу відновлення:
- Елементи, які легко та швидко відновлюються з невеликими витратами.
- Елементи, відновлення яких буде складним, проте, можна розробити надійний процес відновлення.
- Елементи, які неможливо відновити після виходу з ладу.
Дії повинні базуватися на цій класифікації.
Відновлення системи
Під час збою апаратного забезпечення, необхідно запустити процес відновлення системи або сервера до його початкового стану. Для цього вам потрібно підготувати вимоги до відновлення, резервні копії, сумісність вбудованого програмного забезпечення та апаратного забезпечення.
Відновлення системи – це процес повернення машини до її попередніх налаштувань або стану, в якому вона була під час створення. Це дозволяє знищити вірусні інфекції та шкідливе програмне забезпечення.
Цей процес включає планування відновлення ІТ-інфраструктури, що передбачає дотримання певних процедур для забезпечення доступності даних у разі збоїв.
Відновлення системи
Відновлення системи – це інструмент, що дозволяє відновити певні файли та інформацію до попереднього стану.
З його допомогою можна відновити ключі реєстру, встановлені програми, драйвери, системні файли тощо. Це ефективний інструмент у багатьох ситуаціях.
План тестування
План тестування – це документ, в якому зберігається інформація про стратегію тестування, оцінки, ресурси, терміни, цілі та графіки. Він використовується для тестування безпеки апаратного та програмного забезпечення.
План включає різні тести, що відповідають процедурам та крокам, розробленим для управління наслідками катастрофи. Регулярне тестування допоможе підготувати вас та вашу організацію до дій під час кризових ситуацій. Це дозволить виявити недоліки та бути готовими до боротьби з ними.
Висновок
Ніхто не знає, коли саме станеться катастрофа. Тому належні заходи безпеки є важливими для кожного підприємства.
Термінологія аварійного відновлення допоможе вам зрозуміти, як реагувати на атаки та катастрофи. Це також допоможе вам підготуватися заздалегідь, щоб захистити свою інфраструктуру під час несподіваної події. Ви зможете створити ефективну стратегію аварійного відновлення, що допоможе вам заощадити кошти та зберегти довіру клієнтів.